English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Hilf mit, diesen Leitfaden zu übersetzen!
Das System Design Primer

Motivation
Lerne, wie man groß angelegte Systeme entwirft.>
Vorbereitung auf das Systemdesign-Interview.
Lerne, wie man groß angelegte Systeme entwirft
Das Erlernen der Skalierung von Systemen hilft dir, ein besserer Ingenieur zu werden.
Systemdesign ist ein breit gefächertes Thema. Es gibt eine riesige Menge an Ressourcen, die im Web verstreut sind zu Prinzipien des Systemdesigns.
Dieses Repository ist eine organisierte Sammlung von Ressourcen, die dir helfen, Systeme im großen Maßstab zu bauen.
Lerne von der Open-Source-Community
Dies ist ein fortlaufend aktualisiertes Open-Source-Projekt.
Beiträge sind willkommen!
Vorbereitung auf das Systemdesign-Interview
Neben Coding-Interviews ist Systemdesign ein notwendiger Bestandteil des technischen Bewerbungsprozesses bei vielen Tech-Unternehmen.
Übe gängige Systemdesign-Interviewfragen und vergleiche deine Ergebnisse mit Beispiellösungen: Diskussionen, Code und Diagramme.
Zusätzliche Themen zur Interviewvorbereitung:
- Lernleitfaden
- Wie man eine Systemdesign-Interviewfrage angeht
- Systemdesign-Interviewfragen, mit Lösungen
- Objektorientierte Design-Interviewfragen, mit Lösungen
- Zusätzliche Systemdesign-Interviewfragen
Anki-Lernkarten
Die bereitgestellten Anki-Lernkartendecks nutzen verteiltes Wiederholen, um Ihnen beim Behalten wichtiger Systemdesign-Konzepte zu helfen.
Ideal für unterwegs.Coding Resource: Interaktive Programmieraufgaben
Suchen Sie nach Ressourcen, um sich auf das Coding-Interview vorzubereiten?
Werfen Sie einen Blick auf das Schwester-Repository Interactive Coding Challenges, das ein weiteres Anki-Deck enthält:
Mitwirken
Lernen Sie von der Community.
Sie können gerne Pull-Requests einreichen, um zu helfen:
- Fehler beheben
- Abschnitte verbessern
- Neue Abschnitte hinzufügen
- Übersetzen
Siehe die Mitwirkungsrichtlinien.
Index der Themen zum Systemdesign
Zusammenfassungen verschiedener Systemdesign-Themen, einschließlich Vor- und Nachteilen. Alles ist ein Kompromiss.>
Jeder Abschnitt enthält Links zu weiterführenden Ressourcen.
- Systemdesign-Themen: Hier starten
- Schritt 1: Sehen Sie sich die Skalierbarkeits-Videovorlesung an
- Schritt 2: Lesen Sie den Skalierbarkeits-Artikel
- Nächste Schritte
- Performance vs Skalierbarkeit
- Latenz vs Durchsatz
- Verfügbarkeit vs Konsistenz
- CAP-Theorem
- CP - Konsistenz und Partitionstoleranz
- AP - Verfügbarkeit und Partitionstoleranz
- Konsistenzmuster
- Schwache Konsistenz
- Eventuelle Konsistenz
- Starke Konsistenz
- Verfügbarkeitsmuster
- Failover
- Replikation
- Verfügbarkeit in Zahlen
- Domain Name System
- Content Delivery Network
- Push-CDNs
- Pull-CDNs
- Load Balancer
- Aktiv-passiv
- Aktiv-aktiv
- Layer-4-Lastverteilung
- Layer-7-Lastverteilung
- Horizontale Skalierung
- Reverse Proxy (Webserver)
- Lastverteiler vs Reverse Proxy
- Application Layer
- Microservices
- Service Discovery
- Datenbank
- Relationales Datenbankmanagementsystem (RDBMS)
- Master-Slave-Replikation
- Master-Master-Replikation
- Föderation
- Sharding
- Denormalisierung
- SQL-Tuning
- NoSQL
- Key-Value-Store
- Dokumenten-Store
- Wide Column Store
- Graphdatenbank
- SQL oder NoSQL
- Cache
- Client-Caching
- CDN-Caching
- Webserver-Caching
- Datenbank-Caching
- Anwendungs-Caching
- Caching auf Datenbankabfrage-Ebene
- Caching auf Objektebene
- Wann wird der Cache aktualisiert
- Cache-aside
- Write-through
- Write-behind (Write-back)
- Refresh-ahead
- Asynchronität
- Message Queues
- Aufgabenwarteschlangen
- Backpressure
- Kommunikation
- Transmission Control Protocol (TCP)
- User Datagram Protocol (UDP)
- Remote Procedure Call (RPC)
- Representational State Transfer (REST)
- Sicherheit
- Anhang
- Zweierpotenztabelle
- Latenzzahlen, die jeder Programmierer kennen sollte
- Weitere Systemdesign-Interviewfragen
- Reale Architekturen
- Unternehmensarchitekturen
- Engineering-Blogs von Unternehmen
- In Entwicklung
- Danksagungen
- Kontaktinformationen
- Lizenz
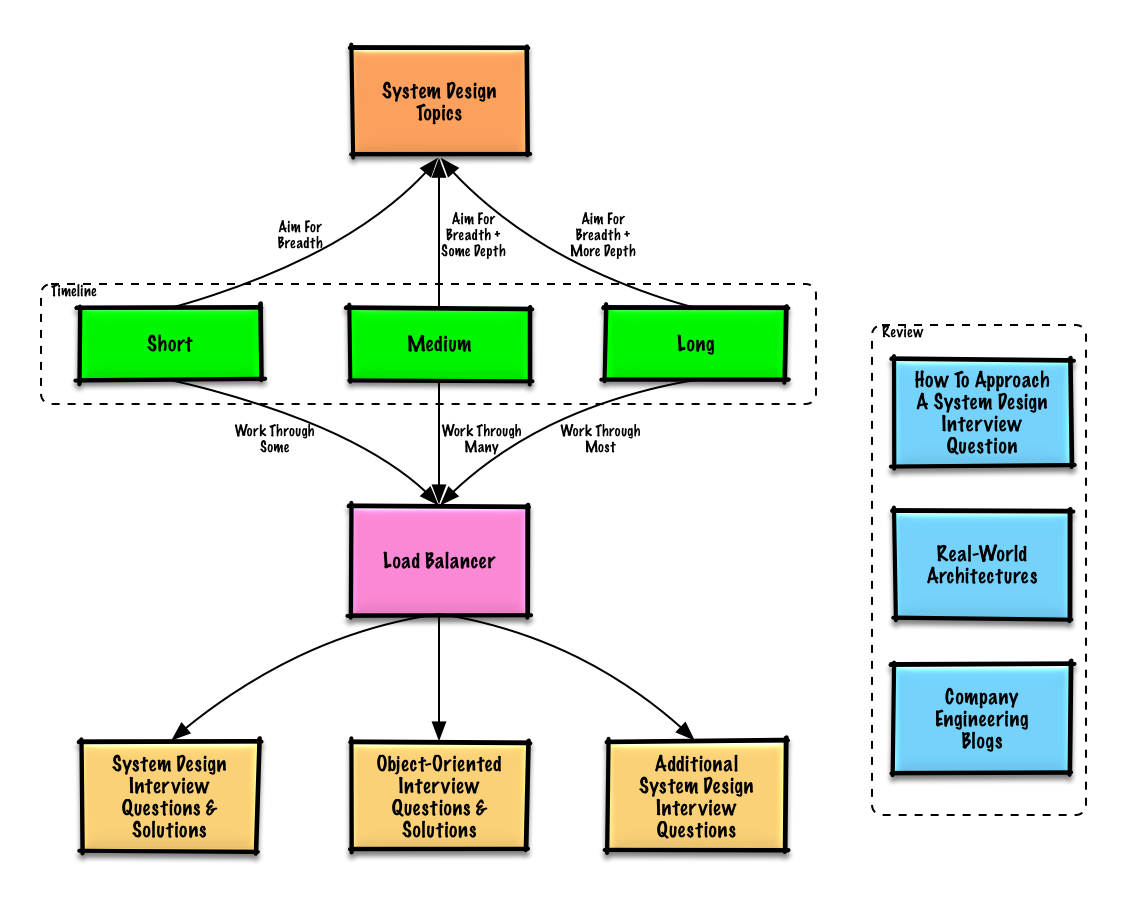
Lernleitfaden
Vorgeschlagene Themen zur Wiederholung, basierend auf deinem Interview-Zeitplan (kurz, mittel, lang).
F: Muss ich für Interviews alles hier wissen?
A: Nein, du musst nicht alles hier wissen, um dich auf das Interview vorzubereiten.
Was in einem Interview gefragt wird, hängt von Faktoren wie folgenden ab:
- Wie viel Erfahrung du hast
- Was dein technischer Hintergrund ist
- Für welche Positionen du dich bewirbst
- Bei welchen Unternehmen du dich bewirbst
- Glück
Beginnen Sie mit einem breiten Überblick und vertiefen Sie sich in einige Bereiche. Es hilft, ein wenig über verschiedene wichtige Themen im Bereich Systemdesign zu wissen. Passen Sie den folgenden Leitfaden an Ihren Zeitplan, Ihre Erfahrung, die Positionen, für die Sie sich bewerben, und die Unternehmen, bei denen Sie sich bewerben, an.
- Kurzer Zeitrahmen – Streben Sie nach Breite bei Systemdesign-Themen. Üben Sie, indem Sie einige Interviewfragen lösen.
- Mittlerer Zeitrahmen – Streben Sie nach Breite und etwas Tiefe bei Systemdesign-Themen. Üben Sie, indem Sie viele Interviewfragen lösen.
- Langer Zeitrahmen – Streben Sie nach Breite und mehr Tiefe bei Systemdesign-Themen. Üben Sie, indem Sie die meisten Interviewfragen lösen.
Wie man eine Systemdesign-Interviewfrage angeht
Wie man eine Systemdesign-Interviewfrage angeht.
Das Systemdesign-Interview ist ein offenes Gespräch. Sie sollen es führen.
Sie können die folgenden Schritte nutzen, um die Diskussion zu leiten. Um diesen Prozess zu festigen, arbeiten Sie den Abschnitt Systemdesign-Interviewfragen mit Lösungen anhand der folgenden Schritte durch.
Schritt 1: Anwendungsfälle, Einschränkungen und Annahmen umreißen
Ermitteln Sie Anforderungen und stecken Sie das Problem ab. Stellen Sie Fragen, um Anwendungsfälle und Einschränkungen zu klären. Diskutieren Sie Annahmen.
- Wer wird es benutzen?
- Wie werden sie es benutzen?
- Wie viele Benutzer gibt es?
- Was macht das System?
- Was sind die Eingaben und Ausgaben des Systems?
- Wie viele Daten erwarten wir zu verarbeiten?
- Wie viele Anfragen pro Sekunde erwarten wir?
- Wie ist das erwartete Lese-/Schreibverhältnis?
Schritt 2: Entwerfen Sie ein High-Level-Design
Umreißen Sie ein High-Level-Design mit allen wichtigen Komponenten.
- Skizzieren Sie die Hauptkomponenten und Verbindungen
- Begründen Sie Ihre Ideen
Schritt 3: Entwerfen Sie die Kernkomponenten
Gehen Sie ins Detail für jede Kernkomponente. Wenn Sie beispielsweise gebeten würden, einen URL-Verkürzungsdienst zu entwerfen, besprechen Sie:
- Generieren und Speichern eines Hashs der vollständigen URL
- MD5 und Base62
- Hash-Kollisionen
- SQL oder NoSQL
- Datenbankschema
- Übersetzen einer gehashten URL zur vollständigen URL
- Datenbankabfrage
- API- und objektorientiertes Design
Schritt 4: Skalieren Sie das Design
Identifizieren und adressieren Sie Engpässe unter den gegebenen Einschränkungen. Benötigen Sie beispielsweise Folgendes, um Skalierbarkeitsprobleme zu lösen?
