English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
¡Ayuda a traducir esta guía!
El Manual de Diseño de Sistemas

Motivación
Aprende cómo diseñar sistemas a gran escala.>
Prepárate para la entrevista de diseño de sistemas.
Aprende cómo diseñar sistemas a gran escala
Aprender a diseñar sistemas escalables te ayudará a convertirte en un mejor ingeniero.
El diseño de sistemas es un tema amplio. Hay una gran cantidad de recursos dispersos por la web sobre principios de diseño de sistemas.
Este repositorio es una colección organizada de recursos para ayudarte a aprender cómo construir sistemas a escala.
Aprende de la comunidad de código abierto
Este es un proyecto de código abierto, actualizado continuamente.
¡Contribuciones son bienvenidas!
Prepárate para la entrevista de diseño de sistemas
Además de las entrevistas de programación, el diseño de sistemas es un componente requerido del proceso técnico de entrevistas en muchas empresas tecnológicas.
Practica preguntas comunes de entrevistas de diseño de sistemas y compara tus resultados con soluciones de ejemplo: discusiones, código y diagramas.
Temas adicionales para la preparación de entrevistas:
- Guía de estudio
- Cómo abordar una pregunta de entrevista de diseño de sistemas
- Preguntas de entrevista sobre diseño de sistemas, con soluciones
- Preguntas de entrevista sobre diseño orientado a objetos, con soluciones
- Preguntas adicionales de entrevista sobre diseño de sistemas
Tarjetas Anki
Los mazos de tarjetas Anki proporcionados usan repetición espaciada para ayudarte a retener conceptos clave de diseño de sistemas.
- Mazo de diseño de sistemas
- Mazo de ejercicios de diseño de sistemas
- Mazo de ejercicios de diseño orientado a objetos
Recurso de codificación: Desafíos de codificación interactivos
¿Buscas recursos para ayudarte a prepararte para la Entrevista de codificación?
Consulta el repositorio hermano Desafíos de codificación interactivos, que contiene un mazo adicional de Anki:
Contribuciones
Aprende de la comunidad.
No dudes en enviar pull requests para ayudar a:
- Corregir errores
- Mejorar secciones
- Añadir nuevas secciones
- Traducir
Revise las Pautas para contribuir.
Índice de temas de diseño de sistemas
Resúmenes de varios temas de diseño de sistemas, incluyendo pros y contras. Todo es un compromiso.
Cada sección contiene enlaces a recursos más profundos.
- Temas de diseño de sistemas: empezar aquí
- Paso 1: Revisar la conferencia en video sobre escalabilidad
- Paso 2: Revisar el artículo sobre escalabilidad
- Próximos pasos
- Rendimiento vs escalabilidad
- Latencia vs rendimiento
- Disponibilidad vs consistencia
- Teorema CAP
- CP - consistencia y tolerancia a particiones
- AP - disponibilidad y tolerancia a particiones
- Patrones de consistencia
- Consistencia débil
- Consistencia eventual
- Consistencia fuerte
- Patrones de disponibilidad
- Conmutación por error
- Replicación
- Disponibilidad en números
- Sistema de nombres de dominio
- Red de entrega de contenido
- CDNs push
- CDNs pull
- Balanceador de carga
- Activo-pasivo
- Activo-activo
- Balanceo de carga en capa 4
- Balanceo de carga en capa 7
- Escalado horizontal
- Proxy inverso (servidor web)
- Balanceador de carga vs proxy inverso
- Capa de aplicación
- Microservicios
- Descubrimiento de servicios
- Base de datos
- Sistema de gestión de bases de datos relacionales (RDBMS)
- Replicación maestro-esclavo
- Replicación maestro-maestro
- Federación
- Fragmentación (Sharding)
- Desnormalización
- Optimización de SQL
- NoSQL
- Almacén clave-valor
- Almacén de documentos
- Almacén de columnas anchas
- Base de datos de grafos
- SQL o NoSQL
- Caché
- Caché del cliente
- Caché de CDN
- Caché del servidor web
- Caché de la base de datos
- Caché de la aplicación
- Caché a nivel de consulta de base de datos
- Caché a nivel de objeto
- Cuándo actualizar la caché
- Cache-aside
- Write-through
- Write-behind (escritura diferida)
- Refresh-ahead
- Asincronismo
- Colas de mensajes
- Colas de tareas
- Presión de retorno
- Comunicación
- Protocolo de control de transmisión (TCP)
- Protocolo de datagramas de usuario (UDP)
- Llamada a procedimiento remoto (RPC)
- Transferencia de estado representacional (REST)
- Seguridad
- Apéndice
- Tabla de potencias de dos
- Números de latencia que todo programador debería conocer
- Preguntas adicionales para entrevistas de diseño de sistemas
- Arquitecturas del mundo real
- Arquitecturas de empresas
- Blogs de ingeniería de empresas
- En desarrollo
- Créditos
- Información de contacto
- Licencia
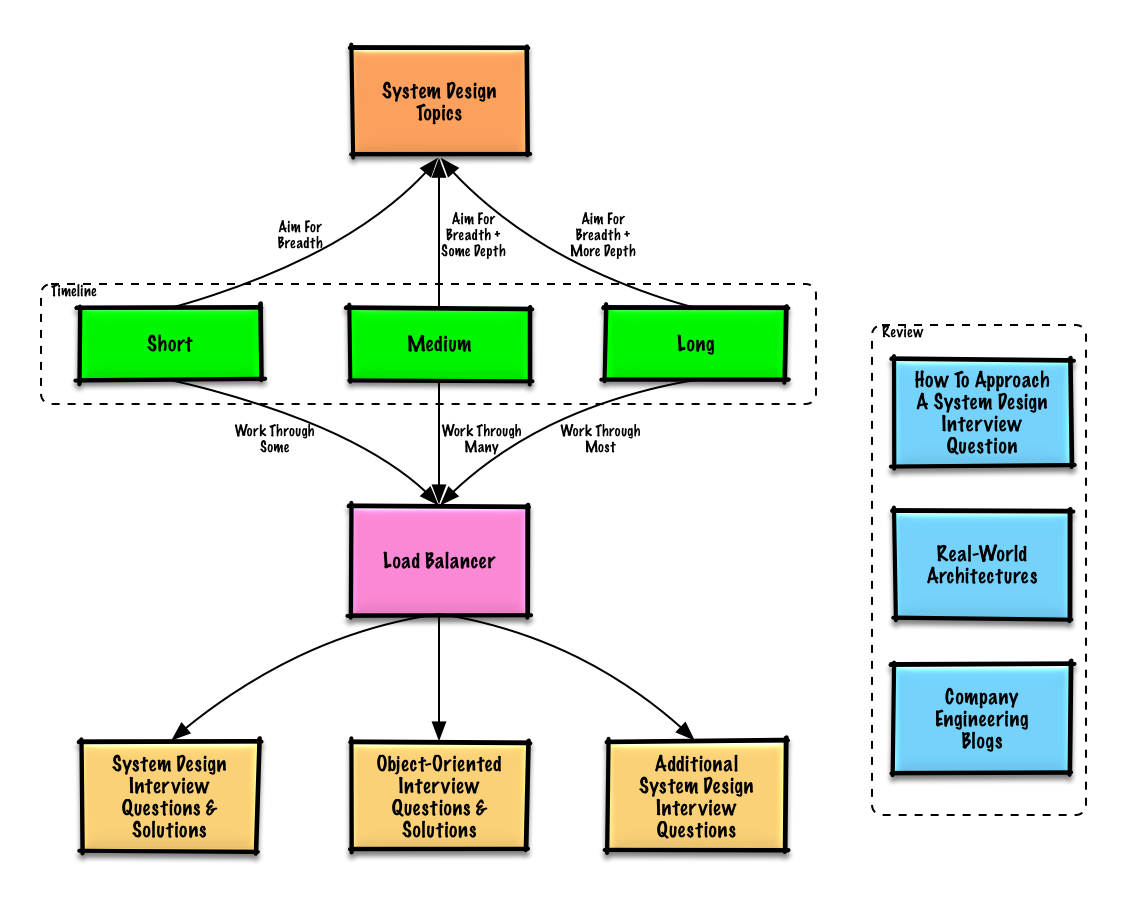
Guía de estudio
Temas sugeridos para revisar según tu cronograma de entrevistas (corto, medio, largo).
P: Para las entrevistas, ¿necesito saber todo lo que está aquí?
R: No, no necesitas saber todo esto para prepararte para la entrevista.
Lo que te pregunten en una entrevista depende de variables como:
- Cuánta experiencia tienes
- Cuál es tu formación técnica
- Para qué puestos estás entrevistando
- Con qué empresas estás entrevistando
- Suerte
Comienza de forma amplia y profundiza en algunas áreas. Ayuda conocer un poco sobre varios temas clave de diseño de sistemas. Ajusta la siguiente guía según tu cronograma, experiencia, los puestos para los que estás entrevistando y las empresas con las que estás en proceso de selección.
- Cronograma corto - Apunta a la amplitud en temas de diseño de sistemas. Practica resolviendo algunas preguntas de entrevista.
- Cronograma medio - Apunta a la amplitud y algo de profundidad en temas de diseño de sistemas. Practica resolviendo muchas preguntas de entrevista.
- Cronograma largo - Apunta a la amplitud y más profundidad en temas de diseño de sistemas. Practica resolviendo la mayoría de preguntas de entrevista.
Cómo abordar una pregunta de entrevista de diseño de sistemas
Cómo enfrentar una pregunta de entrevista de diseño de sistemas.
La entrevista de diseño de sistemas es una conversación abierta. Se espera que tú la lideres.
Puedes usar los siguientes pasos para guiar la discusión. Para ayudar a consolidar este proceso, trabaja la sección de Preguntas de entrevistas de diseño de sistemas con soluciones usando los siguientes pasos.
Paso 1: Delimitar casos de uso, restricciones y suposiciones
Reúne los requisitos y define el alcance del problema. Haz preguntas para clarificar casos de uso y restricciones. Discute las suposiciones.
- ¿Quién lo va a usar?
- ¿Cómo lo van a usar?
- ¿Cuántos usuarios hay?
- ¿Qué hace el sistema?
- ¿Cuáles son las entradas y salidas del sistema?
- ¿Cuánta información esperamos manejar?
- ¿Cuántas solicitudes por segundo esperamos?
- ¿Cuál es la proporción esperada de lectura a escritura?
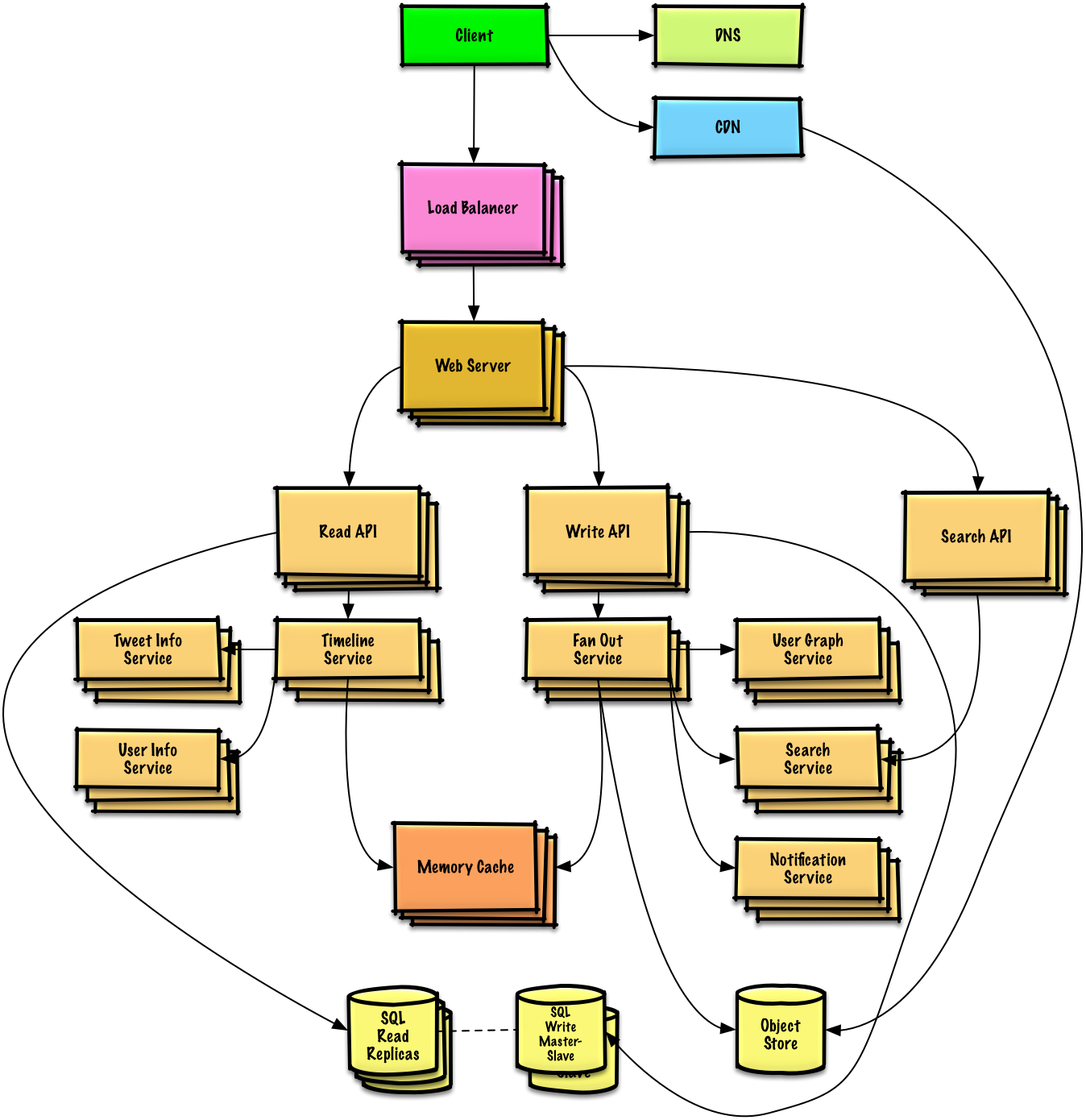
Paso 2: Crear un diseño a alto nivel
Esboza un diseño a alto nivel con todos los componentes importantes.
- Esboza los componentes principales y las conexiones
- Justifica tus ideas
Paso 3: Diseñar los componentes centrales
Profundiza en los detalles de cada componente central. Por ejemplo, si te piden diseñar un servicio de acortamiento de URLs, discute:
- Generar y almacenar un hash de la URL completa
- MD5 y Base62
- Colisiones de hash
- SQL o NoSQL
- Esquema de base de datos
- Traducir una URL hasheada a la URL completa
- Consulta en base de datos
- Diseño de API y orientado a objetos
Paso 4: Escalar el diseño
Identifica y soluciona los cuellos de botella, dadas las restricciones. Por ejemplo, ¿necesitas lo siguiente para abordar problemas de escalabilidad?