- Lastverteiler
- Horizontale Skalierung
- Caching
- Datenbank-Sharding
Überschlagsrechnungen
Es kann sein, dass Sie einige Schätzungen von Hand durchführen sollen. Siehe Anhang für die folgenden Ressourcen:
Quelle(n) und weiterführende Literatur
Schauen Sie sich die folgenden Links an, um einen besseren Eindruck davon zu bekommen, was Sie erwartet:
- Wie man ein Systemdesign-Interview meistert
- Das Systemdesign-Interview
- Einführung in Architektur- und Systemdesign-Interviews
- Systemdesign-Vorlage
Systemdesign-Interviewfragen mit Lösungen
Häufige Systemdesign-Interviewfragen mit Beispiel-Diskussionen, Code und Diagrammen.>
Lösungen sind mit Inhalten im Ordner solutions/ verlinkt.| Frage | | |---|---| | Entwerfen Sie Pastebin.com (oder Bit.ly) | Lösung | | Entwerfen Sie die Twitter-Timeline und Suche (oder Facebook-Feed und Suche) | Lösung | | Entwerfen Sie einen Webcrawler | Lösung | | Entwerfen Sie Mint.com | Lösung | | Entwerfen Sie die Datenstrukturen für ein soziales Netzwerk | Lösung | | Entwerfen Sie einen Key-Value-Store für eine Suchmaschine | Lösung | | Entwerfen Sie die Verkaufsrangliste nach Kategorie von Amazon | Lösung | | Entwerfen Sie ein System, das auf AWS für Millionen von Nutzern skaliert | Lösung | | Fügen Sie eine Systemdesign-Frage hinzu | Beitragen |
Pastebin.com (oder Bit.ly) entwerfen
Die Twitter-Timeline und Suche entwerfen (oder Facebook-Feed und Suche)
Einen Webcrawler entwerfen
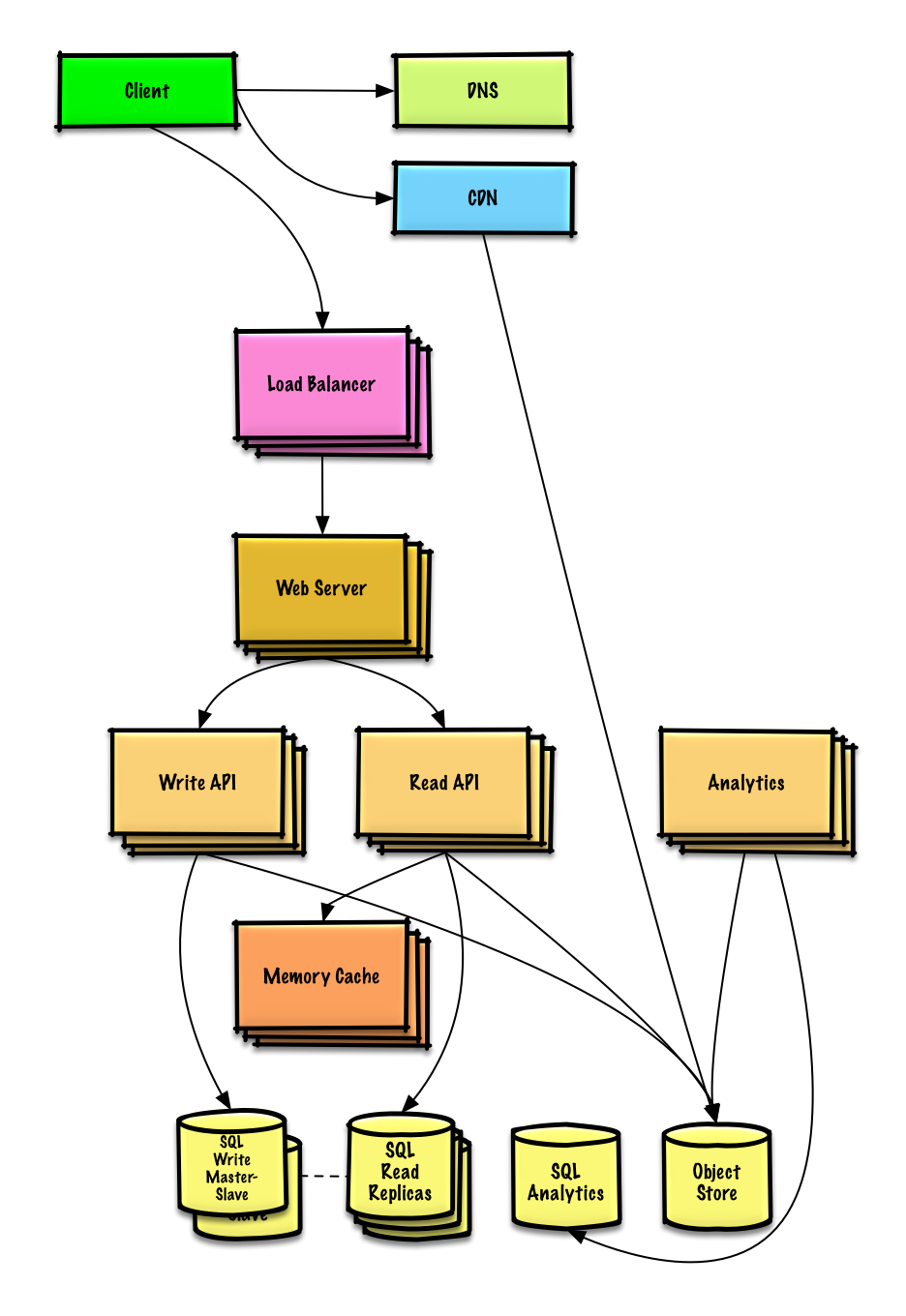
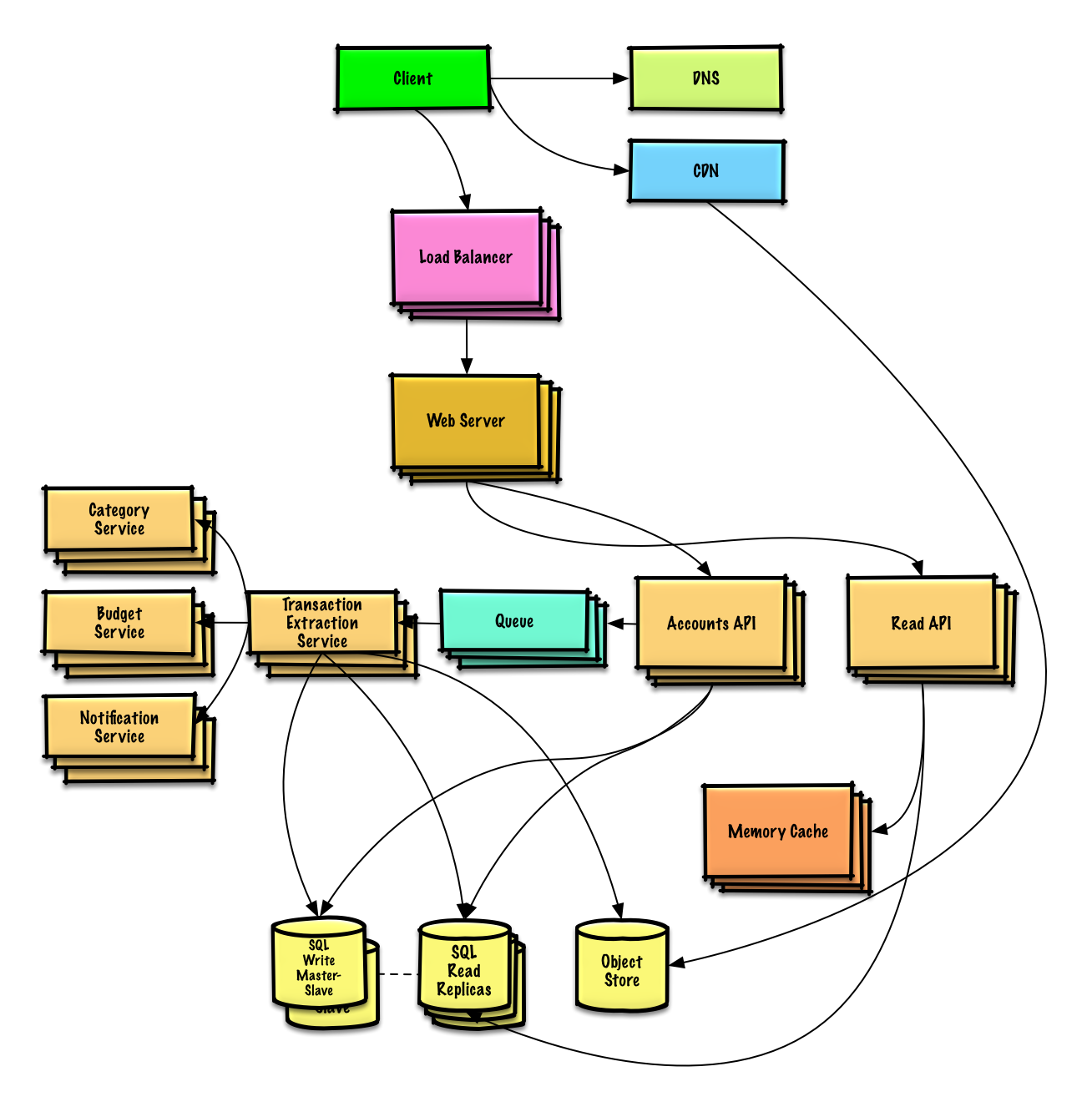
Design Mint.com
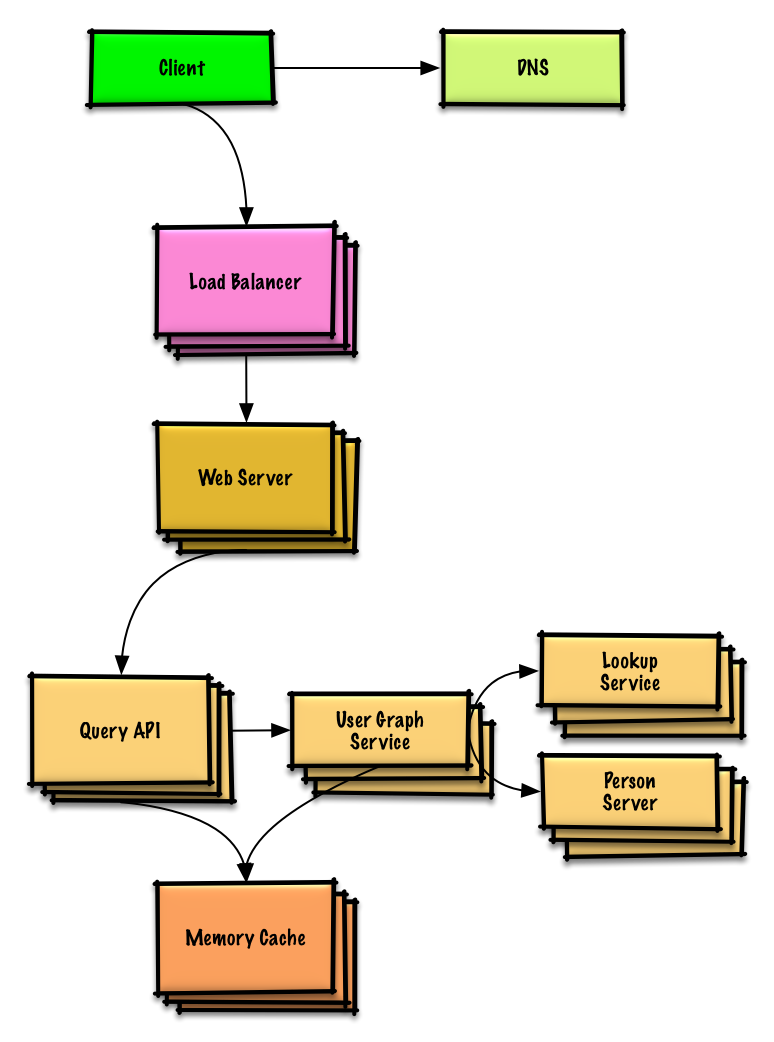
Design the data structures for a social network
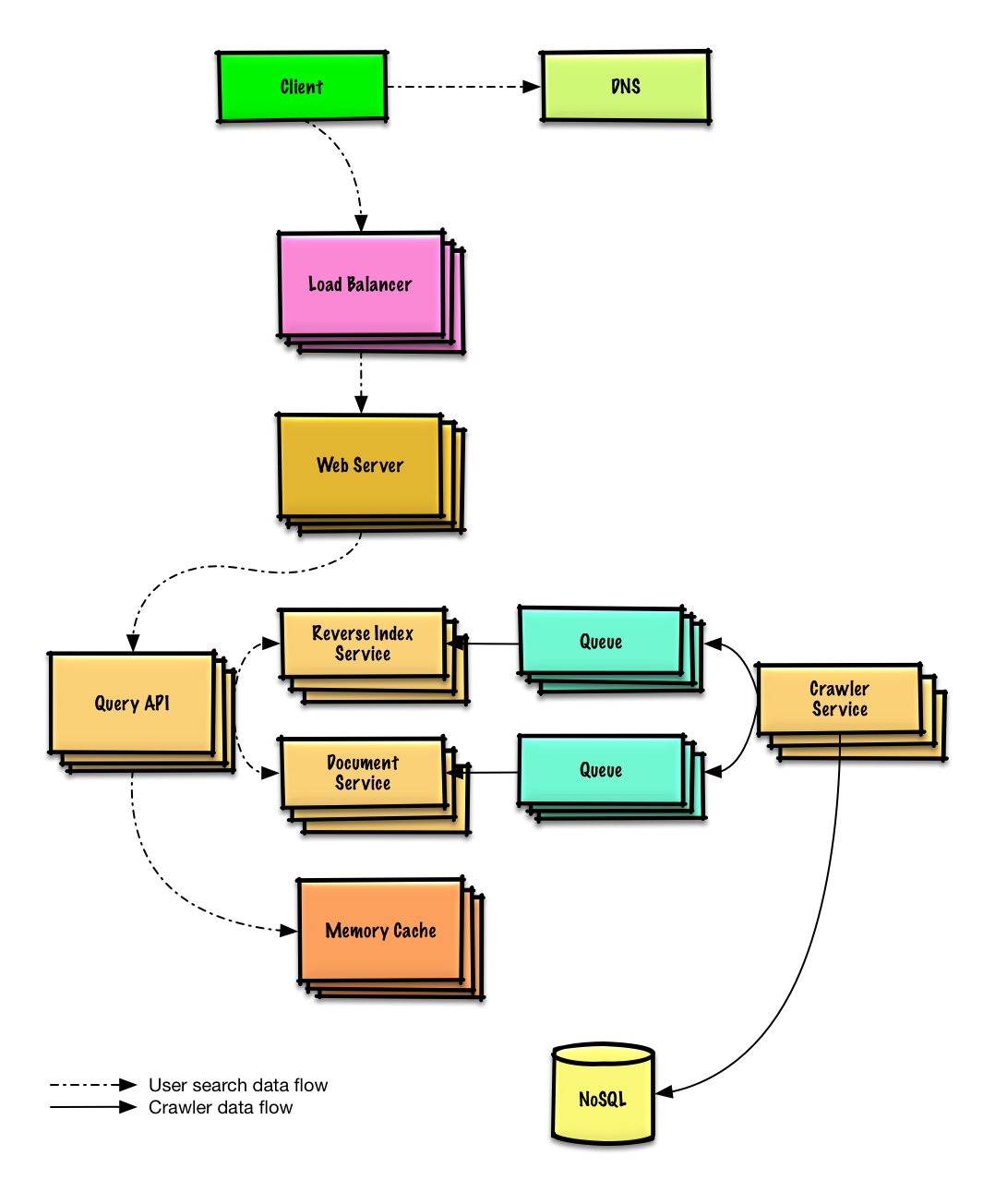
Design a key-value store for a search engine
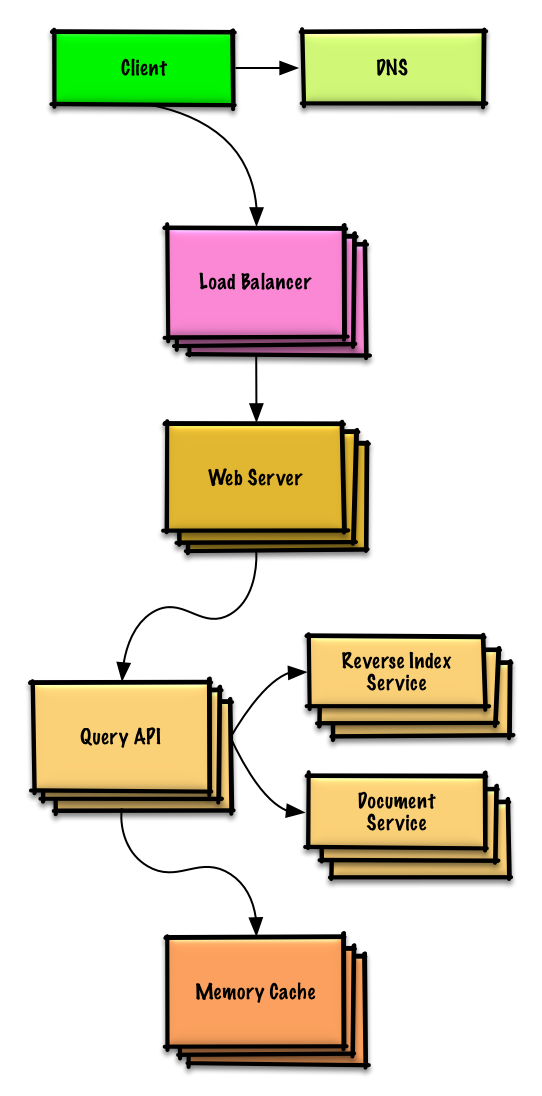
Design Amazon's sales ranking by category feature
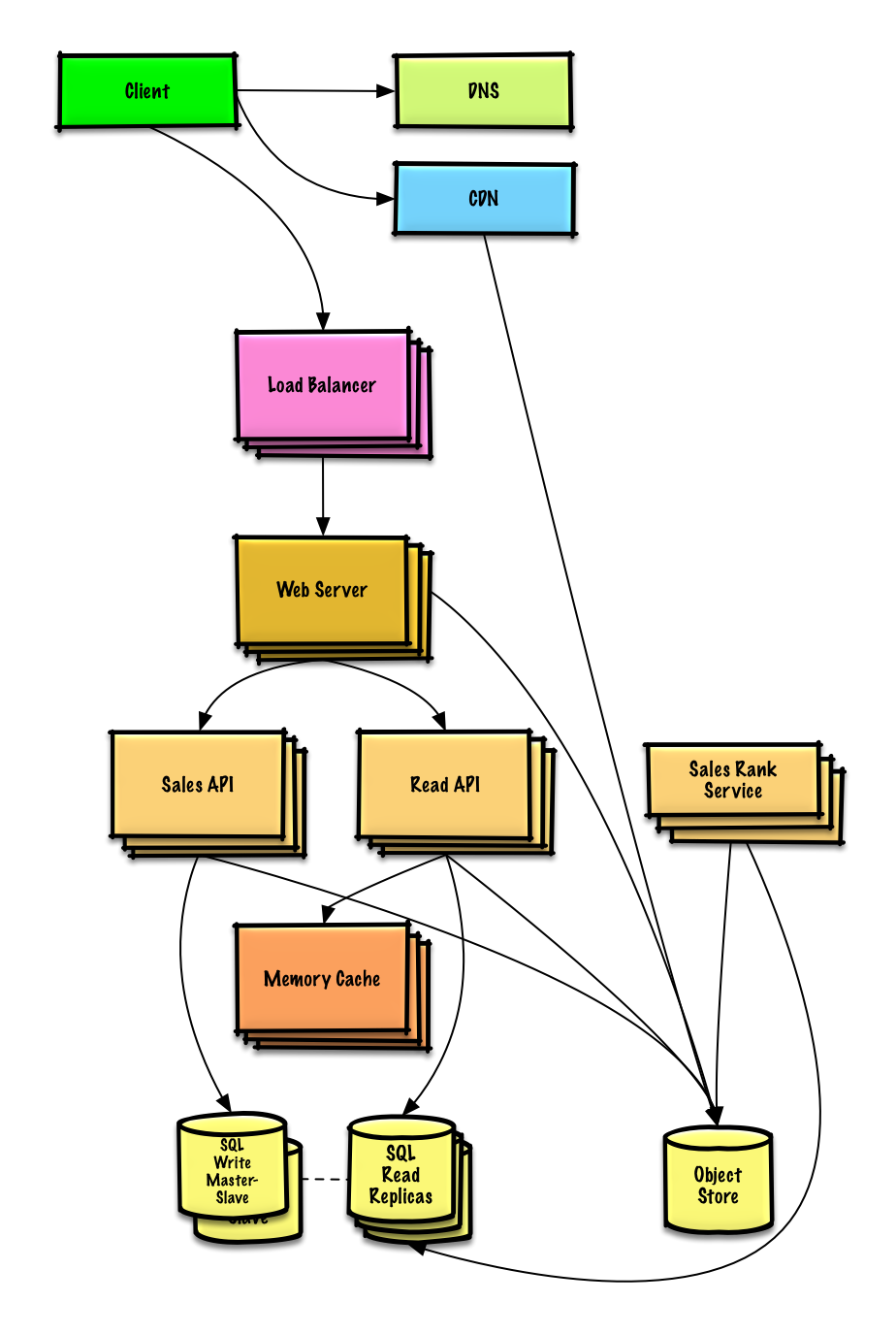
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Entwerfen Sie eine Hash Map | Lösung | | Entwerfen Sie einen Least Recently Used Cache | Lösung | | Entwerfen Sie ein Callcenter | Lösung | | Entwerfen Sie ein Kartenspiel-Deck | Lösung | | Entwerfen Sie einen Parkplatz | Lösung | | Entwerfen Sie einen Chat-Server | Lösung | | Entwerfen Sie ein zirkuläres Array | Mitwirken | | Fügen Sie eine objektorientierte Designfrage hinzu | Mitwirken |
Themen zur Systemarchitektur: Starten Sie hier
Neu im Bereich Systemarchitektur?
Zuerst benötigen Sie ein grundlegendes Verständnis für gängige Prinzipien, erfahren, was sie sind, wie sie verwendet werden und ihre Vor- und Nachteile.
Schritt 1: Sehen Sie sich die Skalierbarkeits-Vorlesung an
Skalierbarkeits-Vorlesung an der Harvard
- Behandelte Themen:
- Vertikale Skalierung
- Horizontale Skalierung
- Caching
- Lastverteilung
- Datenbankreplikation
- Datenbankpartitionierung
Schritt 2: Lesen Sie den Skalierbarkeits-Artikel
- Behandelte Themen:
- Klone
- Datenbanken
- Caches
- Asynchronität
Nächste Schritte
Als nächstes betrachten wir hochrangige Abwägungen:
- Leistung vs Skalierbarkeit
- Latenz vs Durchsatz
- Verfügbarkeit vs Konsistenz
Anschließend tauchen wir in spezifischere Themen wie DNS, CDNs und Load Balancer ein.