- Balanceador de carga
- Escalado horizontal
- Caché
- Fragmentación de base de datos
Cálculos aproximados
Podrías necesitar hacer algunas estimaciones a mano. Consulta el Apéndice para los siguientes recursos:
- Usar cálculos aproximados
- Tabla de potencias de dos
- Números de latencia que todo programador debería conocer
Fuente(s) y lectura adicional
Consulta los siguientes enlaces para tener una mejor idea de qué esperar:
- Cómo triunfar en una entrevista de diseño de sistemas
- La entrevista de diseño de sistemas
- Introducción a la arquitectura y entrevistas de diseño de sistemas
- Plantilla de diseño de sistemas
Preguntas de entrevistas de diseño de sistemas con soluciones
Preguntas comunes de entrevistas de diseño de sistemas con discusiones de ejemplo, código y diagramas.>
Soluciones enlazadas al contenido en la carpeta solutions/.| Pregunta | | |---|---| | Diseñar Pastebin.com (o Bit.ly) | Solución | | Diseñar la línea de tiempo y búsqueda de Twitter (o el feed y búsqueda de Facebook) | Solución | | Diseñar un rastreador web | Solución | | Diseñar Mint.com | Solución | | Diseñar las estructuras de datos para una red social | Solución | | Diseñar un almacén clave-valor para un motor de búsqueda | Solución | | Diseñar la función de clasificación de ventas por categoría de Amazon | Solución | | Diseñar un sistema que escale a millones de usuarios en AWS | Solución | | Añadir una pregunta de diseño de sistemas | Contribuir |
Diseñar Pastebin.com (o Bit.ly)
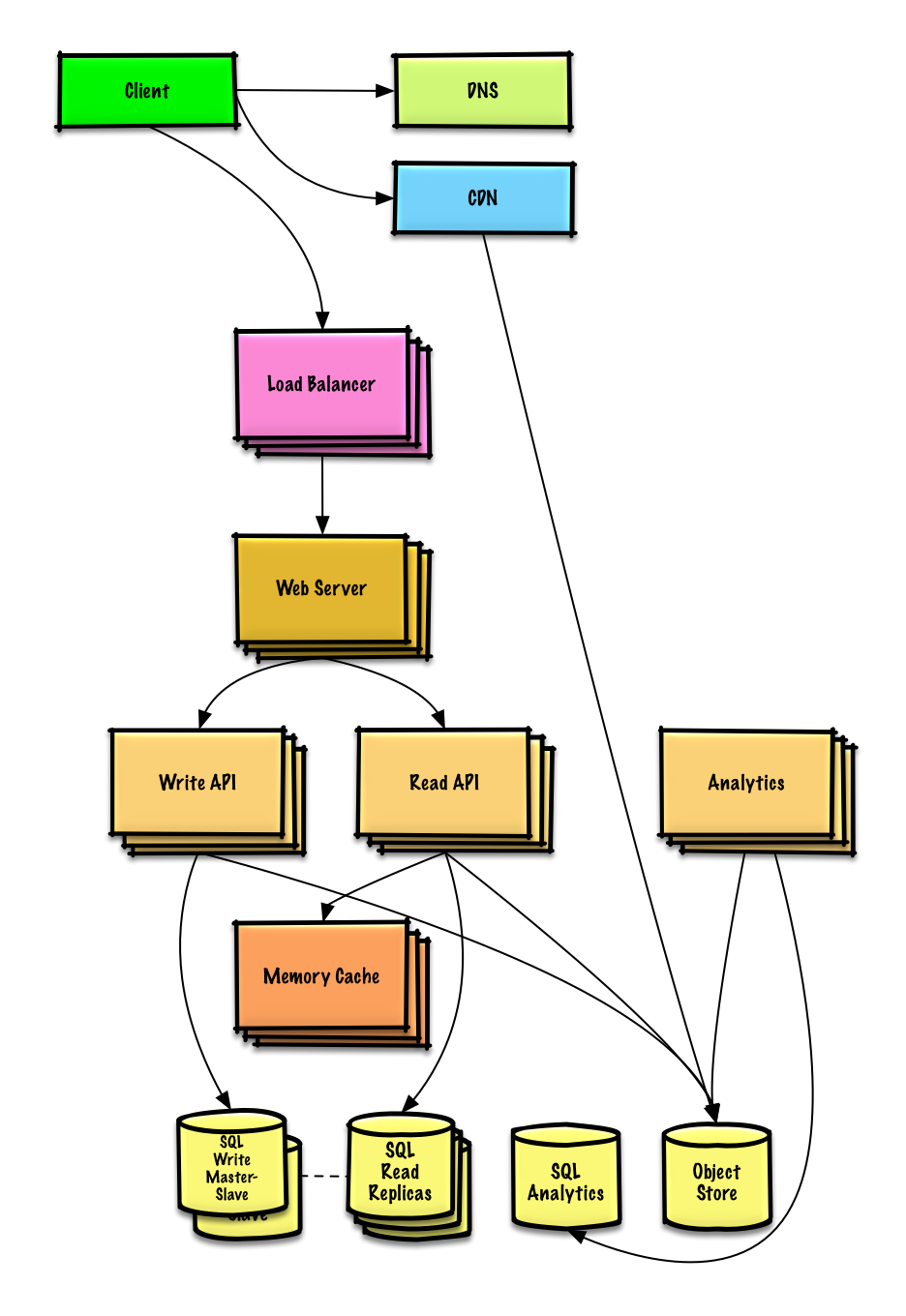
Diseñar la línea de tiempo y búsqueda de Twitter (o el feed y búsqueda de Facebook)
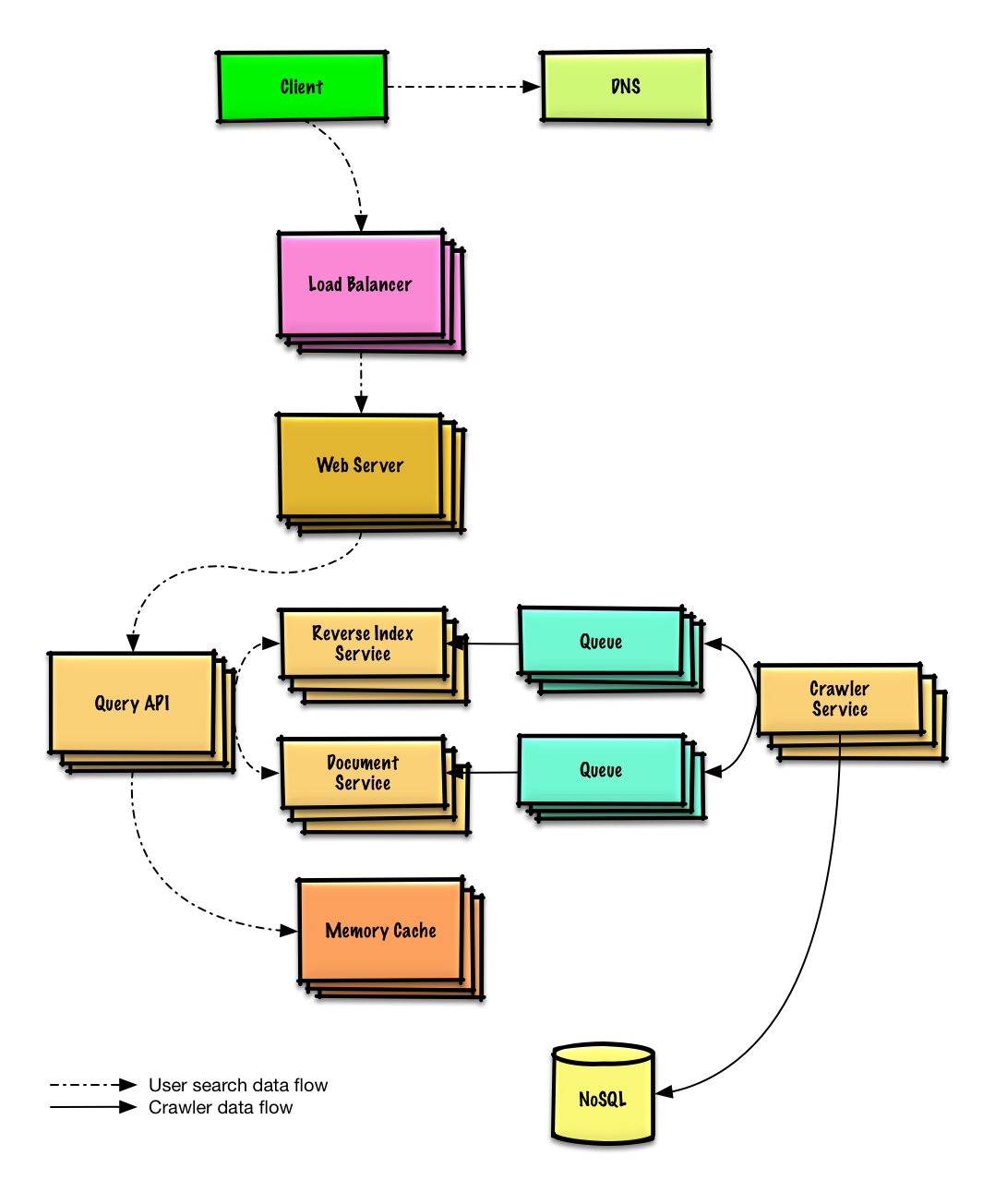
Diseñar un rastreador web
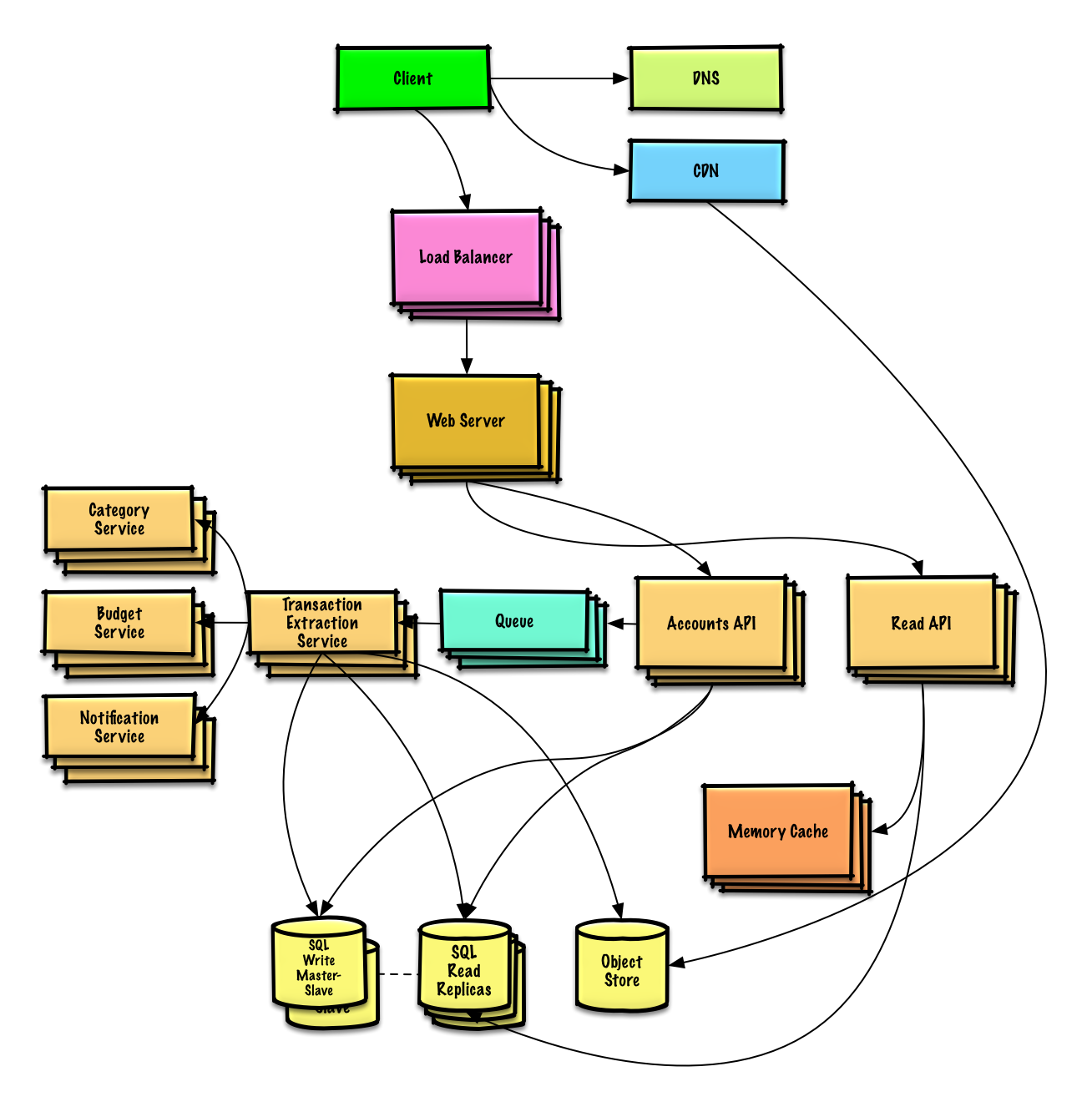
Design Mint.com
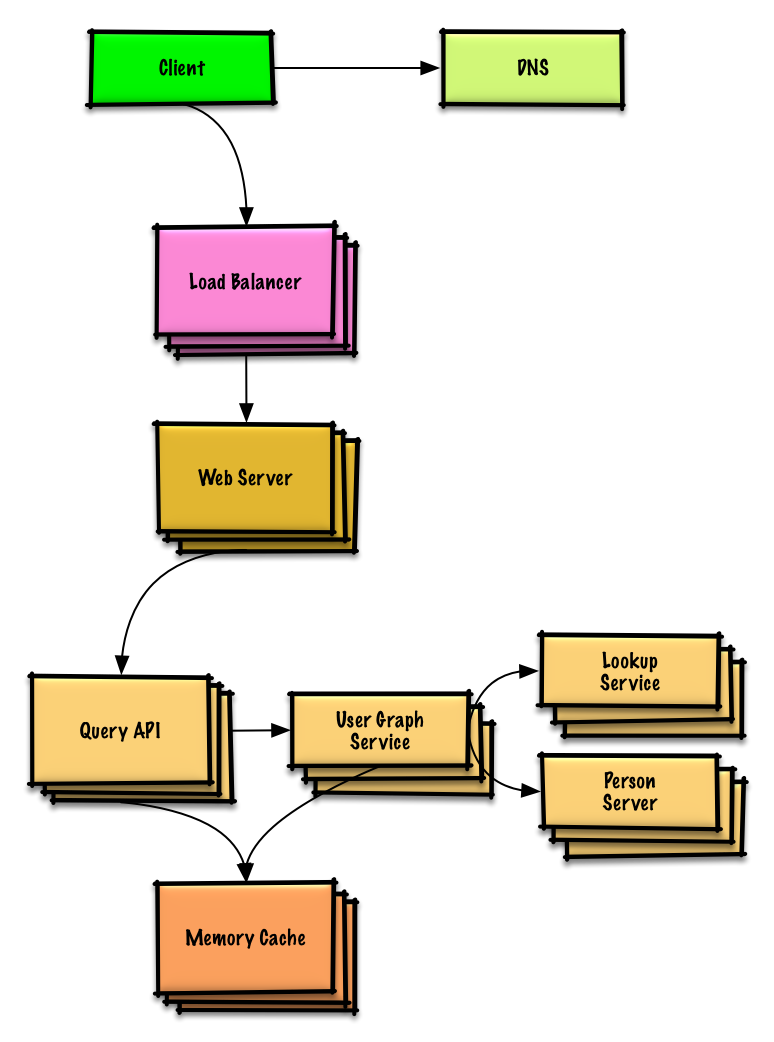
Design the data structures for a social network
Design a key-value store for a search engine
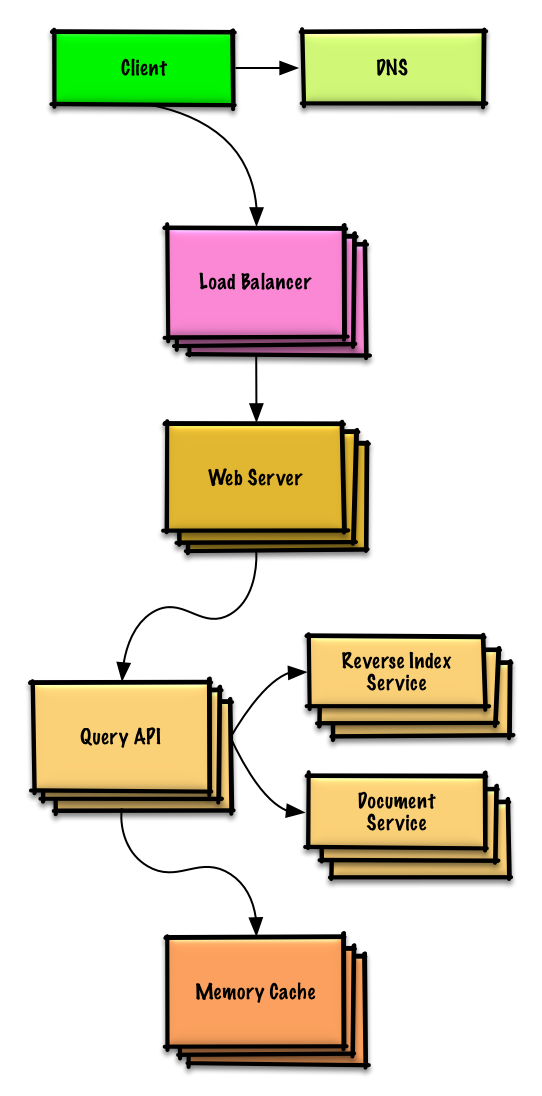
Design Amazon's sales ranking by category feature
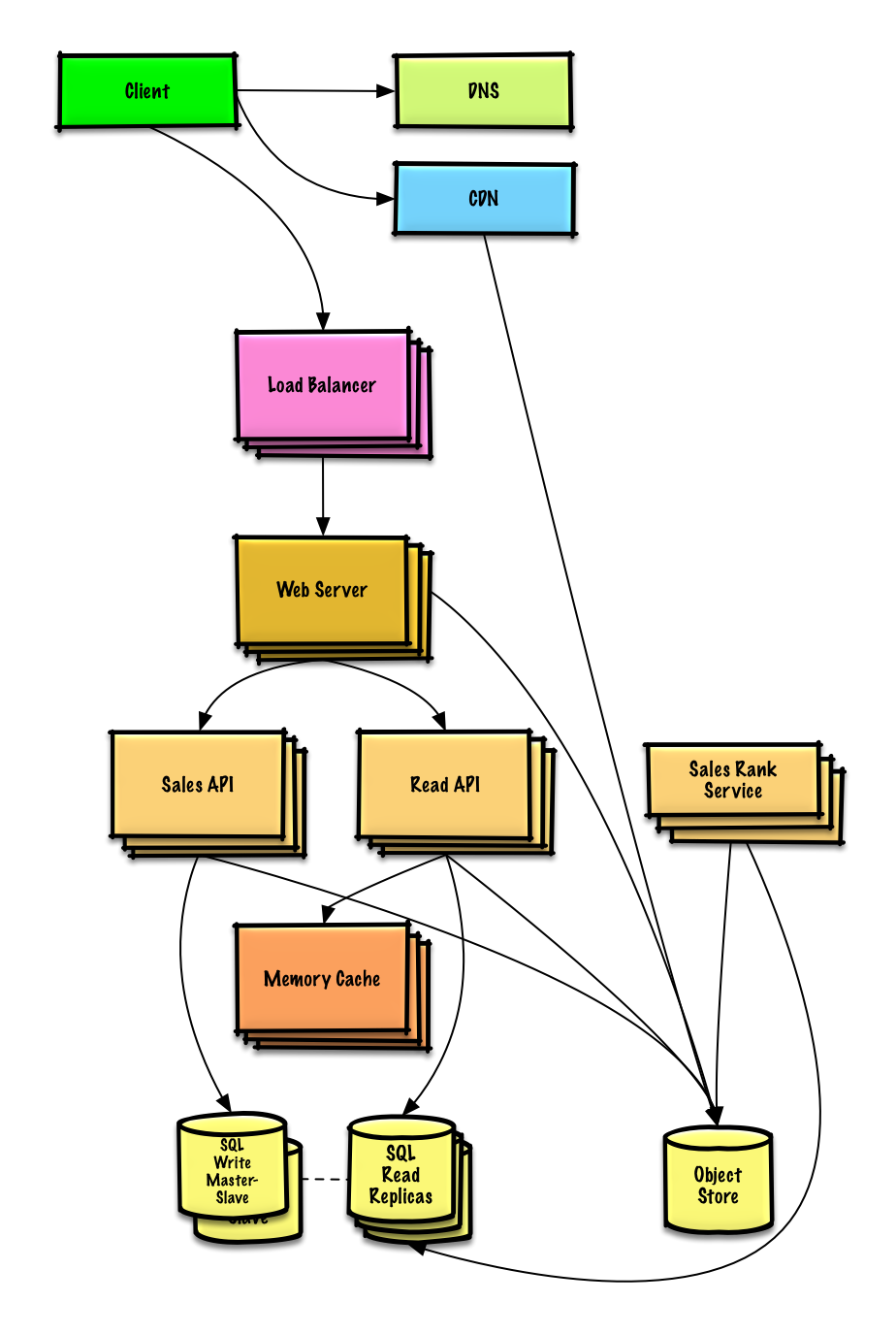
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Diseñar un mapa hash | Solución | | Diseñar una caché LRU (menos recientemente usada) | Solución | | Diseñar un centro de llamadas | Solución | | Diseñar una baraja de cartas | Solución | | Diseñar un estacionamiento | Solución | | Diseñar un servidor de chat | Solución | | Diseñar un arreglo circular | Contribuir | | Añadir una pregunta de diseño orientado a objetos | Contribuir |
Temas de diseño de sistemas: comienza aquí
¿Nuevo en diseño de sistemas?
Primero, necesitarás una comprensión básica de principios comunes, aprendiendo qué son, cómo se usan y sus pros y contras.
Paso 1: Revisar la clase magistral sobre escalabilidad
Clase sobre escalabilidad en Harvard
- Temas cubiertos:
- Escalado vertical
- Escalado horizontal
- Caché
- Balanceo de carga
- Replicación de bases de datos
- Particionamiento de bases de datos
Paso 2: Revisar el artículo sobre escalabilidad
- Temas cubiertos:
- Clones
- Bases de datos
- Cachés
- Asincronismo
Próximos pasos
A continuación, analizaremos las compensaciones a alto nivel:
- Rendimiento vs escalabilidad
- Latencia vs rendimiento
- Disponibilidad vs consistencia
Luego profundizaremos en temas más específicos como DNS, CDN y balanceadores de carga.
Rendimiento vs escalabilidad
Un servicio es escalable si resulta en un aumento del rendimiento de manera proporcional a los recursos añadidos. Generalmente, aumentar el rendimiento significa servir más unidades de trabajo, pero también puede ser para manejar unidades de trabajo más grandes, como cuando los conjuntos de datos crecen.1
Otra forma de ver rendimiento vs escalabilidad:
- Si tienes un problema de rendimiento, tu sistema es lento para un solo usuario.
- Si tienes un problema de escalabilidad, tu sistema es rápido para un solo usuario pero lento bajo una carga pesada.
Fuente(s) y lectura adicional
Latencia vs rendimiento
Latencia es el tiempo para realizar alguna acción o producir algún resultado.
Rendimiento es el número de tales acciones o resultados por unidad de tiempo.
Generalmente, debes apuntar a un rendimiento máximo con una latencia aceptable.
Fuente(s) y lectura adicional
Disponibilidad vs consistencia
Teorema CAP
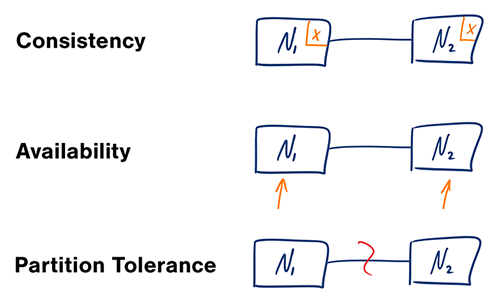
Fuente: Teorema CAP revisitado
En un sistema informático distribuido, solo puedes soportar dos de las siguientes garantías:
- Consistencia - Cada lectura recibe la escritura más reciente o un error
- Disponibilidad - Cada solicitud recibe una respuesta, sin garantía de que contenga la versión más reciente de la información
- Tolerancia a particiones - El sistema continúa operando a pesar de particionamientos arbitrarios debido a fallos en la red
#### CP - consistencia y tolerancia a particiones
Esperar una respuesta del nodo particionado podría resultar en un error de tiempo de espera. CP es una buena opción si las necesidades de tu negocio requieren lecturas y escrituras atómicas.
#### AP - disponibilidad y tolerancia a particiones
Las respuestas devuelven la versión más fácilmente disponible de los datos en cualquier nodo, que podría no ser la más reciente. Las escrituras podrían tardar en propagarse cuando se resuelve la partición.
AP es una buena opción si el negocio necesita permitir la consistencia eventual o cuando el sistema debe continuar funcionando a pesar de errores externos.
Fuente(s) y lectura adicional
Patrones de consistencia
Con múltiples copias de los mismos datos, enfrentamos opciones sobre cómo sincronizarlas para que los clientes tengan una vista consistente de los datos. Recuerda la definición de consistencia del teorema CAP: cada lectura recibe la escritura más reciente o un error.
Consistencia débil
Después de una escritura, las lecturas pueden o no verla. Se adopta un enfoque de mejor esfuerzo.
Este enfoque se observa en sistemas como memcached. La consistencia débil funciona bien en casos de uso en tiempo real como VoIP, chat de video y juegos multijugador en tiempo real. Por ejemplo, si estás en una llamada telefónica y pierdes la señal por unos segundos, cuando recuperas la conexión no escuchas lo que se dijo durante la pérdida de conexión.
Consistencia eventual
Después de una escritura, las lecturas eventualmente la verán (normalmente en milisegundos). Los datos se replican de forma asincrónica.
Este enfoque se observa en sistemas como DNS y correo electrónico. La consistencia eventual funciona bien en sistemas altamente disponibles.
Consistencia fuerte
Después de una escritura, las lecturas la verán. Los datos se replican de forma sincrónica.
Este enfoque se observa en sistemas de archivos y RDBMS. La consistencia fuerte funciona bien en sistemas que necesitan transacciones.
Fuente(s) y lectura adicional
Patrones de disponibilidad
Existen dos patrones complementarios para soportar alta disponibilidad: fail-over y replicación.
Fail-over
#### Activo-pasivo
Con fail-over activo-pasivo, se envían latidos entre el servidor activo y el servidor pasivo en espera. Si el latido se interrumpe, el servidor pasivo toma la dirección IP del activo y reanuda el servicio.
La duración del tiempo de inactividad depende de si el servidor pasivo ya está funcionando en espera "caliente" o si necesita arrancar desde una espera "fría". Solo el servidor activo maneja el tráfico.
El failover activo-pasivo también puede denominarse failover maestro-esclavo.
#### Activo-activo
En activo-activo, ambos servidores gestionan el tráfico, distribuyendo la carga entre ellos.
Si los servidores están expuestos al público, el DNS necesitaría conocer las IP públicas de ambos servidores. Si los servidores están orientados internamente, la lógica de la aplicación debería conocer ambos servidores.
El failover activo-activo también puede denominarse failover maestro-maestro.
Desventaja(s): failover
- La conmutación por error añade más hardware y complejidad adicional.
- Existe un potencial de pérdida de datos si el sistema activo falla antes de que cualquier dato recién escrito pueda ser replicado al pasivo.
Replicación
#### Maestro-esclavo y maestro-maestro
Este tema se discute más a fondo en la sección de Base de datos:
Disponibilidad en números
La disponibilidad a menudo se cuantifica por el tiempo de actividad (o inactividad) como un porcentaje del tiempo que el servicio está disponible. La disponibilidad generalmente se mide en número de nueves: un servicio con 99.99% de disponibilidad se describe como que tiene cuatro nueves.
#### Disponibilidad del 99.9% - tres nueves
| Duración | Tiempo de inactividad aceptable | |---------------------|--------------------------------| | Inactividad por año | 8h 45min 57s | | Inactividad por mes | 43m 49.7s | | Inactividad por semana | 10m 4.8s | | Inactividad por día | 1m 26.4s |
#### Disponibilidad del 99.99% - cuatro nueves
| Duración | Tiempo de inactividad aceptable | |---------------------|--------------------------------| | Inactividad por año | 52min 35.7s | | Inactividad por mes | 4m 23s | | Inactividad por semana | 1m 5s | | Inactividad por día | 8.6s |
#### Disponibilidad en paralelo vs en secuencia
Si un servicio consiste en múltiples componentes propensos a fallos, la disponibilidad general del servicio depende de si los componentes están en secuencia o en paralelo.
###### En secuencia
La disponibilidad general disminuye cuando dos componentes con disponibilidad < 100 % están en secuencia:
Availability (Total) = Availability (Foo) * Availability (Bar)Foo como Bar tuvieran cada uno un 99.9% de disponibilidad, su disponibilidad total en secuencia sería del 99.8%.###### En paralelo
La disponibilidad general aumenta cuando dos componentes con disponibilidad < 100% están en paralelo:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo como Bar tuvieran cada uno un 99.9% de disponibilidad, su disponibilidad total en paralelo sería del 99.9999%.Sistema de nombres de dominio
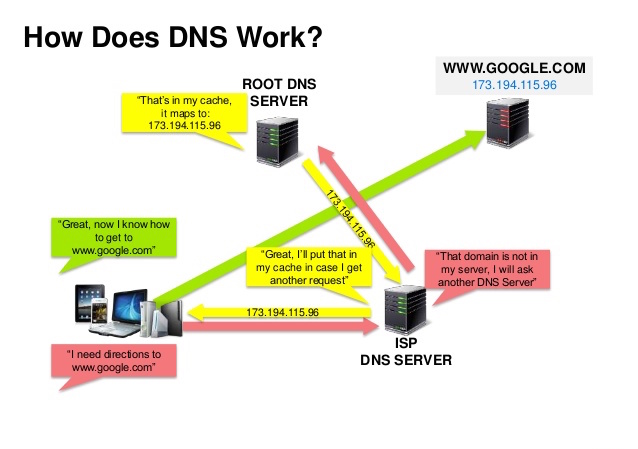
Fuente: Presentación de seguridad DNS
Un Sistema de Nombres de Dominio (DNS) traduce un nombre de dominio como www.example.com a una dirección IP.
El DNS es jerárquico, con algunos servidores autorizados en el nivel superior. Tu router o ISP proporciona información sobre qué servidor(es) DNS contactar al realizar una consulta. Los servidores DNS de nivel inferior almacenan en caché los mapeos, que podrían volverse obsoletos debido a retrasos en la propagación del DNS. Los resultados DNS también pueden ser almacenados en caché por tu navegador o sistema operativo durante un cierto período, determinado por el tiempo de vida (TTL).
- Registro NS (servidor de nombres) - Especifica los servidores DNS para tu dominio/subdominio.
- Registro MX (intercambio de correo) - Especifica los servidores de correo para aceptar mensajes.
- Registro A (dirección) - Apunta un nombre a una dirección IP.
- CNAME (canónico) - Apunta un nombre a otro nombre o
CNAME(example.com a www.example.com) o a un registroA.
- Round robin ponderado
- Evitar que el tráfico vaya a servidores en mantenimiento
- Balancear entre tamaños variables de clúster
- Pruebas A/B
- Basado en latencia
- Basado en geolocalización
Desventaja(s): DNS
- Acceder a un servidor DNS introduce una pequeña demora, aunque mitigada por el almacenamiento en caché descrito arriba.
- La gestión de servidores DNS puede ser compleja y generalmente está a cargo de gobiernos, ISP y grandes empresas.
- Los servicios DNS han sido recientemente objeto de ataques DDoS, impidiendo que los usuarios accedan a sitios web como Twitter sin conocer la(s) dirección(es) IP de Twitter.
Fuente(s) y lecturas adicionales
Red de entrega de contenido
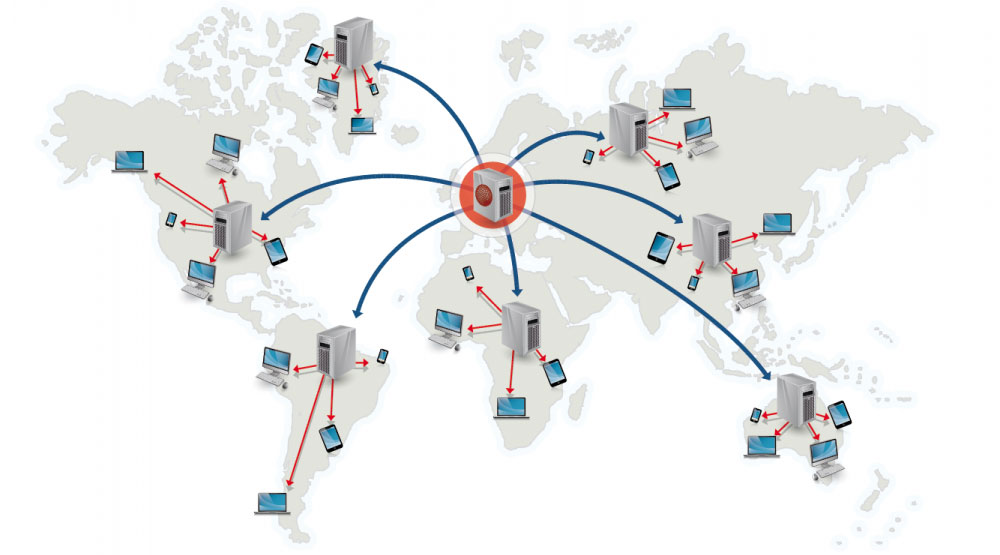
Una red de entrega de contenido (CDN) es una red distribuida globalmente de servidores proxy, que sirven contenido desde ubicaciones más cercanas al usuario. Generalmente, archivos estáticos como HTML/CSS/JS, fotos y videos son servidos desde la CDN, aunque algunas CDNs como CloudFront de Amazon soportan contenido dinámico. La resolución DNS del sitio indicará a los clientes qué servidor contactar.
Servir contenido desde CDNs puede mejorar significativamente el rendimiento de dos maneras:
- Los usuarios reciben contenido desde centros de datos cercanos a ellos
- Tus servidores no tienen que atender solicitudes que la CDN cumple
CDNs Push
Las CDNs push reciben contenido nuevo cada vez que ocurren cambios en tu servidor. Asumes plena responsabilidad por proporcionar contenido, subiéndolo directamente a la CDN y reescribiendo URLs para apuntar a la CDN. Puedes configurar cuándo expira el contenido y cuándo se actualiza. El contenido se sube solo cuando es nuevo o cambiado, minimizando el tráfico, pero maximizando el almacenamiento.