Leistung vs Skalierbarkeit
Ein Dienst ist skalierbar, wenn er eine gesteigerte Leistung proportional zu hinzugefügten Ressourcen zeigt. Im Allgemeinen bedeutet eine Leistungssteigerung, mehr Arbeitseinheiten zu bedienen, aber es kann auch bedeuten, größere Arbeitseinheiten zu bewältigen, etwa wenn Datensätze wachsen.1
Eine weitere Sichtweise auf Leistung vs Skalierbarkeit:
- Wenn du ein Leistungsproblem hast, ist dein System für einen einzelnen Nutzer langsam.
- Wenn du ein Skalierbarkeitsproblem hast, ist dein System für einen einzelnen Nutzer schnell, aber langsam bei hoher Last.
Quelle(n) und weiterführende Literatur
Latenz vs Durchsatz
Latenz ist die Zeit, um eine Aktion auszuführen oder ein Ergebnis zu erzeugen.
Durchsatz ist die Anzahl solcher Aktionen oder Ergebnisse pro Zeiteinheit.
Im Allgemeinen solltest du auf maximalen Durchsatz mit akzeptabler Latenz abzielen.
Quelle(n) und weiterführende Literatur
Verfügbarkeit vs Konsistenz
CAP-Theorem
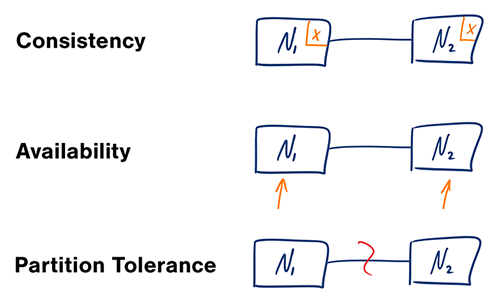
Quelle: CAP-Theorem erneut betrachtet
In einem verteilten Computersystem können Sie nur zwei der folgenden Garantien unterstützen:
- Konsistenz – Jeder Lesevorgang erhält entweder den aktuellsten Schreibvorgang oder einen Fehler
- Verfügbarkeit – Jede Anfrage erhält eine Antwort, ohne Garantie, dass sie die aktuellste Version der Information enthält
- Partitionstoleranz – Das System funktioniert weiterhin trotz beliebiger Partitionierungen durch Netzwerkausfälle
#### CP – Konsistenz und Partitionstoleranz
Das Warten auf eine Antwort vom partitionierten Knoten kann zu einem Timeout-Fehler führen. CP ist eine gute Wahl, wenn Ihr Geschäftsbedarf atomare Lese- und Schreibvorgänge erfordert.
#### AP – Verfügbarkeit und Partitionstoleranz
Antworten liefern die am einfachsten verfügbare Version der Daten auf einem beliebigen Knoten, die möglicherweise nicht die aktuellste ist. Schreibvorgänge können etwas Zeit benötigen, um sich nach Behebung der Partition zu verbreiten.
AP ist eine gute Wahl, wenn die Geschäftsanforderungen eventuelle Konsistenz erlauben oder das System trotz externer Fehler weiterarbeiten muss.
Quelle(n) und weiterführende Literatur
- CAP-Theorem erneut betrachtet
- Eine einfach erklärte Einführung ins CAP-Theorem
- CAP FAQ
- Das CAP-Theorem
Konsistenzmuster
Bei mehreren Kopien derselben Daten stehen wir vor der Frage, wie wir diese synchronisieren, sodass Clients eine konsistente Sicht auf die Daten erhalten. Erinnern Sie sich an die Definition von Konsistenz aus dem CAP-Theorem – Jeder Lesevorgang erhält entweder den aktuellsten Schreibvorgang oder einen Fehler.
Schwache Konsistenz
Nach einem Schreibvorgang kann ein Lesevorgang diesen sehen oder auch nicht. Es wird ein Best-Effort-Ansatz verfolgt.
Dieser Ansatz findet sich in Systemen wie memcached. Schwache Konsistenz funktioniert gut in Echtzeit-Anwendungen wie VoIP, Videochat und Echtzeit-Mehrspieler-Spielen. Wenn Sie beispielsweise während eines Telefonats für einige Sekunden den Empfang verlieren, hören Sie nach Wiederherstellung der Verbindung nicht, was während des Verbindungsverlusts gesprochen wurde.
Eventual Consistency (Schlussendliche Konsistenz)
Nach einem Schreibvorgang werden Leseoperationen diesen Wert schließlich sehen (typischerweise innerhalb von Millisekunden). Daten werden asynchron repliziert.
Dieser Ansatz findet sich in Systemen wie DNS und E-Mail. Schlussendliche Konsistenz funktioniert gut in hochverfügbaren Systemen.
Starke Konsistenz
Nach einem Schreibvorgang werden Leseoperationen diesen Wert sehen. Daten werden synchron repliziert.
Dieser Ansatz findet sich in Dateisystemen und RDBMS. Starke Konsistenz eignet sich gut für Systeme, die Transaktionen benötigen.
Quelle(n) und weiterführende Literatur
Verfügbarkeitsmuster
Es gibt zwei ergänzende Muster zur Unterstützung hoher Verfügbarkeit: Failover und Replikation.
Failover
#### Aktiv-Passiv
Beim Aktiv-Passiv-Failover werden Heartbeats zwischen dem aktiven und dem passiven Server im Standby-Modus gesendet. Wenn der Heartbeat unterbrochen wird, übernimmt der passive Server die IP-Adresse des aktiven Servers und setzt den Dienst fort.
Die Ausfallzeit hängt davon ab, ob der passive Server bereits im 'heißen' Standby läuft oder erst aus dem 'kalten' Standby hochgefahren werden muss. Nur der aktive Server verarbeitet den Datenverkehr.
Aktiv-Passiv-Failover wird auch als Master-Slave-Failover bezeichnet.
#### Aktiv-Aktiv
Beim Aktiv-Aktiv-Failover verwalten beide Server den Datenverkehr und verteilen die Last zwischen sich.
Wenn die Server öffentlich zugänglich sind, muss das DNS über die öffentlichen IPs beider Server Bescheid wissen. Wenn die Server intern genutzt werden, muss die Anwendungslogik beide Server kennen.
Aktiv-Aktiv-Failover wird auch als Master-Master-Failover bezeichnet.
Nachteil(e): Failover
- Failover erfordert mehr Hardware und zusätzliche Komplexität.
- Es besteht die Möglichkeit eines Datenverlusts, wenn das aktive System ausfällt, bevor neu geschriebene Daten auf das passive repliziert werden können.
Replikation
#### Master-Slave und Master-Master
Dieses Thema wird im Abschnitt Datenbank weiter behandelt:
Verfügbarkeit in Zahlen
Verfügbarkeit wird häufig anhand der Betriebszeit (oder Ausfallzeit) als Prozentsatz der Zeit gemessen, in der der Dienst verfügbar ist. Die Verfügbarkeit wird allgemein in Anzahl der Neunen angegeben–ein Dienst mit 99,99 % Verfügbarkeit wird als vier Neunen beschrieben.
#### 99,9 % Verfügbarkeit - drei Neunen
| Zeitraum | Zulässige Ausfallzeit| |---------------------|----------------------| | Ausfallzeit pro Jahr| 8h 45min 57s | | Ausfallzeit pro Monat| 43m 49,7s | | Ausfallzeit pro Woche| 10m 4,8s | | Ausfallzeit pro Tag | 1m 26,4s |
#### 99,99 % Verfügbarkeit - vier Neunen
| Zeitraum | Zulässige Ausfallzeit| |---------------------|----------------------| | Ausfallzeit pro Jahr| 52min 35,7s | | Ausfallzeit pro Monat| 4m 23s | | Ausfallzeit pro Woche| 1m 5s | | Ausfallzeit pro Tag | 8,6s |
#### Verfügbarkeit in Parallel- vs. Reihenfolge
Wenn ein Dienst aus mehreren ausfallgefährdeten Komponenten besteht, hängt die Gesamtverfügbarkeit des Dienstes davon ab, ob die Komponenten in Reihenfolge oder parallel angeordnet sind.
###### In Reihenfolge Die Gesamtverfügbarkeit sinkt, wenn zwei Komponenten mit einer Verfügbarkeit von < 100% in Reihe geschaltet sind:
Availability (Total) = Availability (Foo) * Availability (Bar)Wenn sowohl Foo als auch Bar jeweils eine Verfügbarkeit von 99,9 % hätten, läge ihre Gesamtverfügbarkeit in Reihe bei 99,8 %.
###### Parallel
Die Gesamtverfügbarkeit steigt, wenn zwei Komponenten mit einer Verfügbarkeit < 100 % parallel geschaltet sind:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo als auch Bar jeweils 99,9 % Verfügbarkeit hätten, läge ihre Gesamtverfügbarkeit im Parallelbetrieb bei 99,9999 %.Domain Name System
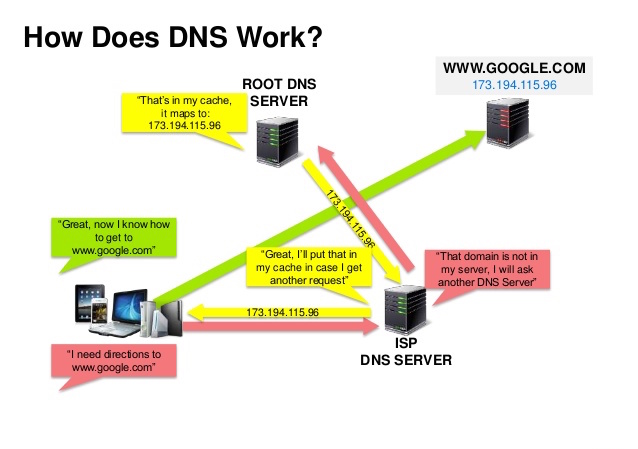
Quelle: DNS Security Presentation
Ein Domain Name System (DNS) übersetzt einen Domainnamen wie www.example.com in eine IP-Adresse.
DNS ist hierarchisch aufgebaut, mit wenigen autoritativen Servern auf der obersten Ebene. Ihr Router oder ISP gibt an, welchen DNS-Server (bzw. welche Server) Sie bei einer Abfrage kontaktieren sollen. DNS-Server auf niedrigeren Ebenen speichern Zuordnungen im Cache, die durch DNS-Propagation veralten können. Auch Ihr Browser oder Betriebssystem kann DNS-Ergebnisse für eine bestimmte Zeitspanne cachen, die durch die Time to Live (TTL) bestimmt wird.
- NS-Record (Name Server) – Gibt die DNS-Server für Ihre Domain/Subdomain an.
- MX-Record (Mail Exchange) – Gibt die Mailserver für den Empfang von Nachrichten an.
- A-Record (Address) – Verweist einen Namen auf eine IP-Adresse.
- CNAME (Canonical) – Verweist einen Namen auf einen anderen Namen oder
CNAME(example.com zu www.example.com) oder auf einenA-Record.
- Weighted Round Robin
- Verhindert, dass Traffic zu Servern unter Wartung geleitet wird
- Ausgleich zwischen unterschiedlich großen Clustern
- A/B-Testing
- Latenz-basiert
- Geolocation-basiert
Nachteil(e): DNS
- Der Zugriff auf einen DNS-Server verursacht eine geringe Verzögerung, die jedoch durch das oben beschriebene Caching abgemildert wird.
- Die Verwaltung von DNS-Servern kann komplex sein und wird im Allgemeinen von Regierungen, ISPs und großen Unternehmen übernommen.
- DNS-Dienste sind in letzter Zeit DDoS-Angriffen ausgesetzt gewesen, wodurch Nutzer z. B. Twitter nicht mehr aufrufen konnten, wenn sie die IP-Adresse(n) nicht kannten.