Los sitios con poco tráfico o sitios con contenido que no se actualiza con frecuencia funcionan bien con CDNs push. El contenido se coloca en las CDNs una sola vez, en lugar de ser recuperado repetidamente en intervalos regulares.
CDNs Pull
Las CDNs pull obtienen contenido nuevo de tu servidor cuando el primer usuario solicita el contenido. Dejas el contenido en tu servidor y reescribes URLs para apuntar a la CDN. Esto resulta en una solicitud más lenta hasta que el contenido se cachea en la CDN.
Un tiempo de vida (TTL) determina cuánto tiempo se cachea el contenido. Las CDNs pull minimizan el espacio de almacenamiento en la CDN, pero pueden crear tráfico redundante si los archivos expiran y se recuperan antes de que hayan cambiado realmente.
Los sitios con tráfico elevado funcionan bien con CDNs pull, ya que el tráfico se distribuye de manera más uniforme y solo el contenido solicitado recientemente permanece en la CDN.
Desventaja(s): CDN
- Los costos de CDN podrían ser significativos dependiendo del tráfico, aunque esto debe ponderarse con los costos adicionales que incurrirías al no usar una CDN.
- El contenido podría estar desactualizado si se actualiza antes de que expire el TTL.
- Las CDNs requieren cambiar URLs para el contenido estático para apuntar a la CDN.
Fuente(s) y lectura adicional
Balanceador de carga
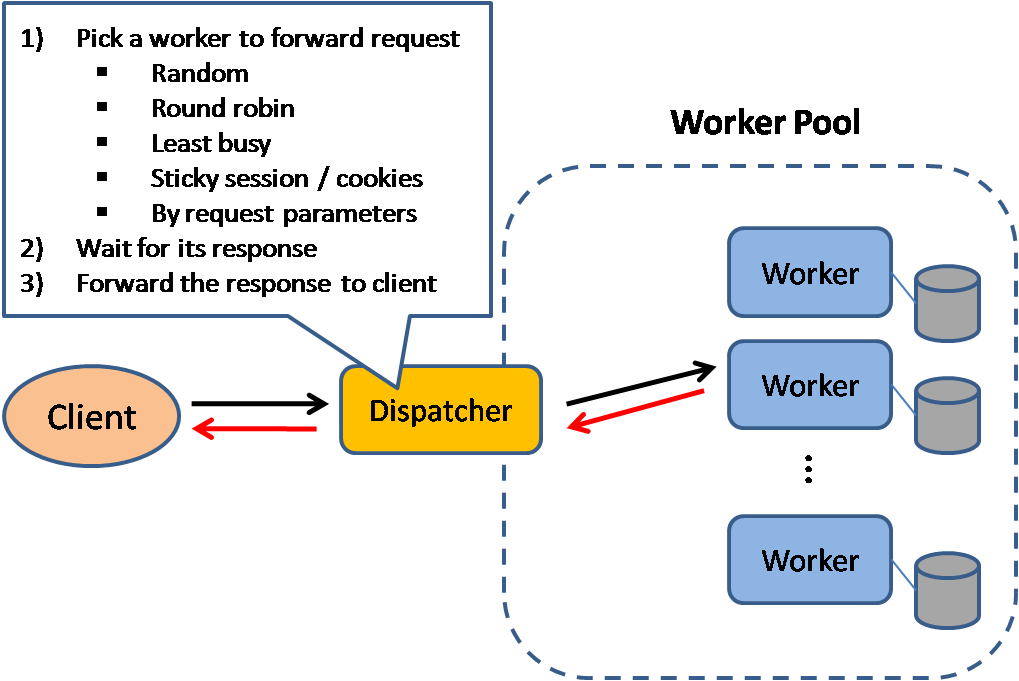
Fuente: Patrones de diseño de sistemas escalables
Los balanceadores de carga distribuyen las solicitudes entrantes de los clientes a recursos informáticos como servidores de aplicaciones y bases de datos. En cada caso, el balanceador de carga devuelve la respuesta del recurso informático al cliente correspondiente. Los balanceadores de carga son efectivos para:
- Prevenir que las solicitudes se dirijan a servidores no saludables
- Evitar la sobrecarga de recursos
- Ayudar a eliminar un punto único de fallo
Beneficios adicionales incluyen:
- Terminación SSL - Desencriptar solicitudes entrantes y encriptar respuestas del servidor para que los servidores backend no tengan que realizar estas operaciones potencialmente costosas
- Elimina la necesidad de instalar certificados X.509 en cada servidor
- Persistencia de sesión - Emitir cookies y enrutar las solicitudes de un cliente específico a la misma instancia si las aplicaciones web no mantienen el seguimiento de las sesiones
Los balanceadores de carga pueden enrutar el tráfico basándose en varias métricas, incluyendo:
- Aleatorio
- Menos cargado
- Sesión/cookies
- Round robin o round robin ponderado
- Capa 4
- Capa 7
Balanceo de carga en capa 4
Los balanceadores de carga de capa 4 analizan la información en la capa de transporte para decidir cómo distribuir las solicitudes. Generalmente, esto involucra las direcciones IP de origen y destino, y los puertos en el encabezado, pero no el contenido del paquete. Los balanceadores de carga de capa 4 reenvían paquetes de red hacia y desde el servidor ascendente, realizando Traducción de Direcciones de Red (NAT).
Balanceo de carga en capa 7
Los balanceadores de carga de capa 7 analizan la capa de aplicación para decidir cómo distribuir las solicitudes. Esto puede involucrar el contenido del encabezado, el mensaje y las cookies. Los balanceadores de carga de capa 7 terminan el tráfico de red, leen el mensaje, toman una decisión de balanceo de carga y luego abren una conexión con el servidor seleccionado. Por ejemplo, un balanceador de carga de capa 7 puede dirigir el tráfico de video a servidores que alojan videos mientras dirige el tráfico más sensible de facturación de usuarios a servidores reforzados en seguridad.
A costa de la flexibilidad, el balanceo de carga de capa 4 requiere menos tiempo y recursos computacionales que la capa 7, aunque el impacto en el rendimiento puede ser mínimo en hardware moderno y común.
Escalamiento horizontal
Los balanceadores de carga también pueden ayudar con el escalamiento horizontal, mejorando el rendimiento y la disponibilidad. Escalar usando máquinas comunes es más eficiente en costos y resulta en mayor disponibilidad que escalar un solo servidor con hardware más costoso, llamado Escalamiento Vertical. También es más fácil contratar talento que trabaje con hardware común que con sistemas empresariales especializados.
#### Desventaja(s): escalamiento horizontal
- Escalar horizontalmente introduce complejidad e implica clonar servidores
- Los servidores deben ser sin estado: no deben contener datos relacionados con el usuario como sesiones o fotos de perfil
- Las sesiones pueden almacenarse en un almacén de datos centralizado como una base de datos (SQL, NoSQL) o una caché persistente (Redis, Memcached)
- Los servidores aguas abajo, como cachés y bases de datos, necesitan manejar más conexiones simultáneas a medida que los servidores aguas arriba escalan
Desventaja(s): balanceador de carga
- El balanceador de carga puede convertirse en un cuello de botella de rendimiento si no tiene suficientes recursos o si no está configurado correctamente.
- Introducir un balanceador de carga para ayudar a eliminar un único punto de falla resulta en mayor complejidad.
- Un solo balanceador de carga es un único punto de falla; configurar múltiples balanceadores de carga aumenta aún más la complejidad.
Fuente(s) y lectura adicional
- Arquitectura de NGINX
- Guía de arquitectura de HAProxy
- Escalabilidad
- Wikipedia)
- Balanceo de carga de capa 4
- Balanceo de carga de capa 7
- Configuración de listener ELB
Proxy inverso (servidor web)
Un proxy inverso es un servidor web que centraliza servicios internos y proporciona interfaces unificadas al público. Las solicitudes de los clientes se reenvían a un servidor que puede cumplirlas antes de que el proxy inverso devuelva la respuesta del servidor al cliente.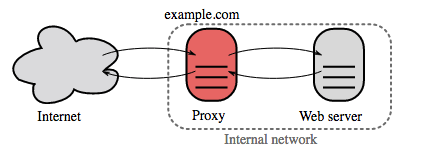
Beneficios adicionales incluyen:
- Mayor seguridad - Ocultar información sobre los servidores backend, bloquear IPs, limitar el número de conexiones por cliente
- Mayor escalabilidad y flexibilidad - Los clientes solo ven la IP del proxy inverso, lo que permite escalar servidores o cambiar su configuración
- Terminación SSL - Desencriptar solicitudes entrantes y encriptar respuestas del servidor para que los servidores backend no tengan que realizar estas operaciones potencialmente costosas
- Elimina la necesidad de instalar certificados X.509 en cada servidor
- Compresión - Comprimir respuestas del servidor
- Caché - Devolver la respuesta para solicitudes en caché
- Contenido estático - Servir contenido estático directamente
- HTML/CSS/JS
- Fotos
- Videos
- Etc
Balanceador de carga vs proxy inverso
- Implementar un balanceador de carga es útil cuando se tienen múltiples servidores. A menudo, los balanceadores de carga dirigen el tráfico a un conjunto de servidores que cumplen la misma función.
- Los proxies inversos pueden ser útiles incluso con un solo servidor web o servidor de aplicaciones, abriendo los beneficios descritos en la sección anterior.
- Soluciones como NGINX y HAProxy pueden soportar tanto proxy inverso en capa 7 como balanceo de carga.
Desventaja(s): proxy inverso
- Introducir un proxy inverso resulta en una mayor complejidad.
- Un solo proxy inverso es un único punto de fallo, configurar múltiples proxies inversos (es decir, un failover) aumenta aún más la complejidad.
Fuente(s) y lectura adicional
- Proxy inverso vs balanceador de carga
- Arquitectura de NGINX
- Guía de arquitectura de HAProxy
- Wikipedia
Capa de aplicación
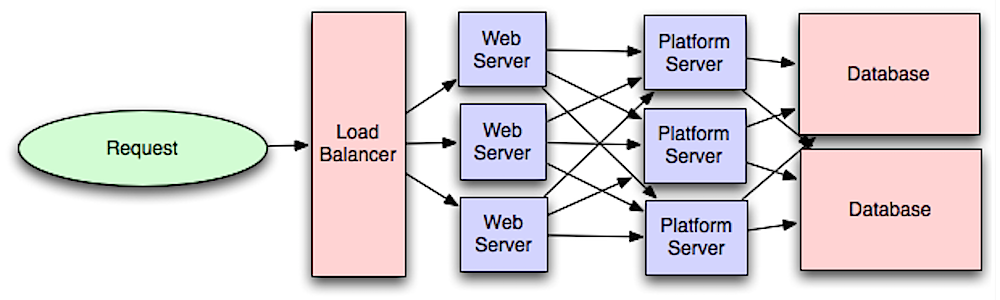
Fuente: Introducción a la arquitectura de sistemas para escalabilidad
Separar la capa web de la capa de aplicación (también conocida como capa de plataforma) permite escalar y configurar ambas capas de manera independiente. Agregar una nueva API resulta en añadir servidores de aplicación sin necesariamente añadir servidores web adicionales. El principio de responsabilidad única aboga por servicios pequeños y autónomos que trabajan juntos. Equipos pequeños con servicios pequeños pueden planificar de forma más agresiva para un crecimiento rápido.
Los trabajadores en la capa de aplicación también ayudan a habilitar el asincronismo.
Microservicios
Relacionado con esta discusión están los microservicios, que pueden describirse como un conjunto de servicios pequeños, modulares e independientemente desplegables. Cada servicio ejecuta un proceso único y se comunica a través de un mecanismo ligero y bien definido para cumplir un objetivo de negocio. 1
Pinterest, por ejemplo, podría tener los siguientes microservicios: perfil de usuario, seguidores, feed, búsqueda, subida de fotos, etc.
Descubrimiento de servicios
Sistemas como Consul, Etcd, y Zookeeper pueden ayudar a que los servicios se encuentren entre sí manteniendo un registro de nombres, direcciones y puertos registrados. Los chequeos de salud ayudan a verificar la integridad del servicio y a menudo se realizan usando un endpoint HTTP. Tanto Consul como Etcd tienen una almacén clave-valor incorporado que puede ser útil para almacenar valores de configuración y otros datos compartidos.
Desventaja(s): capa de aplicación
- Agregar una capa de aplicación con servicios débilmente acoplados requiere un enfoque diferente desde el punto de vista arquitectónico, operativo y de procesos (vs un sistema monolítico).
- Los microservicios pueden añadir complejidad en términos de despliegues y operaciones.
Fuente(s) y lectura adicional
- Introducción a la arquitectura de sistemas para escalabilidad
- Domina la entrevista de diseño de sistemas
- Arquitectura orientada a servicios
- Introducción a Zookeeper
- Esto es lo que necesitas saber sobre la construcción de microservicios
Base de datos
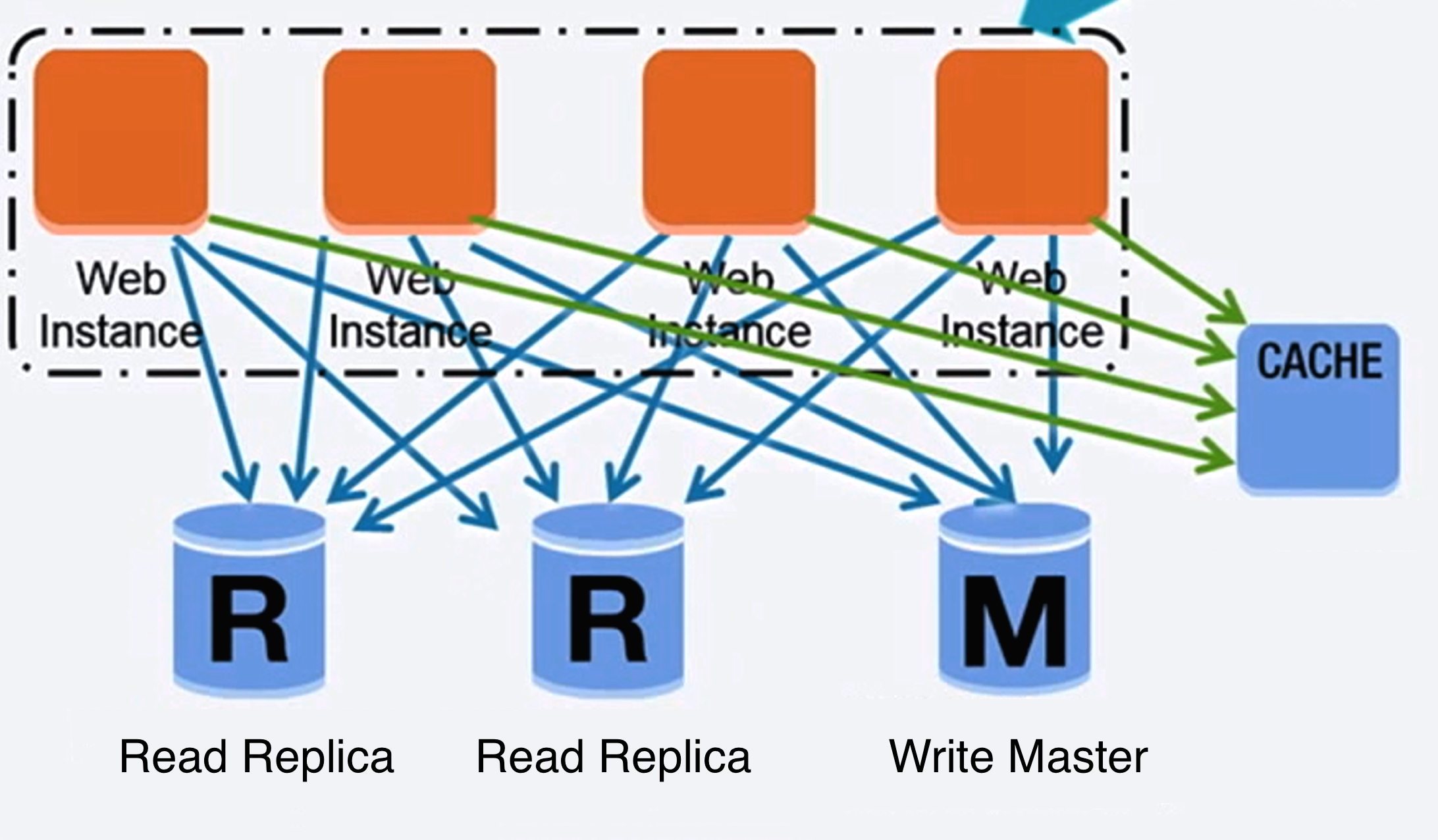
Fuente: Escalando hasta tus primeros 10 millones de usuarios
Sistema de gestión de bases de datos relacionales (RDBMS)
Una base de datos relacional como SQL es una colección de elementos de datos organizados en tablas.
ACID es un conjunto de propiedades de las transacciones) en bases de datos relacionales.
- Atomicidad - Cada transacción es todo o nada
- Consistencia - Cualquier transacción llevará la base de datos de un estado válido a otro
- Aislamiento - Ejecutar transacciones concurrentemente tiene los mismos resultados que si se ejecutaran en serie
- Durabilidad - Una vez que una transacción ha sido confirmada, permanecerá así
#### Replicación maestro-esclavo
El maestro atiende lecturas y escrituras, replicando las escrituras a uno o más esclavos, que solo atienden lecturas. Los esclavos también pueden replicar a esclavos adicionales en forma de árbol. Si el maestro se desconecta, el sistema puede continuar operando en modo solo lectura hasta que un esclavo sea promovido a maestro o se configure un nuevo maestro.
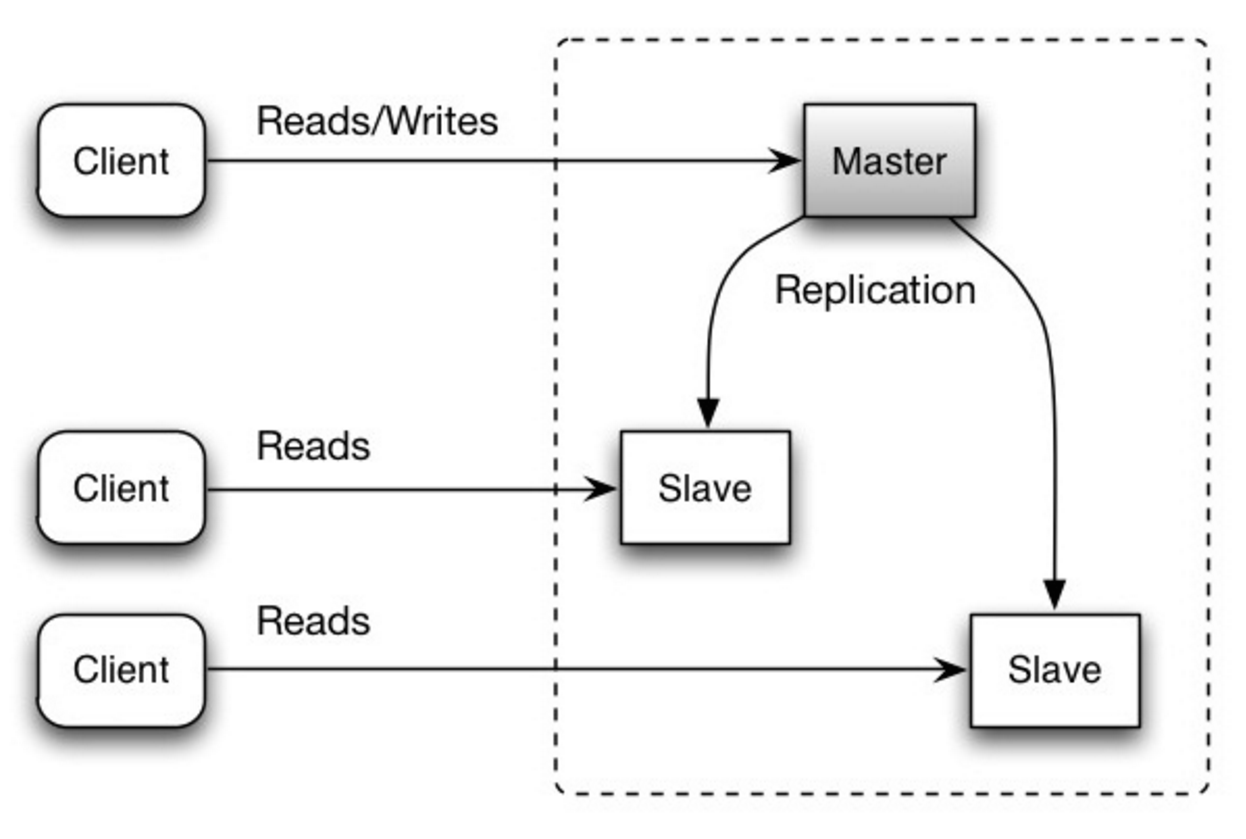
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones
##### Desventaja(s): replicación maestro-esclavo
- Se necesita lógica adicional para promover un esclavo a maestro.
- Ver Desventaja(s): replicación para puntos relacionados con ambos maestro-esclavo y maestro-maestro.
Ambos maestros atienden lecturas y escrituras y coordinan entre sí las escrituras. Si alguno de los maestros falla, el sistema puede continuar operando con lecturas y escrituras.
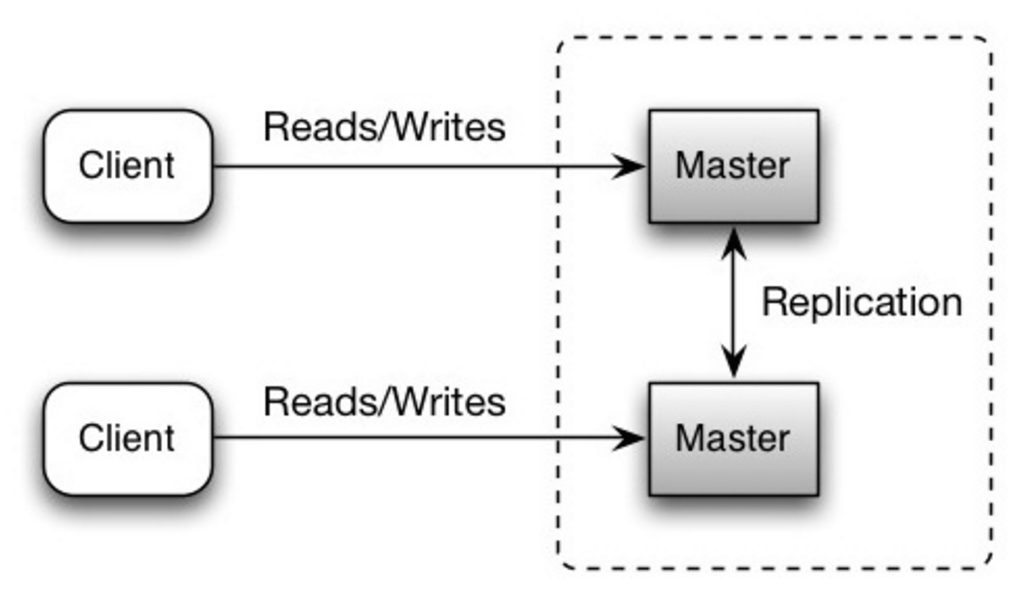
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones
##### Desventaja(s): replicación maestro-maestro
- Necesitarás un balanceador de carga o deberás hacer cambios en la lógica de tu aplicación para determinar dónde escribir.
- La mayoría de sistemas maestro-maestro son o bien débilmente consistentes (violando ACID) o tienen mayor latencia de escritura debido a la sincronización.
- La resolución de conflictos cobra mayor importancia a medida que se añaden más nodos de escritura y aumenta la latencia.
- Consulte Desventaja(s): replicación para puntos relacionados con ambos master-esclavo y master-master.
- Existe la posibilidad de pérdida de datos si el maestro falla antes de que los datos recién escritos puedan replicarse a otros nodos.
- Las escrituras se reproducen en las réplicas de lectura. Si hay muchas escrituras, las réplicas de lectura pueden saturarse con la reproducción de escrituras y no pueden realizar tantas lecturas.
- Cuantos más esclavos de lectura, más tiene que replicar, lo que conduce a una mayor latencia de replicación.
- En algunos sistemas, escribir en el maestro puede generar múltiples hilos para escribir en paralelo, mientras que las réplicas de lectura solo admiten escritura secuencial con un solo hilo.
- La replicación añade más hardware y complejidad adicional.
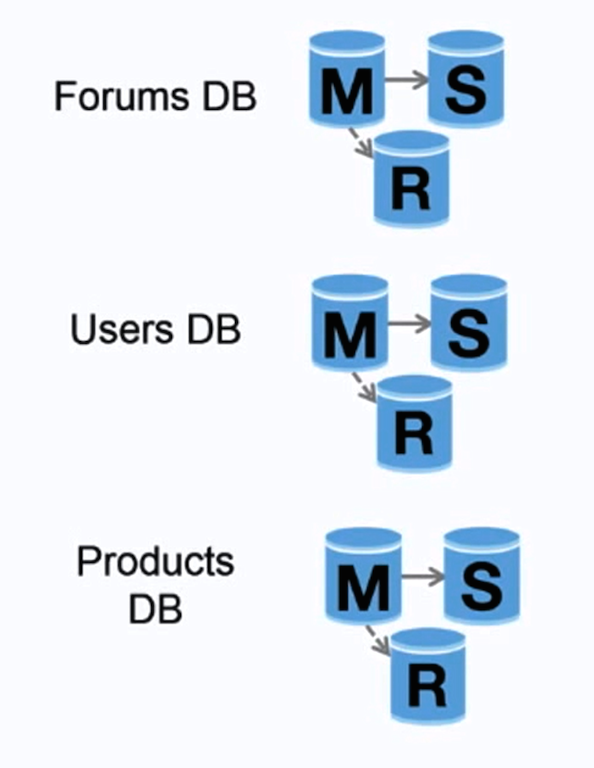
Fuente: Escalando hasta tus primeros 10 millones de usuarios
La federación (o partición funcional) divide las bases de datos por función. Por ejemplo, en lugar de una base de datos monolítica única, podrías tener tres bases de datos: foros, usuarios y productos, lo que resulta en menos tráfico de lectura y escritura para cada base de datos y por lo tanto menos latencia de replicación. Bases de datos más pequeñas resultan en más datos que pueden caber en memoria, lo que a su vez resulta en más aciertos de caché debido a una mejor localidad de caché. Sin un maestro central único que serialice las escrituras, puedes escribir en paralelo, aumentando el rendimiento.
##### Desventaja(s): federación
- La federación no es efectiva si tu esquema requiere funciones o tablas enormes.
- Necesitarás actualizar la lógica de tu aplicación para determinar qué base de datos leer y escribir.
- Unir datos de dos bases de datos es más complejo con un enlace de servidor.
- La federación añade más hardware y complejidad adicional.
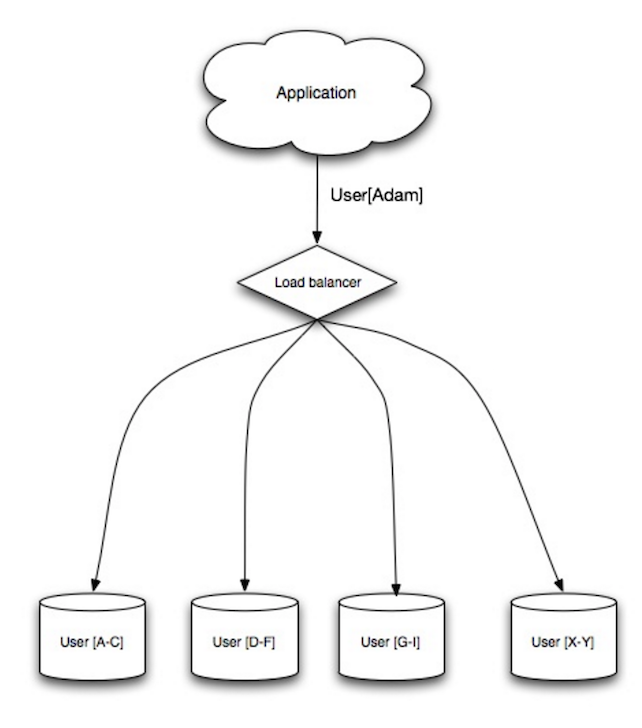
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones
El sharding distribuye datos a través de diferentes bases de datos de modo que cada base de datos solo puede gestionar un subconjunto de los datos. Tomando como ejemplo una base de datos de usuarios, a medida que aumenta el número de usuarios, se añaden más shards al clúster.
De manera similar a las ventajas de la federación, el sharding resulta en menos tráfico de lectura y escritura, menos replicación y más aciertos en caché. El tamaño del índice también se reduce, lo que generalmente mejora el rendimiento con consultas más rápidas. Si un shard falla, los otros shards siguen operativos, aunque querrás añadir alguna forma de replicación para evitar la pérdida de datos. Al igual que la federación, no hay un maestro central único que serialice las escrituras, lo que permite escribir en paralelo con mayor rendimiento.
Las formas comunes de shardear una tabla de usuarios son a través de la inicial del apellido del usuario o la ubicación geográfica del usuario.
##### Desventaja(s): sharding
- Necesitarás actualizar la lógica de tu aplicación para trabajar con shards, lo que podría resultar en consultas SQL complejas.
- La distribución de datos puede volverse desigual en un shard. Por ejemplo, un conjunto de usuarios con mucha actividad en un shard podría resultar en una carga mayor en ese shard comparado con otros.
- El rebalanceo añade complejidad adicional. Una función de sharding basada en hashing consistente puede reducir la cantidad de datos transferidos.
- Realizar joins de datos desde múltiples shards es más complejo.
- El sharding añade más hardware y complejidad adicional.
La desnormalización intenta mejorar el rendimiento de lectura a expensas de algo de rendimiento en escritura. Se escriben copias redundantes de los datos en múltiples tablas para evitar joins costosos. Algunos RDBMS como PostgreSQL y Oracle soportan vistas materializadas que gestionan el trabajo de almacenar información redundante y mantener las copias redundantes consistentes.
Una vez que los datos se distribuyen con técnicas como la federación y el sharding, gestionar joins entre centros de datos incrementa aún más la complejidad. La desnormalización podría evitar la necesidad de esos joins complejos.
En la mayoría de los sistemas, las lecturas pueden superar ampliamente a las escrituras en una proporción de 100:1 o incluso 1000:1. Una lectura que resulta en un join complejo puede ser muy costosa, consumiendo una cantidad significativa de tiempo en operaciones de disco.
##### Desventaja(s): desnormalización
- Los datos se duplican.
- Las restricciones pueden ayudar a que las copias redundantes de información se mantengan sincronizadas, lo que aumenta la complejidad del diseño de la base de datos.
- Una base de datos desnormalizada bajo una carga pesada de escrituras podría rendir peor que su contraparte normalizada.
La afinación de SQL es un tema amplio y se han escrito muchos libros como referencia.
Es importante realizar pruebas de rendimiento y perfiles para simular y descubrir cuellos de botella.
- Prueba de rendimiento - Simular situaciones de alta carga con herramientas como ab.
- Perfil - Habilitar herramientas como el registro de consultas lentas para ayudar a rastrear problemas de rendimiento.
##### Ajustar el esquema
- MySQL volca a disco en bloques contiguos para acceso rápido.
- Use
CHARen lugar deVARCHARpara campos de longitud fija. CHARpermite un acceso rápido y aleatorio, mientras que conVARCHARdebe encontrar el final de una cadena antes de pasar a la siguiente.- Use
TEXTpara grandes bloques de texto como entradas de blog.TEXTtambién permite búsquedas booleanas. Usar un campoTEXTimplica almacenar un puntero en disco que se usa para localizar el bloque de texto. - Use
INTpara números grandes hasta 2^32 o 4 mil millones. - Use
DECIMALpara moneda para evitar errores de representación en punto flotante. - Evite almacenar
BLOBSgrandes, almacene la ubicación de donde obtener el objeto en su lugar. VARCHAR(255)es el número máximo de caracteres que se pueden contar en un número de 8 bits, maximizando a menudo el uso de un byte en algunos RDBMS.- Establezca la restricción
NOT NULLdonde sea aplicable para mejorar el rendimiento de búsqueda.
- Las columnas que consulte (
SELECT,GROUP BY,ORDER BY,JOIN) podrían ser más rápidas con índices. - Los índices generalmente se representan como B-tree autoequilibrados que mantienen los datos ordenados y permiten búsquedas, acceso secuencial, inserciones y eliminaciones en tiempo logarítmico.
- Colocar un índice puede mantener los datos en memoria, requiriendo más espacio.
- Las escrituras también podrían ser más lentas ya que el índice debe actualizarse.
- Al cargar grandes cantidades de datos, puede ser más rápido deshabilitar los índices, cargar los datos y luego reconstruir los índices.
- Desnormalice donde el rendimiento lo demande.
- Dividir una tabla poniendo puntos calientes en una tabla separada para ayudar a mantenerla en memoria.
- En algunos casos, la caché de consultas podría causar problemas de rendimiento.
- Consejos para optimizar consultas MySQL
- ¿Hay una buena razón para ver VARCHAR(255) usado tan frecuentemente?