Quelle(n) und weiterführende Literatur
Content-Delivery-Netzwerk
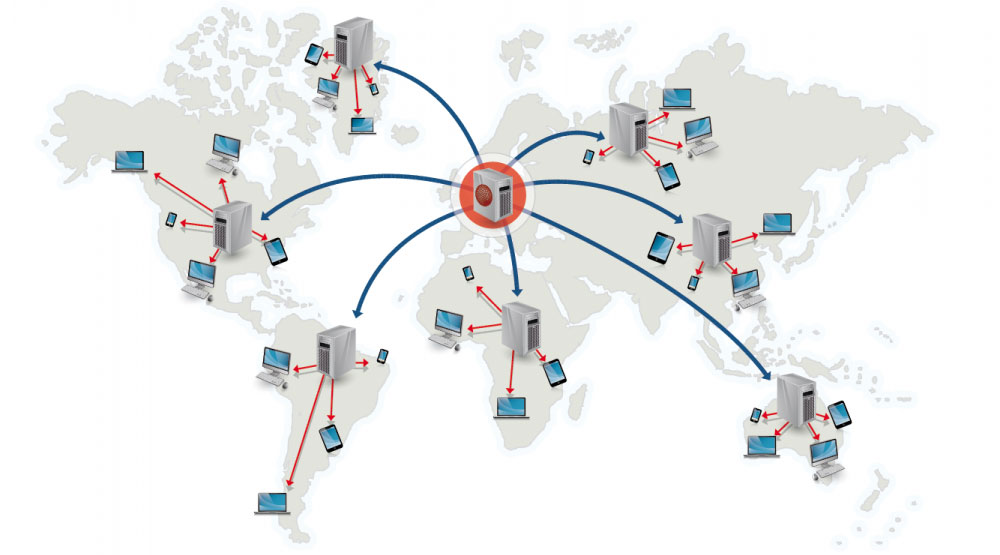
Ein Content-Delivery-Netzwerk (CDN) ist ein weltweit verteiltes Netzwerk von Proxy-Servern, das Inhalte von Standorten in der Nähe des Nutzers bereitstellt. Im Allgemeinen werden statische Dateien wie HTML/CSS/JS, Fotos und Videos von CDNs bereitgestellt, obwohl einige CDNs wie Amazons CloudFront auch dynamische Inhalte unterstützen. Die DNS-Auflösung der Website teilt den Clients mit, welchen Server sie kontaktieren sollen.
Die Bereitstellung von Inhalten über CDNs kann die Performance auf zwei Arten erheblich verbessern:
- Nutzer erhalten Inhalte aus Rechenzentren in ihrer Nähe
- Ihre Server müssen keine Anfragen bedienen, die vom CDN erfüllt werden
Push-CDNs
Push-CDNs erhalten neue Inhalte, sobald Änderungen auf Ihrem Server erfolgen. Sie sind vollständig verantwortlich für die Bereitstellung der Inhalte, laden sie direkt auf das CDN hoch und passen die URLs an, sodass sie auf das CDN verweisen. Sie können konfigurieren, wann Inhalte ablaufen und aktualisiert werden. Inhalte werden nur hochgeladen, wenn sie neu oder geändert sind, was den Traffic minimiert, aber den Speicherbedarf maximiert.
Webseiten mit wenig Traffic oder Webseiten mit Inhalten, die selten aktualisiert werden, funktionieren gut mit Push-CDNs. Inhalte werden einmalig auf das CDN geladen, statt regelmäßig neu abgerufen zu werden.
Pull-CDNs
Pull-CDNs laden neue Inhalte von Ihrem Server, wenn der erste Nutzer die Inhalte anfordert. Sie lassen die Inhalte auf Ihrem Server und passen die URLs an, sodass sie auf das CDN verweisen. Dies führt zu einer langsameren Anfrage, bis die Inhalte im CDN zwischengespeichert sind.
Ein Time-to-Live (TTL) bestimmt, wie lange Inhalte zwischengespeichert werden. Pull-CDNs minimieren den Speicherbedarf im CDN, können aber zu redundantem Traffic führen, wenn Dateien ablaufen und abgerufen werden, bevor sie tatsächlich geändert wurden.
Webseiten mit viel Traffic funktionieren gut mit Pull-CDNs, da der Traffic gleichmäßiger verteilt wird und nur kürzlich angeforderte Inhalte auf dem CDN verbleiben.
Nachteil(e): CDN
- CDN-Kosten können je nach Traffic erheblich sein, wobei dies gegen die zusätzlichen Kosten abzuwägen ist, die ohne CDN entstehen würden.
- Inhalte könnten veraltet sein, wenn sie aktualisiert werden, bevor der TTL abläuft.
- CDNs erfordern, dass URLs für statische Inhalte geändert werden, sodass sie auf das CDN verweisen.
Quelle(n) und weiterführende Literatur
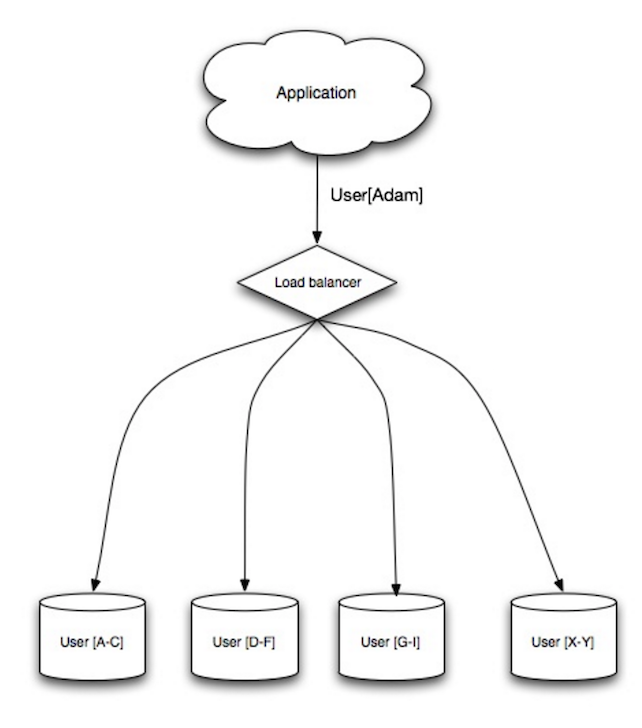
Load Balancer
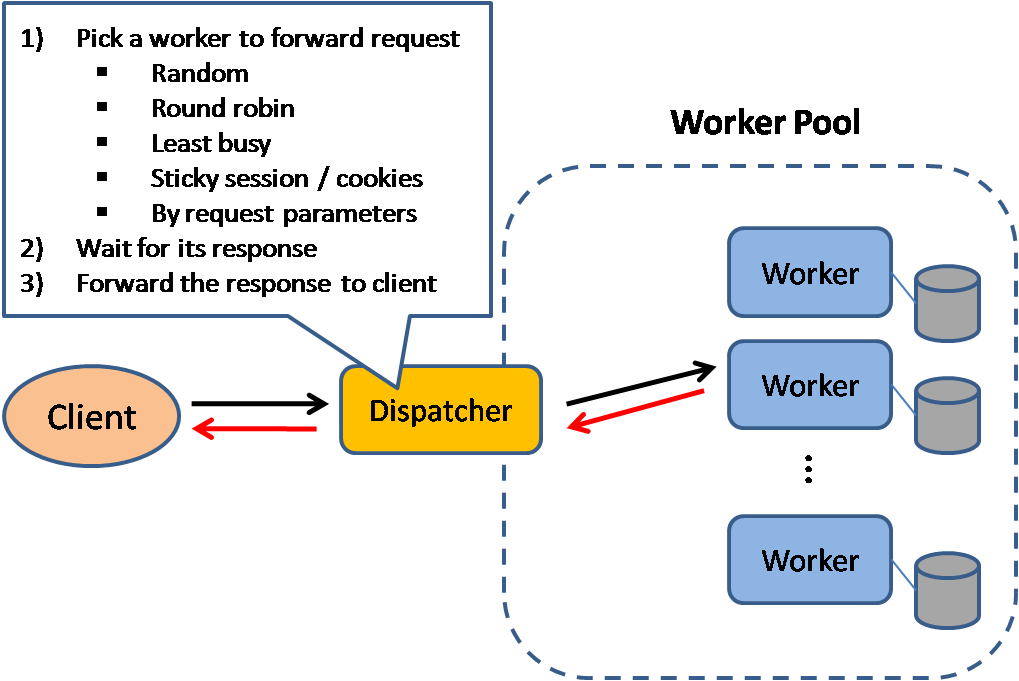
Quelle: Skalierbare Systemdesignmuster
Load Balancer verteilen eingehende Client-Anfragen an Computerressourcen wie Anwendungsserver und Datenbanken. In jedem Fall gibt der Load Balancer die Antwort der Computerressource an den entsprechenden Client zurück. Load Balancer sind effektiv bei:
- Verhindern, dass Anfragen an nicht funktionsfähige Server gesendet werden
- Verhindern der Überlastung von Ressourcen
- Mithelfen, einen Single Point of Failure zu eliminieren
Zusätzliche Vorteile sind:
- SSL-Termination – Entschlüsseln eingehender Anfragen und Verschlüsseln von Serverantworten, sodass Backend-Server diese potenziell teuren Operationen nicht ausführen müssen
- Entfernt die Notwendigkeit, X.509-Zertifikate auf jedem Server zu installieren
- Sitzungspersistenz – Ausstellen von Cookies und Weiterleiten der Anfragen eines bestimmten Clients an dieselbe Instanz, falls die Webanwendungen Sitzungen nicht verfolgen
Load Balancer können den Datenverkehr anhand verschiedener Metriken routen, darunter:
- Zufällig
- Am wenigsten ausgelastet
- Sitzung/Cookies
- Round Robin oder Weighted Round Robin
- Layer 4
- Layer 7
Layer-4-Load-Balancing
Layer-4-Load-Balancer betrachten Informationen auf der Transportschicht, um zu entscheiden, wie Anfragen verteilt werden. Im Allgemeinen betrifft dies die Quell- und Ziel-IP-Adressen und Ports im Header, jedoch nicht den Inhalt des Pakets. Layer-4-Load-Balancer leiten Netzwerkpakete zum und vom Upstream-Server weiter und führen Network Address Translation (NAT) durch.
Layer-7-Load-Balancing
Layer-7-Load-Balancer betrachten die Application Layer, um zu entscheiden, wie Anfragen verteilt werden. Dies kann Inhalte des Headers, der Nachricht und Cookies beinhalten. Layer-7-Load-Balancer beenden den Netzwerkverkehr, lesen die Nachricht, treffen eine Load-Balancing-Entscheidung und öffnen dann eine Verbindung zum ausgewählten Server. Ein Layer-7-Load-Balancer kann beispielsweise Videodatenverkehr zu Servern leiten, die Videos hosten, während sensibler Benutzer-Abrechnungsverkehr zu sicherheitsgehärteten Servern geleitet wird.Auf Kosten der Flexibilität erfordert Layer-4-Load-Balancing weniger Zeit und Rechenressourcen als Layer-7, obwohl der Performance-Einfluss auf moderner Standardhardware minimal sein kann.
Horizontales Skalieren
Load-Balancer können auch beim horizontalen Skalieren helfen und so Leistung und Verfügbarkeit verbessern. Das Skalieren mit Standardmaschinen ist kostengünstiger und führt zu höherer Verfügbarkeit als das Aufrüsten eines einzelnen Servers auf teurerer Hardware, was als vertikales Skalieren bezeichnet wird. Es ist außerdem einfacher, Fachkräfte für Standardhardware zu finden als für spezialisierte Enterprise-Systeme.