- ¿Cómo afectan los valores nulos al rendimiento?
- Registro de consultas lentas
NoSQL
NoSQL es una colección de elementos de datos representados en un almacén clave-valor, almacén de documentos, almacén de columnas anchas, o una base de datos de grafos. Los datos están desnormalizados, y las uniones generalmente se hacen en el código de la aplicación. La mayoría de los almacenes NoSQL carecen de transacciones ACID verdaderas y prefieren la consistencia eventual.
BASE se usa a menudo para describir las propiedades de las bases de datos NoSQL. En comparación con el Teorema CAP, BASE elige disponibilidad sobre consistencia.
- Básicamente disponible - el sistema garantiza disponibilidad.
- Estado blando - el estado del sistema puede cambiar con el tiempo, incluso sin entrada.
- Consistencia eventual - el sistema se volverá consistente en un período de tiempo, dado que el sistema no reciba entrada durante ese período.
#### Almacén clave-valor
Abstracción: tabla hash
Un almacén clave-valor generalmente permite lecturas y escrituras O(1) y a menudo está respaldado por memoria o SSD. Los almacenes de datos pueden mantener claves en orden lexicográfico, permitiendo una recuperación eficiente de rangos de claves. Los almacenes clave-valor pueden permitir almacenar metadatos junto con un valor.
Los almacenes clave-valor ofrecen alto rendimiento y se usan frecuentemente para modelos de datos simples o para datos que cambian rápidamente, como una capa de caché en memoria. Dado que ofrecen solo un conjunto limitado de operaciones, la complejidad se traslada a la capa de aplicación si se necesitan operaciones adicionales.
Un almacén clave-valor es la base para sistemas más complejos como un almacén de documentos y, en algunos casos, una base de datos de grafos.
##### Fuente(s) y lecturas adicionales: almacén clave-valor
- Base de datos clave-valor
- Desventajas de los almacenes clave-valor
- Arquitectura de Redis
- Arquitectura de Memcached
Abstracción: almacén clave-valor con documentos almacenados como valores
Un almacenamiento de documentos se centra en documentos (XML, JSON, binario, etc.), donde un documento almacena toda la información de un objeto dado. Los almacenes de documentos proporcionan APIs o un lenguaje de consulta para consultar basándose en la estructura interna del documento mismo. Nota, muchos almacenes clave-valor incluyen características para trabajar con los metadatos de un valor, difuminando las líneas entre estos dos tipos de almacenamiento.
Según la implementación subyacente, los documentos se organizan por colecciones, etiquetas, metadatos o directorios. Aunque los documentos pueden organizarse o agruparse juntos, los documentos pueden tener campos que son completamente diferentes entre sí.
Algunos almacenes de documentos como MongoDB y CouchDB también proporcionan un lenguaje similar a SQL para realizar consultas complejas. DynamoDB soporta tanto clave-valor como documentos.
Los almacenes de documentos ofrecen alta flexibilidad y se utilizan frecuentemente para trabajar con datos que cambian ocasionalmente.
##### Fuente(s) y lectura adicional: almacenamiento de documentos
- Base de datos orientada a documentos
- Arquitectura de MongoDB
- Arquitectura de CouchDB
- Arquitectura de Elasticsearch
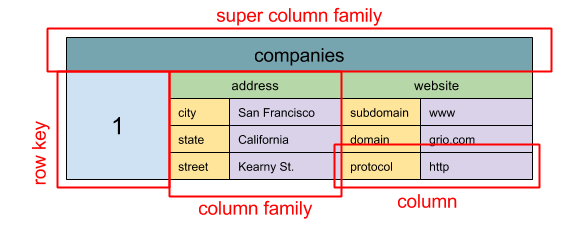
Fuente: SQL & NoSQL, una breve historia
Abstracción: mapa anidado ColumnFamily> La unidad básica de datos de un almacenamiento de columnas anchas es una columna (par nombre/valor). Una columna puede agruparse en familias de columnas (análogas a una tabla SQL). Las familias de supercolumnas agrupan aún más familias de columnas. Puedes acceder a cada columna de forma independiente con una clave de fila, y las columnas con la misma clave forman una fila. Cada valor contiene una marca de tiempo para versionado y resolución de conflictos.
Google introdujo Bigtable como el primer almacenamiento de columnas anchas, que influyó en el proyecto open-source HBase usado frecuentemente en el ecosistema Hadoop, y Cassandra de Facebook. Almacenes como BigTable, HBase y Cassandra mantienen las claves en orden lexicográfico, permitiendo una recuperación eficiente de rangos selectivos de claves.
Los almacenes de columnas anchas ofrecen alta disponibilidad y alta escalabilidad. A menudo se utilizan para conjuntos de datos muy grandes.
##### Fuente(s) y lectura adicional: almacenamiento de columnas anchas
- SQL & NoSQL, una breve historia
- Arquitectura de Bigtable
- Arquitectura de HBase
- Arquitectura de Cassandra
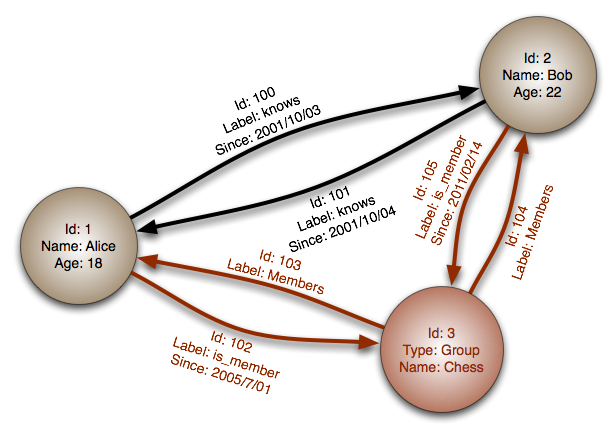
Fuente: Base de datos de grafos
Abstracción: grafo
En una base de datos de grafos, cada nodo es un registro y cada arco es una relación entre dos nodos. Las bases de datos de grafos están optimizadas para representar relaciones complejas con muchas claves foráneas o relaciones muchos a muchos.
Las bases de datos de grafos ofrecen un alto rendimiento para modelos de datos con relaciones complejas, como una red social. Son relativamente nuevas y aún no se usan ampliamente; puede ser más difícil encontrar herramientas de desarrollo y recursos. Muchos grafos solo pueden accederse con APIs REST.
##### Fuente(s) y lectura adicional: grafo
#### Fuente(s) y lectura adicional: NoSQL- Explicación de la terminología BASE
- Bases de datos NoSQL: una encuesta y guía para la decisión
- Escalabilidad
- Introducción a NoSQL
- Patrones NoSQL
SQL o NoSQL
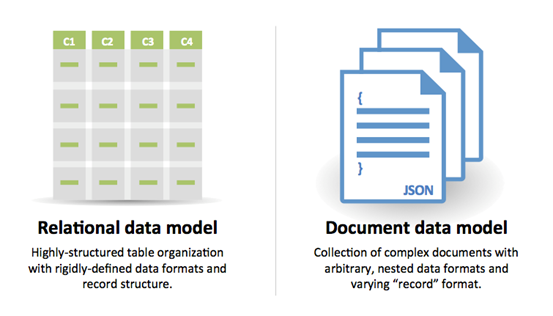
Fuente: Transición de RDBMS a NoSQL
Razones para SQL:
- Datos estructurados
- Esquema estricto
- Datos relacionales
- Necesidad de uniones complejas
- Transacciones
- Patrones claros para escalado
- Más establecido: desarrolladores, comunidad, código, herramientas, etc.
- Las búsquedas por índice son muy rápidas
- Datos semiestructurados
- Esquema dinámico o flexible
- Datos no relacionales
- No necesita uniones complejas
- Almacenar muchos TB (o PB) de datos
- Carga de trabajo muy intensiva en datos
- Muy alto rendimiento para IOPS
- Ingesta rápida de datos de clickstream y registros
- Datos de tablas de clasificación o puntuación
- Datos temporales, como un carrito de compras
- Tablas frecuentemente accedidas ('calientes')
- Tablas de metadatos/búsqueda
Caché
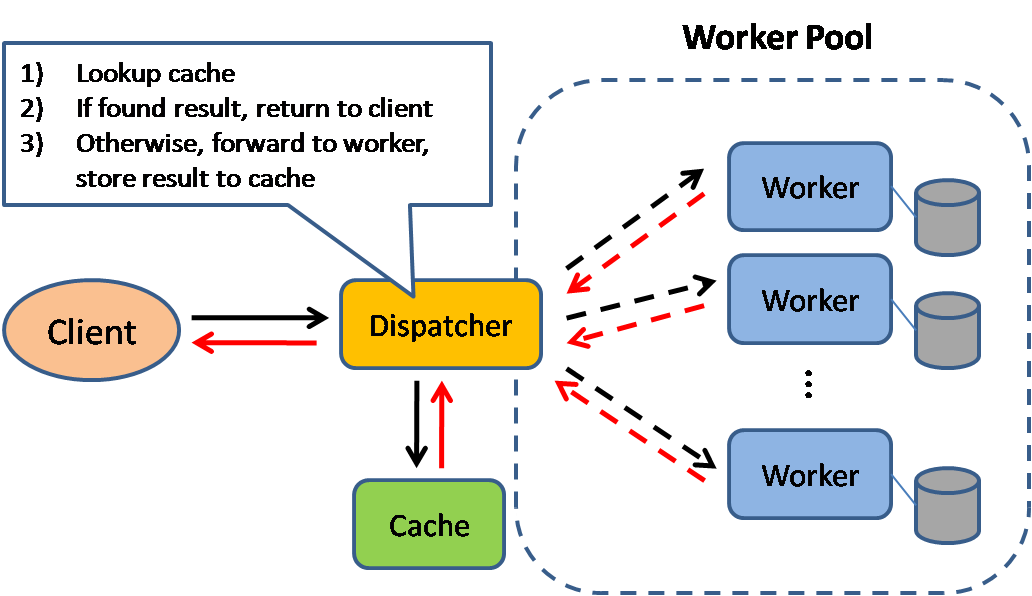
Fuente: Patrones de diseño de sistemas escalables
El almacenamiento en caché mejora los tiempos de carga de la página y puede reducir la carga en sus servidores y bases de datos. En este modelo, el despachador primero buscará si la solicitud se ha realizado antes e intentará encontrar el resultado previo para devolverlo, con el fin de ahorrar la ejecución real.
Las bases de datos a menudo se benefician de una distribución uniforme de lecturas y escrituras a través de sus particiones. Los elementos populares pueden sesgar la distribución, causando cuellos de botella. Colocar una caché delante de una base de datos puede ayudar a absorber cargas desiguales y picos de tráfico.
Caché del cliente
Las cachés pueden estar ubicadas en el lado del cliente (SO o navegador), lado del servidor o en una capa de caché distinta.
Caché CDN
Las CDNs se consideran un tipo de caché.
Caché del servidor web
Los proxy inversos y cachés como Varnish pueden servir contenido estático y dinámico directamente. Los servidores web también pueden almacenar en caché solicitudes, devolviendo respuestas sin tener que contactar con servidores de aplicaciones.
Caché de base de datos
Su base de datos generalmente incluye algún nivel de caché en una configuración predeterminada, optimizada para un caso de uso genérico. Ajustar estas configuraciones para patrones de uso específicos puede mejorar aún más el rendimiento.
Caché de aplicación
Las cachés en memoria como Memcached y Redis son almacenes clave-valor entre su aplicación y su almacenamiento de datos. Dado que los datos se mantienen en RAM, es mucho más rápido que las bases de datos típicas donde los datos se almacenan en disco. La RAM es más limitada que el disco, por lo que algoritmos de invalidación de caché como el menos utilizado recientemente (LRU)) pueden ayudar a invalidar entradas 'frías' y mantener datos 'calientes' en RAM.
Redis tiene las siguientes características adicionales:
- Opción de persistencia
- Estructuras de datos integradas como conjuntos ordenados y listas
- Nivel de fila
- Nivel de consulta
- Objetos serializables completamente formados
- HTML completamente renderizado
Caché a nivel de consulta de base de datos
Cada vez que consultas la base de datos, hashea la consulta como una clave y almacena el resultado en la caché. Este enfoque sufre problemas de expiración:
- Difícil eliminar un resultado en caché con consultas complejas
- Si un dato cambia, como una celda de tabla, necesitas eliminar todas las consultas en caché que podrían incluir la celda cambiada
Caché a nivel de objeto
Ve tus datos como un objeto, similar a lo que haces con el código de tu aplicación. Haz que tu aplicación arme el conjunto de datos desde la base de datos en una instancia de clase o una(s) estructura(s) de datos:
- Elimina el objeto de la caché si sus datos subyacentes han cambiado
- Permite procesamiento asíncrono: los workers arman objetos consumiendo el último objeto en caché
- Sesiones de usuario
- Páginas web completamente renderizadas
- Flujos de actividad
- Datos de grafo de usuario
Cuándo actualizar la caché
Dado que solo puedes almacenar una cantidad limitada de datos en caché, deberás determinar qué estrategia de actualización de caché funciona mejor para tu caso de uso.
#### Cache-aside
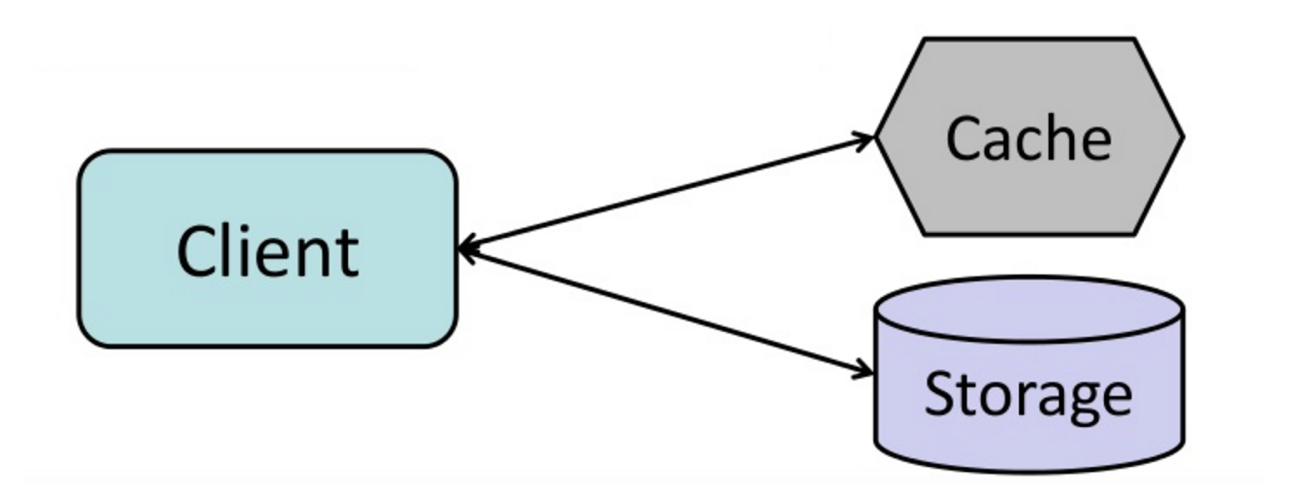
Fuente: De caché a grid de datos en memoria
La aplicación es responsable de leer y escribir desde el almacenamiento. La caché no interactúa directamente con el almacenamiento. La aplicación hace lo siguiente:
- Busca la entrada en caché, resultando en un fallo de caché
- Carga la entrada desde la base de datos
- Añade la entrada a la caché
- Devuelve la entrada
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached generalmente se usa de esta manera.
Las lecturas posteriores de datos agregados a la caché son rápidas. Cache-aside también se conoce como carga perezosa. Solo se almacena en caché los datos solicitados, lo que evita llenar la caché con datos que no se solicitan.
##### Desventaja(s): cache-aside
- Cada fallo de caché resulta en tres viajes, lo que puede causar una demora notable.
- Los datos pueden volverse obsoletos si se actualizan en la base de datos. Este problema se mitiga configurando un tiempo de vida (TTL) que fuerza una actualización de la entrada de caché, o usando write-through.
- Cuando un nodo falla, es reemplazado por un nodo nuevo y vacío, aumentando la latencia.