#### Nachteil(e): horizontales Skalieren
- Horizontales Skalieren führt zu Komplexität und beinhaltet das Klonen von Servern
- Server sollten zustandslos sein: Sie sollten keine benutzerbezogenen Daten wie Sessions oder Profilbilder enthalten
- Sessions können in einem zentralisierten Datenspeicher wie einer Datenbank (SQL, NoSQL) oder einem persistenten Cache (Redis, Memcached) gespeichert werden
- Nachgelagerte Server wie Caches und Datenbanken müssen mehr gleichzeitige Verbindungen bewältigen, wenn vorgelagerte Server skaliert werden
Nachteil(e): Load-Balancer
- Der Load-Balancer kann zu einem Performance-Engpass werden, wenn er nicht über genügend Ressourcen verfügt oder nicht richtig konfiguriert ist.
- Die Einführung eines Load-Balancers zur Beseitigung eines einzelnen Ausfallpunkts führt zu erhöhter Komplexität.
- Ein einzelner Load-Balancer ist ein einzelner Ausfallpunkt; die Konfiguration mehrerer Load-Balancer erhöht die Komplexität weiter.
Quelle(n) und weiterführende Literatur
- NGINX-Architektur
- HAProxy Architekturleitfaden
- Skalierbarkeit
- Wikipedia)
- Layer-4-Load-Balancing
- Layer-7-Load-Balancing
- ELB Listener-Konfiguration
Reverse Proxy (Webserver)
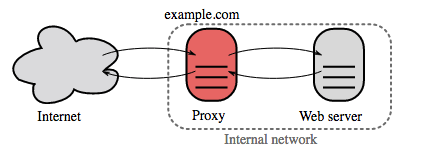
Ein Reverse Proxy ist ein Webserver, der interne Dienste zentralisiert und öffentliche Schnittstellen bereitstellt. Anfragen von Clients werden an einen Server weitergeleitet, der sie erfüllen kann, bevor der Reverse Proxy die Antwort des Servers an den Client zurückgibt.
Weitere Vorteile sind:
- Erhöhte Sicherheit – Informationen über Backend-Server verbergen, IPs auf die schwarze Liste setzen, Anzahl der Verbindungen pro Client begrenzen
- Erhöhte Skalierbarkeit und Flexibilität – Clients sehen nur die IP des Reverse Proxys, sodass Sie Server skalieren oder deren Konfiguration ändern können
- SSL-Terminierung – Entschlüsseln eingehender Anfragen und Verschlüsseln von Serverantworten, damit Backend-Server diese potenziell ressourcenintensiven Operationen nicht ausführen müssen
- Erspart die Installation von X.509-Zertifikaten auf jedem Server
- Komprimierung – Serverantworten komprimieren
- Caching – Antwort für zwischengespeicherte Anfragen zurückgeben
- Statische Inhalte – Statische Inhalte direkt bereitstellen
- HTML/CSS/JS
- Fotos
- Videos
- Etc
Load Balancer vs Reverse Proxy
- Der Einsatz eines Load Balancers ist sinnvoll, wenn Sie mehrere Server haben. Oft leiten Load Balancer den Datenverkehr an eine Gruppe von Servern mit derselben Funktion weiter.
- Reverse Proxys können auch bei nur einem Web- oder Anwendungsserver nützlich sein und bieten die Vorteile aus dem vorherigen Abschnitt.
- Lösungen wie NGINX und HAProxy unterstützen sowohl Layer-7-Reverse-Proxying als auch Load Balancing.
Nachteil(e): Reverse Proxy
- Das Einführen eines Reverse Proxys erhöht die Komplexität.
- Ein einzelner Reverse Proxy ist ein Single Point of Failure, die Konfiguration mehrerer Reverse Proxys (z.B. ein Failover) erhöht die Komplexität weiter.
Quelle(n) und weiterführende Literatur
Anwendungsschicht
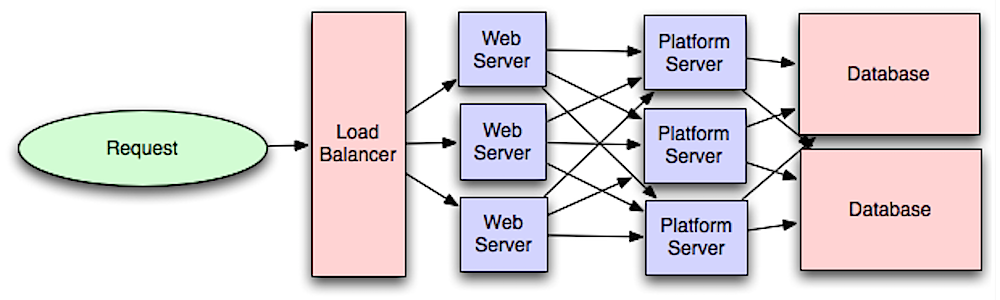
Quelle: Einführung in die Systemarchitektur für Skalierung
Die Trennung der Webschicht von der Anwendungsschicht (auch als Plattformschicht bekannt) ermöglicht es, beide Schichten unabhängig voneinander zu skalieren und zu konfigurieren. Das Hinzufügen einer neuen API führt zum Hinzufügen von Anwendungsservern, ohne dass zwangsläufig zusätzliche Webserver benötigt werden. Das Single-Responsibility-Prinzip befürwortet kleine und autonome Dienste, die zusammenarbeiten. Kleine Teams mit kleinen Diensten können aggressiver für schnelles Wachstum planen.
Worker in der Anwendungsschicht ermöglichen außerdem Asynchronität.
Microservices
Verwandt mit dieser Diskussion sind Microservices, die als eine Suite von unabhängig bereitstellbaren, kleinen, modularen Diensten beschrieben werden können. Jeder Dienst läuft in einem eigenen Prozess und kommuniziert über einen klar definierten, leichtgewichtigen Mechanismus, um ein Geschäftsziel zu erfüllen. 1
Pinterest könnte beispielsweise folgende Microservices haben: Nutzerprofil, Follower, Feed, Suche, Foto-Upload usw.
Service Discovery
Systeme wie Consul, Etcd, und Zookeeper helfen Diensten, sich gegenseitig zu finden, indem sie registrierte Namen, Adressen und Ports verfolgen. Health Checks helfen, die Integrität der Dienste zu überprüfen und werden oft über einen HTTP-Endpunkt durchgeführt. Sowohl Consul als auch Etcd verfügen über einen eingebauten Key-Value Store, der sich zum Speichern von Konfigurationswerten und anderen gemeinsamen Daten eignet.
Nachteil(e): Anwendungsschicht
- Das Hinzufügen einer Anwendungsschicht mit lose gekoppelten Diensten erfordert aus architektonischer, betrieblicher und prozessbezogener Sicht einen anderen Ansatz (im Vergleich zu einem monolithischen System).
- Microservices können zusätzliche Komplexität hinsichtlich Bereitstellung und Betrieb verursachen.
Quelle(n) und weiterführende Literatur
- Einführung in die Systemarchitektur für Skalierung
- Das Systemdesign-Interview meistern
- Serviceorientierte Architektur
- Einführung in Zookeeper
- Das sollten Sie über den Aufbau von Microservices wissen
Datenbank
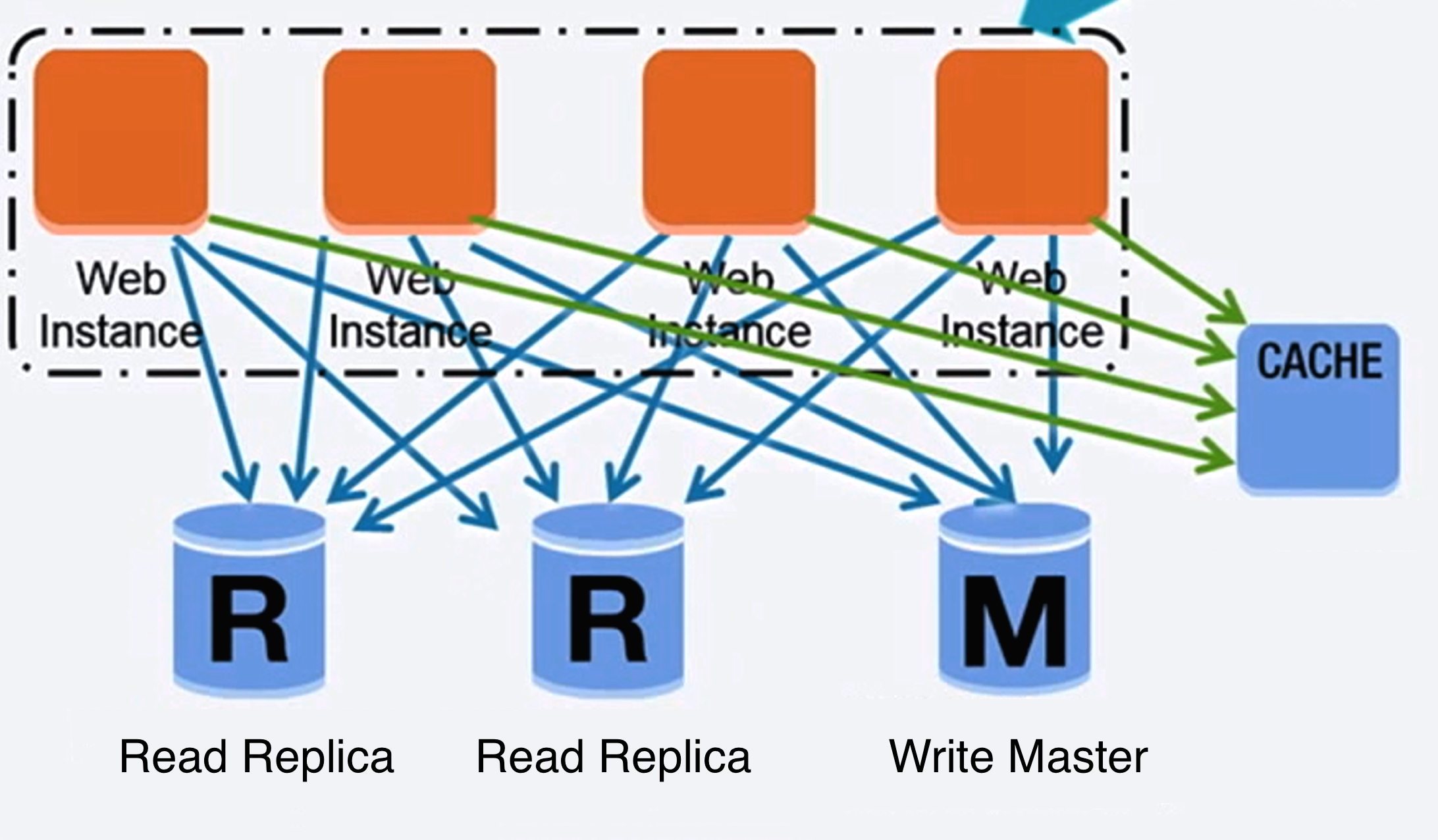
Quelle: Skalierung auf die ersten 10 Millionen Nutzer
Relationale Datenbankmanagementsysteme (RDBMS)
Eine relationale Datenbank wie SQL ist eine Sammlung von Datenelementen, die in Tabellen organisiert sind.
ACID ist eine Eigenschaftengruppe von relationalen Datenbank-Transaktionen).