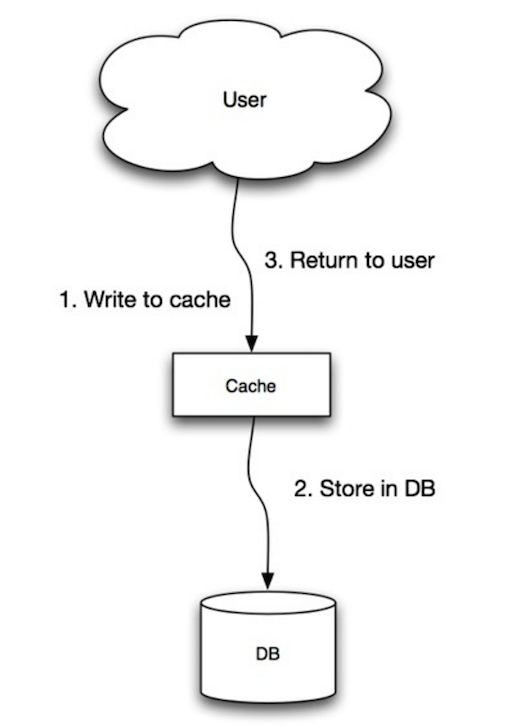
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones
La aplicación usa la caché como el almacén principal de datos, leyendo y escribiendo datos en ella, mientras que la caché es responsable de leer y escribir en la base de datos:
- La aplicación agrega/actualiza la entrada en la caché
- La caché escribe sincrónicamente la entrada en el almacén de datos
- Retorna
set_user(12345, {"foo":"bar"})Código de caché:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)Write-through es una operación general lenta debido a la operación de escritura, pero las lecturas posteriores de datos recién escritos son rápidas. Los usuarios generalmente son más tolerantes a la latencia al actualizar datos que al leer datos. Los datos en la caché no están obsoletos.
##### Desventaja(s): write through
- Cuando se crea un nuevo nodo debido a una falla o escalado, el nuevo nodo no almacenará en caché las entradas hasta que la entrada se actualice en la base de datos. Cache-aside junto con write through puede mitigar este problema.
- La mayoría de los datos escritos podrían nunca ser leídos, lo que se puede minimizar con un TTL.
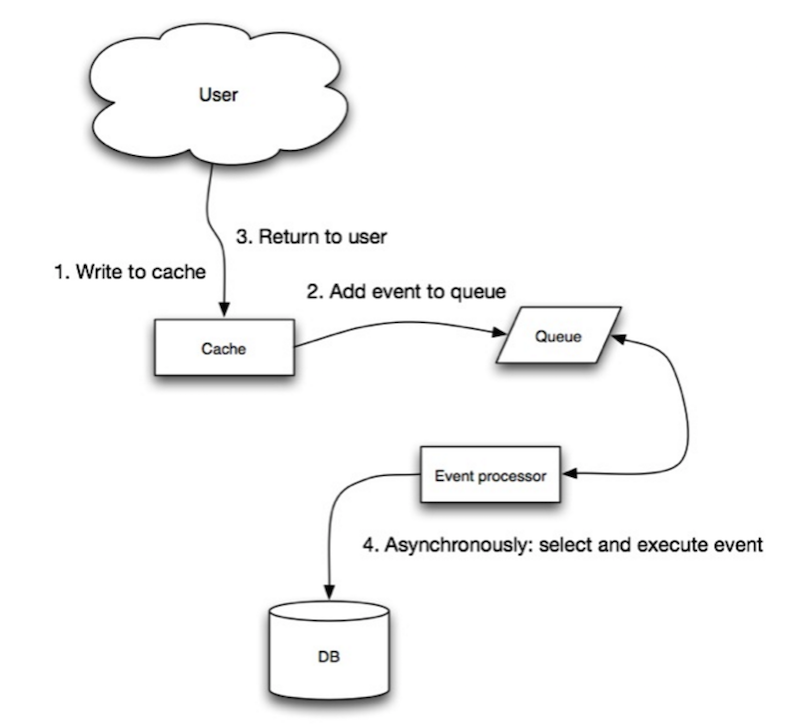
Fuente: Escalabilidad, disponibilidad, estabilidad, patrones
En write-behind, la aplicación hace lo siguiente:
- Añadir/actualizar entrada en caché
- Escribir la entrada de forma asíncrona en el almacén de datos, mejorando el rendimiento de escritura
- Podría haber pérdida de datos si la caché se cae antes de que sus contenidos lleguen al almacén de datos.
- Es más complejo implementar write-behind que implementar cache-aside o write-through.
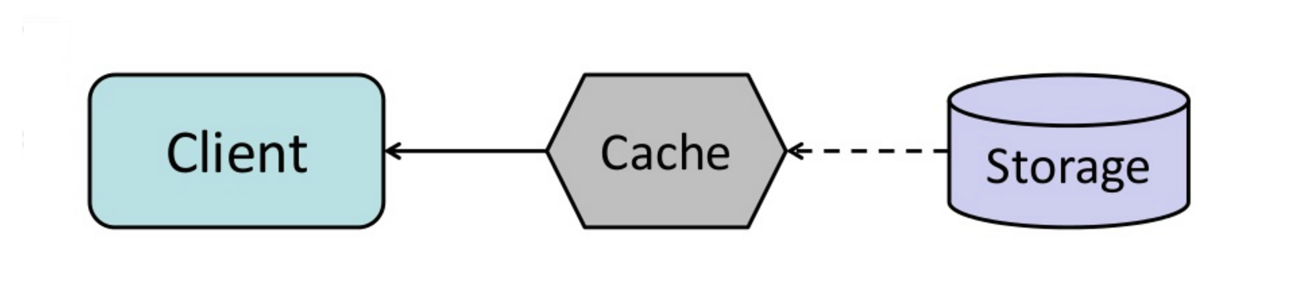
Fuente: De caché a grid de datos en memoria
Puede configurar la caché para actualizar automáticamente cualquier entrada de caché recientemente accedida antes de su expiración.
Refresh-ahead puede resultar en una latencia reducida frente a read-through si la caché puede predecir con precisión qué elementos probablemente se necesitarán en el futuro.
##### Desventaja(s): refresh-ahead
- No predecir con precisión qué elementos serán necesarios en el futuro puede resultar en un rendimiento reducido en comparación con no usar refresh-ahead.
Desventaja(s): caché
- Es necesario mantener la consistencia entre las cachés y la fuente de la verdad, como la base de datos, mediante invalidación de caché.
- La invalidación de caché es un problema difícil, existe una complejidad adicional asociada a cuándo actualizar la caché.
- Es necesario hacer cambios en la aplicación, como agregar Redis o memcached.
Fuente(s) y lecturas adicionales
- De caché a grid de datos en memoria
- Patrones de diseño de sistemas escalables
- Introducción a la arquitectura de sistemas para escala
- Escalabilidad, disponibilidad, estabilidad, patrones
- Escalabilidad
- Estrategias AWS ElastiCache
- Wikipedia)
Asincronismo
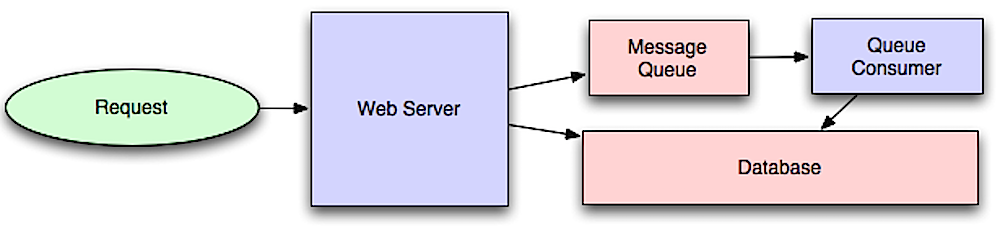
Fuente: Introducción a la arquitectura de sistemas para escala
Los flujos de trabajo asíncronos ayudan a reducir los tiempos de respuesta para operaciones costosas que de otro modo se realizarían en línea. También pueden ayudar realizando trabajo que consume tiempo por adelantado, como la agregación periódica de datos.
Colas de mensajes
Las colas de mensajes reciben, retienen y entregan mensajes. Si una operación es demasiado lenta para realizarse en línea, puede usar una cola de mensajes con el siguiente flujo de trabajo:
- Una aplicación publica un trabajo en la cola y luego notifica al usuario sobre el estado del trabajo
- Un trabajador recoge el trabajo de la cola, lo procesa y luego señala que el trabajo está completo
Redis es útil como un broker de mensajes simple, pero los mensajes pueden perderse.
RabbitMQ es popular pero requiere que te adaptes al protocolo 'AMQP' y administres tus propios nodos.
Amazon SQS está alojado pero puede tener alta latencia y existe la posibilidad de que los mensajes se entreguen dos veces.
Colas de tareas
Las colas de tareas reciben tareas y sus datos relacionados, las ejecutan y luego entregan sus resultados. Pueden soportar programación y pueden usarse para ejecutar trabajos computacionalmente intensivos en segundo plano.
Celery tiene soporte para programación y principalmente tiene soporte para python.
Presión de retorno
Si las colas comienzan a crecer significativamente, el tamaño de la cola puede ser mayor que la memoria, lo que resulta en fallos de caché, lecturas de disco y un rendimiento aún más lento. La presión de retorno puede ayudar limitando el tamaño de la cola, manteniendo así una alta tasa de rendimiento y buenos tiempos de respuesta para los trabajos ya en la cola. Una vez que la cola se llena, los clientes reciben un código de estado de servidor ocupado o HTTP 503 para intentar de nuevo más tarde. Los clientes pueden reintentar la solicitud en otro momento, quizás con retroceso exponencial.
Desventaja(s): asincronía
- Casos de uso como cálculos económicos y flujos de trabajo en tiempo real podrían ser más adecuados para operaciones síncronas, ya que introducir colas puede añadir retrasos y complejidad.
Fuente(s) y lectura adicional
- Todo es un juego de números
- Aplicando presión de retorno cuando está sobrecargado
- Ley de Little
- ¿Cuál es la diferencia entre una cola de mensajes y una cola de tareas?
Comunicación
{kind=link}
{kind=link}
Protocolo de transferencia de hipertexto (HTTP)
HTTP es un método para codificar y transportar datos entre un cliente y un servidor. Es un protocolo de solicitud/respuesta: los clientes emiten solicitudes y los servidores emiten respuestas con contenido relevante e información de estado de finalización sobre la solicitud. HTTP es autónomo, permitiendo que solicitudes y respuestas fluyan a través de muchos routers y servidores intermedios que realizan balanceo de carga, almacenamiento en caché, cifrado y compresión.
Una solicitud HTTP básica consiste en un verbo (método) y un recurso (endpoint). A continuación se muestran verbos HTTP comunes:
| Verbo | Descripción | Idempotente* | Seguro | Cacheable | |---|---|---|---|---| | GET | Lee un recurso | Sí | Sí | Sí | | POST | Crea un recurso o activa un proceso que maneja datos | No | No | Sí si la respuesta contiene información de frescura | | PUT | Crea o reemplaza un recurso | Sí | No | No | | PATCH | Actualiza parcialmente un recurso | No | No | Sí si la respuesta contiene información de frescura | | DELETE | Elimina un recurso | Sí | No | No |
*Puede llamarse muchas veces sin resultados diferentes.
HTTP es un protocolo de capa de aplicación que se basa en protocolos de nivel inferior como TCP y UDP.
#### Fuente(s) y lectura adicional: HTTP
Protocolo de control de transmisión (TCP)
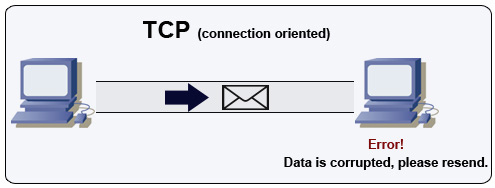
Fuente: Cómo hacer un juego multijugador
TCP es un protocolo orientado a conexión sobre una red IP. La conexión se establece y termina usando un handshake. Todos los paquetes enviados están garantizados a llegar al destino en el orden original y sin corrupción mediante:
- Números de secuencia y campos de checksum para cada paquete
- Paquetes de reconocimiento) y retransmisión automática
Para asegurar un alto rendimiento, los servidores web pueden mantener un gran número de conexiones TCP abiertas, lo que resulta en un alto uso de memoria. Puede ser costoso tener un gran número de conexiones abiertas entre hilos del servidor web y, por ejemplo, un servidor memcached. El pooling de conexiones puede ayudar además de cambiar a UDP cuando sea aplicable.
TCP es útil para aplicaciones que requieren alta fiabilidad pero son menos críticas en tiempo. Algunos ejemplos incluyen servidores web, información de bases de datos, SMTP, FTP y SSH.
Usa TCP sobre UDP cuando:
- Necesites que todos los datos lleguen intactos
- Quieras hacer automáticamente una mejor estimación del uso del rendimiento de la red
Protocolo de datagramas de usuario (UDP)
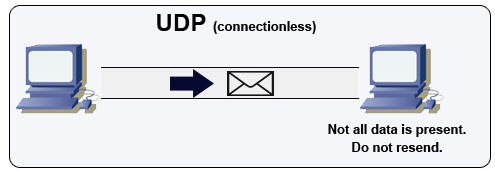
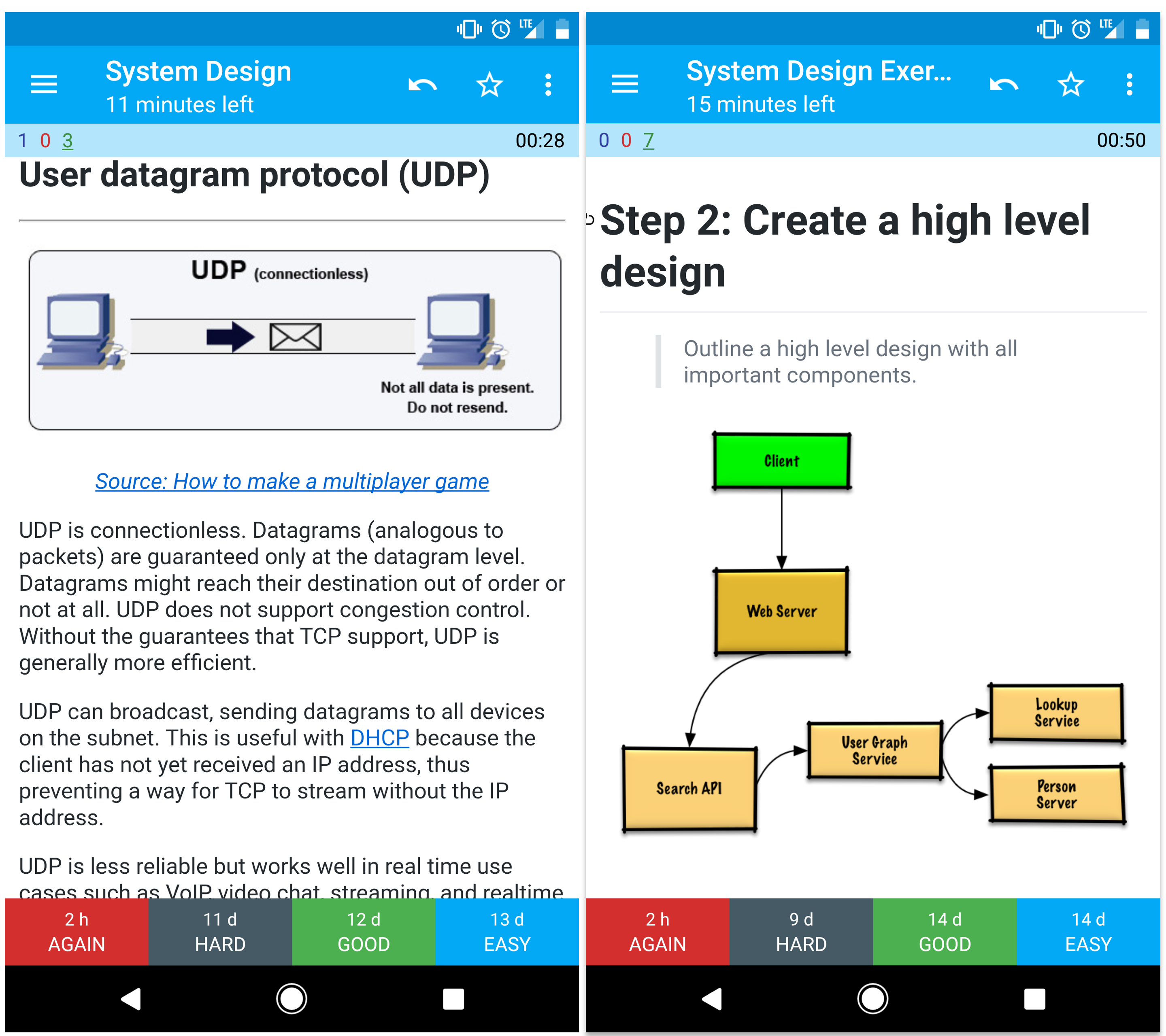
Fuente: Cómo hacer un juego multijugador
UDP es sin conexión. Los datagramas (análogos a paquetes) están garantizados solo a nivel de datagrama. Los datagramas pueden llegar a su destino fuera de orden o no llegar en absoluto. UDP no soporta control de congestión. Sin las garantías que soporta TCP, UDP es generalmente más eficiente.
UDP puede hacer broadcast, enviando datagramas a todos los dispositivos en la subred. Esto es útil con DHCP porque el cliente aún no ha recibido una dirección IP, lo que impide una manera para que TCP transmita sin la dirección IP.
UDP es menos confiable pero funciona bien en casos de uso en tiempo real como VoIP, videollamadas, streaming y juegos multijugador en tiempo real.
Usa UDP en lugar de TCP cuando:
- Necesitas la latencia más baja
- Los datos tardíos son peores que la pérdida de datos
- Quieres implementar tu propia corrección de errores
- Redes para programación de juegos
- Diferencias clave entre los protocolos TCP y UDP
- Diferencia entre TCP y UDP
- Protocolo de control de transmisión
- Protocolo de datagramas de usuario
- Escalando memcache en Facebook
Llamada a procedimiento remoto (RPC)
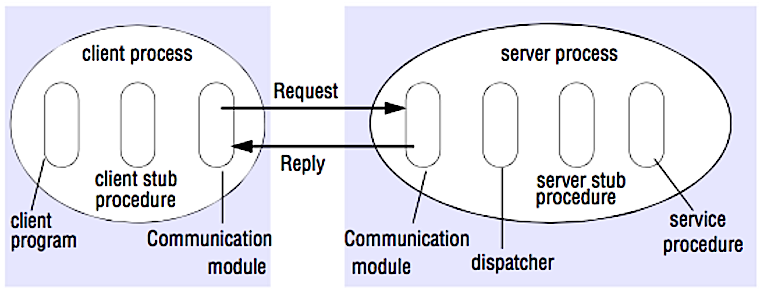
Fuente: Crack the system design interview
En una RPC, un cliente hace que un procedimiento se ejecute en un espacio de direcciones diferente, usualmente un servidor remoto. El procedimiento está codificado como si fuera una llamada a procedimiento local, abstrayendo los detalles de cómo comunicarse con el servidor desde el programa cliente. Las llamadas remotas suelen ser más lentas y menos confiables que las llamadas locales, por lo que es útil distinguir las llamadas RPC de las llamadas locales. Los frameworks RPC populares incluyen Protobuf, Thrift, y Avro.
RPC es un protocolo de solicitud-respuesta:
- Programa cliente - Llama al procedimiento stub del cliente. Los parámetros se apilan en la pila como en una llamada a procedimiento local.
- Procedimiento stub del cliente - Empaqueta (marshal) el id del procedimiento y los argumentos en un mensaje de solicitud.
- Módulo de comunicación del cliente - El SO envía el mensaje desde el cliente al servidor.
- Módulo de comunicación del servidor - El SO pasa los paquetes entrantes al procedimiento stub del servidor.
- Procedimiento stub del servidor - Desempaqueta (unmarshal) los resultados, llama al procedimiento del servidor que coincide con el id del procedimiento y pasa los argumentos dados.
- La respuesta del servidor repite los pasos anteriores en orden inverso.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC se centra en exponer comportamientos. Los RPC a menudo se utilizan por razones de rendimiento en comunicaciones internas, ya que puedes crear llamadas nativas a medida para ajustarlas mejor a tus casos de uso.
Elige una biblioteca nativa (también conocida como SDK) cuando:
- Conozcas tu plataforma objetivo.
- Quieras controlar cómo se accede a tu "lógica".
- Quieras controlar cómo se maneja el control de errores fuera de tu biblioteca.
- El rendimiento y la experiencia del usuario final sean tu principal preocupación.
#### Desventaja(s): RPC
- Los clientes RPC se vuelven fuertemente acoplados a la implementación del servicio.
- Se debe definir una nueva API para cada nueva operación o caso de uso.
- Puede ser difícil depurar RPC.
- Puede que no puedas aprovechar tecnologías existentes directamente. Por ejemplo, podría requerir esfuerzo adicional asegurar que las llamadas RPC se almacenen en caché adecuadamente en servidores de caché como Squid.
Transferencia de estado representacional (REST)
REST es un estilo arquitectónico que impone un modelo cliente/servidor donde el cliente actúa sobre un conjunto de recursos gestionados por el servidor. El servidor proporciona una representación de recursos y acciones que pueden manipular o obtener una nueva representación de recursos. Toda la comunicación debe ser sin estado y cacheable.
Hay cuatro cualidades de una interfaz RESTful:
- Identificar recursos (URI en HTTP) - usar el mismo URI independientemente de la operación.
- Cambiar con representaciones (Verbos en HTTP) - usar verbos, encabezados y cuerpo.
- Mensaje de error auto-descriptivo (respuesta de estado en HTTP) - usar códigos de estado, no reinventar la rueda.
- HATEOAS (interfaz HTML para HTTP) - tu servicio web debe ser completamente accesible en un navegador.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
REST se centra en exponer datos. Minimiza el acoplamiento entre cliente/servidor y se utiliza a menudo para APIs HTTP públicas. REST utiliza un método más genérico y uniforme para exponer recursos a través de URIs, representación mediante encabezados y acciones a través de verbos como GET, POST, PUT, DELETE y PATCH. Al ser sin estado, REST es ideal para escalado horizontal y particionamiento.
#### Desventaja(s): REST
- Al estar REST centrado en exponer datos, puede no ser adecuado si los recursos no están organizados naturalmente o accedidos en una jerarquía simple. Por ejemplo, devolver todos los registros actualizados de la última hora que coincidan con un conjunto particular de eventos no se expresa fácilmente como una ruta. Con REST, es probable que se implemente con una combinación de ruta URI, parámetros de consulta y posiblemente el cuerpo de la solicitud.
- REST típicamente se basa en algunos verbos (GET, POST, PUT, DELETE y PATCH) que a veces no encajan en tu caso de uso. Por ejemplo, mover documentos expirados a la carpeta de archivo podría no encajar claramente dentro de estos verbos.
- Obtener recursos complicados con jerarquías anidadas requiere múltiples viajes de ida y vuelta entre cliente y servidor para renderizar vistas individuales, p. ej., obtener el contenido de una entrada de blog y los comentarios sobre esa entrada. Para aplicaciones móviles que operan en condiciones de red variables, estos múltiples viajes son altamente indeseables.
- Con el tiempo, se pueden añadir más campos a una respuesta de API y los clientes antiguos recibirán todos los nuevos campos de datos, incluso aquellos que no necesitan, lo que hace que el tamaño de la carga útil se incremente y provoque latencias mayores.
Comparación de llamadas RPC y REST
| Operación | RPC | REST |
|---|---|---|
| Registro | POST /signup | POST /persons |
| Renuncia | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Leer una persona | GET /readPerson?personid=1234 | GET /persons/1234 |
| Leer lista de ítems de una persona | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Añadir un ítem a la lista de una persona | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Actualizar un ítem | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Eliminar un ítem | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Fuente: ¿Realmente sabes por qué prefieres REST sobre RPC?
#### Fuente(s) y lecturas adicionales: REST y RPC
- ¿Realmente sabes por qué prefieres REST sobre RPC?
- ¿Cuándo son más apropiados enfoques tipo RPC que REST?
- REST vs JSON-RPC
- Desmitificando los mitos de RPC y REST
- ¿Cuáles son las desventajas de usar REST?
- Supera la entrevista de diseño de sistemas
- Thrift
- Por qué REST para uso interno y no RPC
Seguridad
Esta sección podría usar algunas actualizaciones. ¡Considera contribuir!
La seguridad es un tema amplio. A menos que tengas una experiencia considerable, un conocimiento en seguridad, o estés aplicando para un puesto que requiera conocimientos de seguridad, probablemente no necesites saber más que lo básico:
- Encripta en tránsito y en reposo.
- Sanitiza todas las entradas de usuario o cualquier parámetro de entrada expuesto al usuario para prevenir XSS y inyección SQL.
- Usa consultas parametrizadas para prevenir la inyección SQL.
- Usa el principio de mínimo privilegio.
Fuente(s) y lectura adicional
Apéndice
A veces se te pedirá hacer estimaciones 'rápidas'. Por ejemplo, podrías necesitar determinar cuánto tiempo tomará generar 100 miniaturas de imágenes desde el disco o cuánta memoria ocupará una estructura de datos. La tabla de potencias de dos y los números de latencia que todo programador debería conocer son referencias útiles.
Tabla de potencias de dos
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TBNúmeros de latencia que todo programador debe conocer
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- Lectura secuencial desde HDD a 30 MB/s
- Lectura secuencial desde Ethernet de 1 Gbps a 100 MB/s
- Lectura secuencial desde SSD a 1 GB/s
- Lectura secuencial desde memoria principal a 4 GB/s
- 6-7 viajes de ida y vuelta en todo el mundo por segundo
- 2,000 viajes de ida y vuelta por segundo dentro de un centro de datos
#### Fuente(s) y lectura adicional
- Números de latencia que todo programador debe conocer - 1
- Números de latencia que todo programador debe conocer - 2
- Diseños, lecciones y consejos de la construcción de sistemas distribuidos grandes
- Consejos de ingeniería de software al construir sistemas distribuidos a gran escala
Preguntas adicionales para entrevistas de diseño de sistemas
Preguntas comunes en entrevistas de diseño de sistemas, con enlaces a recursos sobre cómo resolver cada una.
| Pregunta | Referencia(s) |
|---|---|
| Diseñar un servicio de sincronización de archivos como Dropbox | youtube.com |
| Diseñar un motor de búsqueda como Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Diseñar un rastreador web escalable como Google | quora.com |
| Diseñar Google docs | code.google.com
neil.fraser.name |
| Diseñar un almacén clave-valor como Redis | slideshare.net |
| Diseñar un sistema de caché como Memcached | slideshare.net |
| Diseñar un sistema de recomendación como el de Amazon | hulu.com
ijcai13.org |
| Diseñar un sistema tinyurl como Bitly | n00tc0d3r.blogspot.com |
| Diseñar una app de chat como WhatsApp | highscalability.com |
| Diseñar un sistema para compartir fotos como Instagram | highscalability.com
highscalability.com |
| Diseñar la función de noticias en Facebook | quora.com
quora.com
slideshare.net |
| Diseñar la función de línea de tiempo en Facebook | facebook.com
highscalability.com |
| Diseñar la función de chat en Facebook | erlang-factory.com
facebook.com |
| Diseñar una función de búsqueda en grafo como la de Facebook | facebook.com
facebook.com
facebook.com |
| Diseñar una red de entrega de contenido como CloudFlare | figshare.com |
| Diseñar un sistema de temas de tendencia como el de Twitter | michael-noll.com
snikolov .wordpress.com |
| Diseñar un sistema de generación de ID aleatorio | blog.twitter.com
github.com |
| Devolver las k solicitudes principales durante un intervalo de tiempo | cs.ucsb.edu
wpi.edu |
| Diseñar un sistema que sirva datos desde múltiples centros de datos | highscalability.com |
| Diseñar un juego de cartas multijugador en línea | indieflashblog.com
buildnewgames.com |
| Diseñar un sistema de recolección de basura | stuffwithstuff.com
washington.edu |
| Diseñar un limitador de tasa para API | https://stripe.com/blog/ |
| Diseñar una bolsa de valores (como NASDAQ o Binance) | Jane Street
Implementación en Golang
Implementación en Go |
| Añadir una pregunta de diseño de sistema | Contribuir |
Arquitecturas del mundo real
Artículos sobre cómo se diseñan los sistemas en el mundo real.
Fuente: Líneas de tiempo de Twitter a gran escala
No te centres en los detalles minuciosos de los siguientes artículos, en cambio:
- Identifica principios compartidos, tecnologías comunes y patrones dentro de estos artículos
- Estudia qué problemas resuelve cada componente, dónde funciona, dónde no
- Revisa las lecciones aprendidas
Arquitecturas de empresas
| Empresa | Referencia(s) |
|---|---|
| Amazon | Arquitectura de Amazon |
| Cinchcast | Produciendo 1,500 horas de audio cada día |
| DataSift | Minería de datos en tiempo real a 120,000 tweets por segundo |
| Dropbox | Cómo hemos escalado Dropbox |
| ESPN | Operando a 100,000 duh nuh nuhs por segundo |
| Google | Arquitectura de Google |
| Instagram | 14 millones de usuarios, terabytes de fotos
Qué impulsa Instagram |
| Justin.tv | Arquitectura de transmisión de video en vivo de Justin.Tv |
| Facebook | Escalando memcached en Facebook
TAO: Almacén de datos distribuido de Facebook para el grafo social
Almacenamiento de fotos de Facebook
Cómo Facebook transmite en vivo a 800,000 espectadores simultáneos |
| Flickr | Arquitectura de Flickr |
| Mailbox | De 0 a un millón de usuarios en 6 semanas |
| Netflix | Una vista de 360 grados de toda la pila de Netflix
Netflix: Qué sucede cuando presionas reproducir |
| Pinterest | De 0 a decenas de miles de millones de vistas de página al mes
18 millones de visitantes, crecimiento de 10x, 12 empleados |
| Playfish | 50 millones de usuarios mensuales y creciendo |
| PlentyOfFish | Arquitectura de PlentyOfFish |
| Salesforce | Cómo manejan 1.3 mil millones de transacciones por día |
| Stack Overflow | Arquitectura de Stack Overflow |
| TripAdvisor | 40M visitantes, 200M vistas dinámicas de página, 30TB de datos |
| Tumblr | 15 mil millones de vistas de página al mes |
| Twitter | Haciendo Twitter 10,000 por ciento más rápido
Almacenando 250 millones de tweets al día usando MySQL
150M usuarios activos, 300K QPS, un firehose de 22 MB/s
Líneas de tiempo a escala
Datos grandes y pequeños en Twitter
Operaciones en Twitter: escalando más allá de 100 millones de usuarios
Cómo Twitter maneja 3,000 imágenes por segundo |
| Uber | Cómo Uber escala su plataforma de mercado en tiempo real
Lecciones aprendidas al escalar Uber a 2000 ingenieros, 1000 servicios y 8000 repositorios Git |
| WhatsApp | La arquitectura de WhatsApp que Facebook compró por 19 mil millones de dólares |
| YouTube | Escalabilidad de YouTube
Arquitectura de YouTube |
Blogs de ingeniería de empresas
Arquitecturas para las empresas con las que estás entrevistando.>
Las preguntas que encuentres podrían ser del mismo dominio.
- Ingeniería de Airbnb
- Desarrolladores de Atlassian
- Blog de AWS
- Blog de Ingeniería de Bitly
- Blogs de Box
- Blog de Desarrolladores de Cloudera
- Blog Técnico de Dropbox
- Ingeniería en Quora
- Blog Técnico de Ebay
- Blog Técnico de Evernote
- Etsy Código como Artesanía
- Ingeniería de Facebook
- Código de Flickr
- Blog de Ingeniería de Foursquare
- Blog de Ingeniería de GitHub
- Blog de Investigación de Google
- Blog de Ingeniería de Groupon
- Blog de Ingeniería de Heroku
- Blog de Ingeniería de Hubspot
- Alta Escalabilidad
- Ingeniería de Instagram
- Blog de Software de Intel
- Blog Técnico de Jane Street
- Ingeniería de LinkedIn
- Ingeniería de Microsoft
- Ingeniería Python de Microsoft
- Blog Técnico de Netflix
- Blog para Desarrolladores de Paypal
- Blog de Ingeniería de Pinterest
- Blog de Reddit
- Blog de Ingeniería de Salesforce
- Blog de Ingeniería de Slack
- Laboratorios Spotify
- Blog de Ingeniería de Stripe
- Blog de Ingeniería de Twilio
- Ingeniería de Twitter
- Blog de Ingeniería de Uber
- Blog de Ingeniería de Yahoo
- Blog de Ingeniería de Yelp
- Blog de Ingeniería de Zynga
¿Quieres agregar un blog? Para evitar trabajo duplicado, considera añadir el blog de tu empresa al siguiente repositorio:
En desarrollo
¿Interesado en agregar una sección o ayudar a completar una en progreso? ¡Contribuye!
- Computación distribuida con MapReduce
- Hashing consistente
- Scatter gather
- Contribuye
Créditos
Los créditos y fuentes están proporcionados a lo largo de este repositorio.
Agradecimientos especiales a:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Información de contacto
No dude en contactarme para discutir cualquier problema, pregunta o comentario.
Mi información de contacto se puede encontrar en mi página de GitHub.
Licencia
Estoy proporcionando el código y los recursos en este repositorio bajo una licencia de código abierto. Debido a que este es mi repositorio personal, la licencia que recibe para mi código y recursos es de mi parte y no de mi empleador (Facebook).
Derechos de autor 2017 Donne Martin
Licencia Internacional Creative Commons Atribución 4.0 (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---