- Atomarität – Jede Transaktion wird ganz oder gar nicht ausgeführt
- Konsistenz – Jede Transaktion bringt die Datenbank von einem gültigen Zustand in einen anderen
- Isolation – Gleichzeitige Ausführung von Transaktionen hat die gleichen Ergebnisse, als würden die Transaktionen seriell ausgeführt
- Dauerhaftigkeit – Sobald eine Transaktion bestätigt wurde, bleibt sie bestehen
#### Master-Slave-Replikation
Der Master verarbeitet Lese- und Schreibzugriffe und repliziert Schreibzugriffe an einen oder mehrere Slaves, die ausschließlich Lesezugriffe bedienen. Slaves können auch an weitere Slaves in einer baumartigen Struktur replizieren. Wenn der Master ausfällt, kann das System im Nur-Lese-Modus weiterarbeiten, bis ein Slave zum Master befördert oder ein neuer Master bereitgestellt wird.
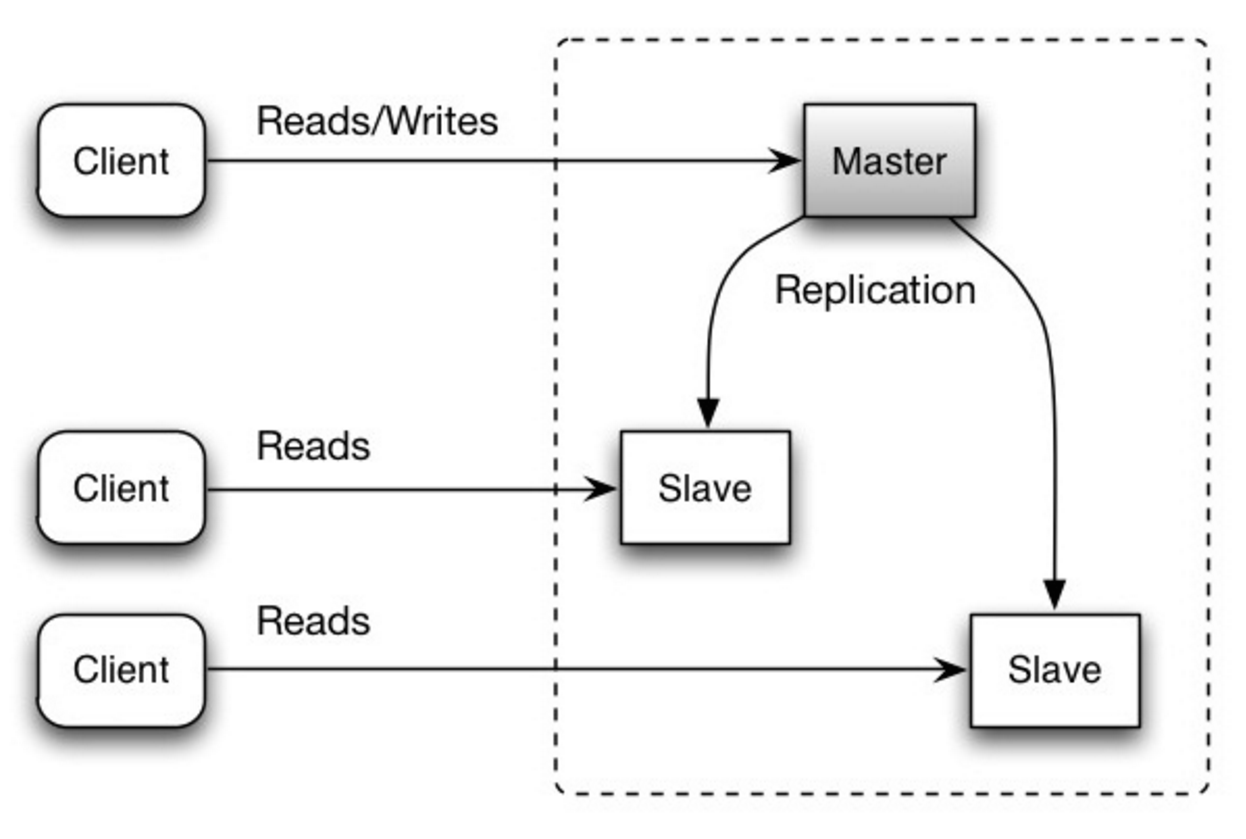
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
##### Nachteil(e): Master-Slave-Replikation
- Zusätzliche Logik ist erforderlich, um einen Slave zum Master zu befördern.
- Siehe Nachteil(e): Replikation für Punkte, die sowohl Master-Slave als auch Master-Master betreffen.
Beide Master bedienen Lese- und Schreibzugriffe und koordinieren Schreibzugriffe miteinander. Fällt einer der Master aus, kann das System weiterhin mit Lese- und Schreibzugriffen arbeiten.
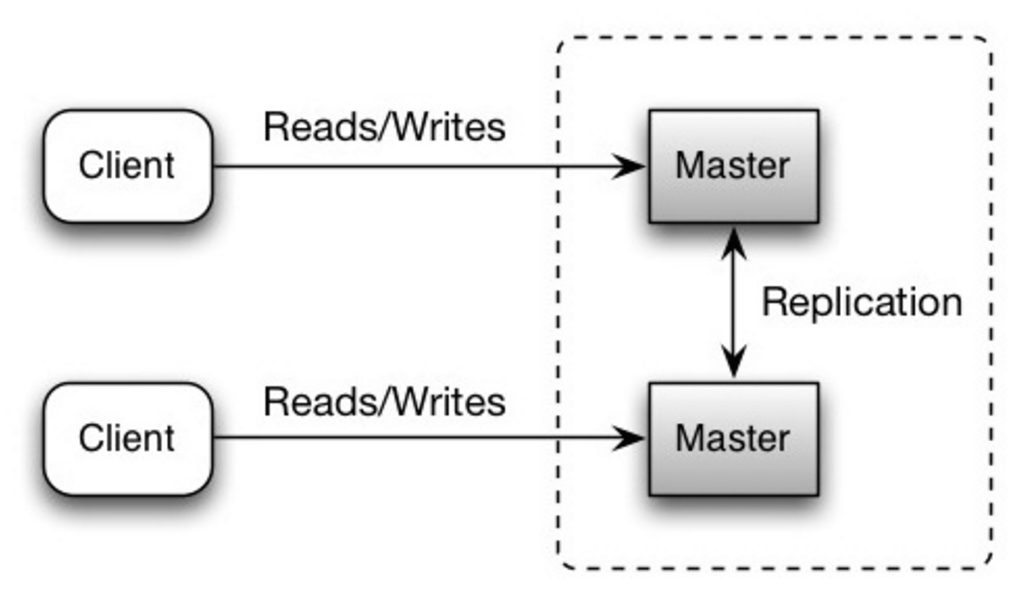
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
##### Nachteil(e): Master-Master-Replikation
- Sie benötigen einen Load-Balancer oder müssen Änderungen an Ihrer Anwendungslogik vornehmen, um zu bestimmen, wo geschrieben wird.
- Die meisten Master-Master-Systeme sind entweder lose konsistent (Verstoß gegen ACID) oder haben erhöhte Schreiblatenz durch Synchronisation.
- Die Konfliktlösung wird wichtiger, je mehr Schreibknoten hinzugefügt werden und je höher die Latenz ist.
- Siehe Nachteil(e): Replikation für Punkte, die sowohl Master-Slave als auch Master-Master betreffen.
- Es besteht die Möglichkeit eines Datenverlusts, wenn der Master ausfällt, bevor neu geschriebene Daten auf andere Knoten repliziert werden können.
- Schreibvorgänge werden auf die Lese-Replikas übertragen. Wenn es viele Schreibvorgänge gibt, können die Lese-Replikas durch das Wiederholen der Schreibvorgänge überlastet werden und dadurch weniger Lesevorgänge ausführen.
- Je mehr Lese-Slaves es gibt, desto mehr muss repliziert werden, was zu einer größeren Replikationsverzögerung führt.
- In einigen Systemen kann das Schreiben auf den Master mehrere Threads zur parallelen Verarbeitung verwenden, während Lese-Replikas das Schreiben nur sequenziell mit einem einzelnen Thread unterstützen.
- Replikation erfordert mehr Hardware und zusätzliche Komplexität.
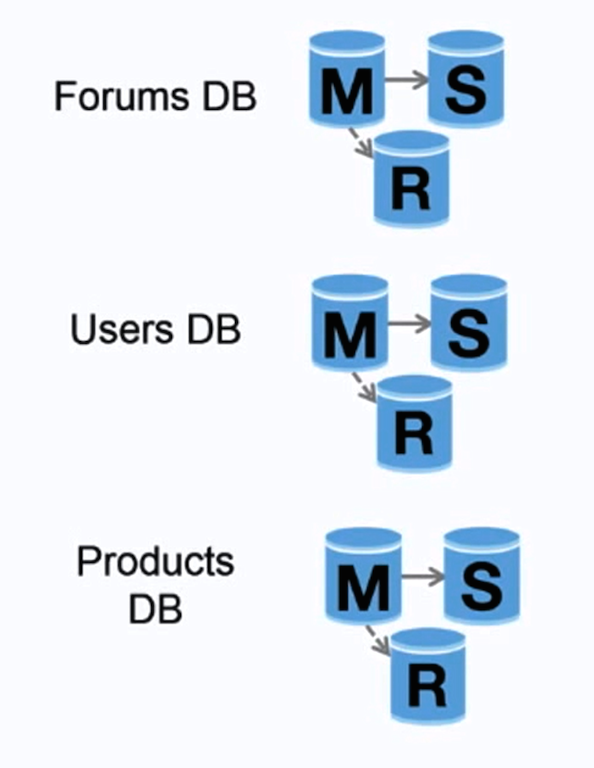
Quelle: Scaling up to your first 10 million users
Föderation (oder funktionale Partitionierung) teilt Datenbanken nach Funktion auf. Zum Beispiel könnte man statt einer einzigen, monolithischen Datenbank drei Datenbanken haben: foren, benutzer und produkte, was zu weniger Lese- und Schreibverkehr pro Datenbank und somit zu geringerer Replikationsverzögerung führt. Kleinere Datenbanken erlauben mehr Daten im Arbeitsspeicher, was wiederum zu mehr Cache-Treffern durch verbesserte Cache-Lokalität führt. Da kein zentraler Master die Schreibvorgänge serialisiert, kann parallel geschrieben werden, was den Durchsatz erhöht.
##### Nachteil(e): Föderation
- Föderation ist nicht effektiv, wenn Ihr Schema große Funktionen oder Tabellen erfordert.
- Sie müssen Ihre Anwendungslogik aktualisieren, um zu bestimmen, aus welcher Datenbank gelesen und in welche geschrieben werden soll.
- Das Zusammenführen von Daten aus zwei Datenbanken ist mit einem Server-Link komplexer.
- Föderation erfordert mehr Hardware und zusätzliche Komplexität.
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilitätsmuster
Sharding verteilt Daten auf verschiedene Datenbanken, so dass jede Datenbank nur einen Teil der Daten verwalten kann. Am Beispiel einer Benutzerdatenbank: Mit steigender Anzahl der Benutzer werden dem Cluster weitere Shards hinzugefügt.
Ähnlich wie die Vorteile von Federation führt Sharding zu weniger Lese- und Schreibverkehr, weniger Replikation und mehr Cache-Treffern. Auch die Indexgröße wird reduziert, was die Performance mit schnelleren Abfragen meist verbessert. Fällt ein Shard aus, sind die anderen weiterhin funktionsfähig, obwohl man zur Vermeidung von Datenverlust eine Replikation hinzufügen sollte. Wie bei Federation gibt es keinen zentralen Master, der Schreibvorgänge serialisiert, sodass paralleles Schreiben mit höherem Durchsatz möglich ist.
Übliche Methoden zum Sharding einer Benutzertabelle sind entweder über das Anfangsbuchstaben des Nachnamens oder den geografischen Standort des Benutzers.
##### Nachteil(e): Sharding
- Die Anwendungslogik muss an die Arbeit mit Shards angepasst werden, was zu komplexen SQL-Abfragen führen kann.
- Die Datenverteilung in einem Shard kann unausgewogen sein. Beispielsweise kann eine Gruppe von Power-Usern auf einem Shard zu erhöhter Belastung dieses Shards im Vergleich zu anderen führen.
- Rebalancing erhöht die Komplexität zusätzlich. Eine Sharding-Funktion auf Basis von konsistentem Hashing kann die Menge der zu übertragenden Daten reduzieren.
- Das Zusammenführen von Daten aus mehreren Shards ist komplexer.
- Sharding erfordert mehr Hardware und zusätzliche Komplexität.
Denormalisierung versucht, die Leseleistung auf Kosten der Schreibperformance zu verbessern. Redundante Kopien der Daten werden in mehreren Tabellen gespeichert, um teure Joins zu vermeiden. Einige relationale DBMS wie PostgreSQL und Oracle unterstützen materialisierte Sichten, die das Speichern redundanter Informationen und deren Konsistenz automatisch übernehmen.
Sobald Daten mit Techniken wie Federation und Sharding verteilt werden, erhöht das Management von Joins über Rechenzentren hinweg die Komplexität weiter. Denormalisierung kann die Notwendigkeit solcher komplexen Joins umgehen.
In den meisten Systemen stehen die Lesezugriffe den Schreibzugriffen im Verhältnis 100:1 oder sogar 1000:1 gegenüber. Ein Lesezugriff, der einen komplexen Datenbank-Join erfordert, kann sehr teuer sein und viel Zeit für Plattenoperationen beanspruchen.
##### Nachteil(e): Denormalisierung
- Daten werden dupliziert.
- Constraints können helfen, redundante Kopien von Informationen synchron zu halten, was die Komplexität des Datenbankdesigns erhöht.
- Eine denormalisierte Datenbank unter hoher Schreiblast kann schlechter performen als ihr normalisiertes Pendant.
SQL-Tuning ist ein umfangreiches Thema und viele Bücher wurden als Referenz geschrieben.
Es ist wichtig, Benchmarks und Profiling durchzuführen, um Engpässe zu simulieren und aufzudecken.
- Benchmark – Simuliere Hochlastsituationen mit Tools wie ab.
- Profiling – Aktiviere Tools wie das Slow Query Log, um Performanceprobleme zu verfolgen.
##### Das Schema optimieren
- MySQL schreibt Daten auf die Festplatte in zusammenhängenden Blöcken für schnellen Zugriff.
- Verwende
CHARanstelle vonVARCHARfür Felder mit fester Länge. CHARermöglicht effektiv schnellen, zufälligen Zugriff, während beiVARCHARdas Ende eines Strings gefunden werden muss, bevor zum nächsten gewechselt werden kann.- Verwende
TEXTfür große Textblöcke wie Blogbeiträge.TEXTermöglicht auch boolesche Suchen. Die Verwendung einesTEXT-Feldes führt dazu, dass ein Zeiger auf der Festplatte gespeichert wird, der zum Auffinden des Textblocks dient. - Verwende
INTfür größere Zahlen bis zu 2^32 oder 4 Milliarden. - Verwende
DECIMALfür Währungsbeträge, um Fehler bei der Fließkommadarstellung zu vermeiden. - Vermeide das Speichern großer
BLOBS, speichere stattdessen den Ort, an dem das Objekt abgelegt ist. VARCHAR(255)ist die größte Anzahl von Zeichen, die in einer 8-Bit-Zahl gezählt werden kann, was oft die Nutzung eines Bytes in manchen RDBMS maximiert.- Setze das
NOT NULL-Constraint, wo dies möglich ist, um die Suchleistung zu verbessern.
- Spalten, nach denen du abfragst (
SELECT,GROUP BY,ORDER BY,JOIN), können mit Indizes schneller sein. - Indizes werden meist als selbstbalancierende B-Bäume dargestellt, die Daten sortiert halten und Suchen, sequentiellen Zugriff, Einfügen und Löschen in logarithmischer Zeit ermöglichen.
- Ein Index kann dazu führen, dass die Daten im Speicher gehalten werden, was mehr Speicherplatz erfordert.
- Schreibvorgänge können langsamer werden, da auch der Index aktualisiert werden muss.
- Beim Laden großer Datenmengen kann es schneller sein, Indizes zu deaktivieren, die Daten zu laden und dann die Indizes neu zu erstellen.
- Denormalisiere, wenn es die Performance erfordert.
- Zerlegen Sie eine Tabelle, indem Sie Hotspots in eine separate Tabelle legen, um sie besser im Speicher zu halten.
- In einigen Fällen kann der Abfrage-Cache zu Leistungsproblemen führen.
- Tipps zur Optimierung von MySQL-Abfragen
- Gibt es einen guten Grund, warum VARCHAR(255) so oft verwendet wird?
- Wie beeinflussen Null-Werte die Leistung?
- Langsame Abfragelog
NoSQL
NoSQL ist eine Sammlung von Datenelementen, die als Key-Value Store, Dokumenten-Store, Wide Column Store oder Graphdatenbank dargestellt werden. Die Daten sind denormalisiert, und Joins werden in der Regel im Anwendungscode durchgeführt. Die meisten NoSQL-Stores verfügen nicht über echte ACID-Transaktionen und bevorzugen eventuelle Konsistenz.
BASE wird oft verwendet, um die Eigenschaften von NoSQL-Datenbanken zu beschreiben. Im Vergleich zum CAP-Theorem wählt BASE Verfügbarkeit statt Konsistenz.
- Basically available – das System garantiert Verfügbarkeit.
- Soft state – der Zustand des Systems kann sich im Laufe der Zeit ändern, auch ohne Eingaben.
- Eventual consistency – das System wird über einen Zeitraum hinweg konsistent, sofern das System während dieses Zeitraums keine Eingaben erhält.
#### Key-Value Store
Abstraktion: Hashtabelle
Ein Key-Value Store erlaubt im Allgemeinen O(1)-Lese- und Schreibzugriffe und basiert oft auf Speicher oder SSD. Datenspeicher können Schlüssel in lexikographischer Reihenfolge halten, was eine effiziente Abfrage von Schlüsselbereichen ermöglicht. Key-Value Stores erlauben das Speichern von Metadaten zusammen mit einem Wert.
Key-Value Stores bieten hohe Leistung und werden häufig für einfache Datenmodelle oder für sich schnell ändernde Daten wie z.B. eine In-Memory-Cache-Schicht verwendet. Da sie nur einen begrenzten Satz von Operationen bieten, wird zusätzliche Komplexität bei Bedarf auf die Anwendungsebene verlagert.
Ein Key-Value Store bildet die Grundlage für komplexere Systeme wie z.B. einen Dokumenten-Store und in manchen Fällen auch für eine Graphdatenbank.
##### Quelle(n) und weitere Lektüre: Key-Value Store
#### DokumentenspeicherAbstraktion: Schlüssel-Wert-Speicher mit Dokumenten als Werte
Ein Dokumentenspeicher konzentriert sich auf Dokumente (XML, JSON, Binärdateien, usw.), wobei ein Dokument alle Informationen für ein bestimmtes Objekt speichert. Dokumentenspeicher bieten APIs oder eine Abfragesprache, um auf Basis der internen Struktur des Dokuments selbst zu suchen. Beachte, viele Schlüssel-Wert-Speicher bieten Funktionen zur Arbeit mit den Metadaten eines Werts, wodurch die Grenzen zwischen diesen beiden Speichertypen verschwimmen.
Je nach zugrundeliegender Implementierung werden Dokumente nach Sammlungen, Tags, Metadaten oder Verzeichnissen organisiert. Obwohl Dokumente organisiert oder gruppiert werden können, können sie Felder aufweisen, die sich völlig voneinander unterscheiden.
Einige Dokumentenspeicher wie MongoDB und CouchDB bieten auch eine SQL-ähnliche Sprache, um komplexe Abfragen durchzuführen. DynamoDB unterstützt sowohl Schlüssel-Werte als auch Dokumente.
Dokumentenspeicher bieten hohe Flexibilität und werden oft für die Arbeit mit gelegentlich veränderlichen Daten verwendet.
##### Quelle(n) und weiterführende Literatur: Dokumentenspeicher
#### Wide Column Store
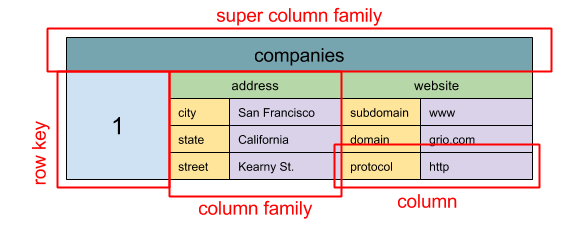
Quelle: SQL & NoSQL, eine kurze Geschichte
Abstraktion: verschachtelte Map ColumnFamily> Die Grundeinheit eines Wide Column Store ist eine Spalte (Name/Wert-Paar). Eine Spalte kann in Spaltenfamilien gruppiert werden (vergleichbar mit einer SQL-Tabelle). Super-Spaltenfamilien gruppieren Spaltenfamilien weiter. Jede Spalte kann unabhängig mit einem Zeilenschlüssel abgerufen werden, und Spalten mit demselben Zeilenschlüssel bilden eine Zeile. Jeder Wert enthält einen Zeitstempel zur Versionierung und zur Konfliktlösung.
Google stellte Bigtable als ersten Wide Column Store vor, was das Open-Source-Projekt HBase im Hadoop-Ökosystem und Cassandra von Facebook beeinflusste. Stores wie BigTable, HBase und Cassandra halten Schlüssel in lexikografischer Reihenfolge und ermöglichen eine effiziente Abfrage von selektiven Schlüsselbereichen.
Wide Column Stores bieten hohe Verfügbarkeit und hohe Skalierbarkeit. Sie werden häufig für sehr große Datensätze eingesetzt.
##### Quelle(n) und weiterführende Literatur: Wide Column Store
#### Graphdatenbank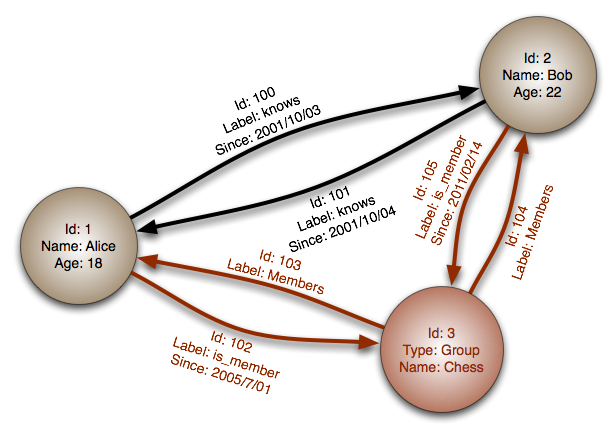
{kind=link}
{kind=link}
Abstraktion: Graph
In einer Graphdatenbank ist jeder Knoten ein Datensatz und jeder Bogen eine Beziehung zwischen zwei Knoten. Graphdatenbanken sind darauf optimiert, komplexe Beziehungen mit vielen Fremdschlüsseln oder viele-zu-viele-Beziehungen darzustellen.
Graphdatenbanken bieten eine hohe Leistung für Datenmodelle mit komplexen Beziehungen, wie beispielsweise ein soziales Netzwerk. Sie sind relativ neu und werden noch nicht weit verbreitet eingesetzt; es kann schwieriger sein, Entwicklungswerkzeuge und Ressourcen zu finden. Viele Graphen sind nur über REST-APIs zugänglich.
##### Quelle(n) und weiterführende Literatur: Graph
#### Quelle(n) und weiterführende Literatur: NoSQL- Erklärung der Basisterminologie
- NoSQL-Datenbanken – eine Übersicht und Entscheidungshilfe
- Skalierbarkeit
- Einführung in NoSQL
- NoSQL-Muster
SQL oder NoSQL
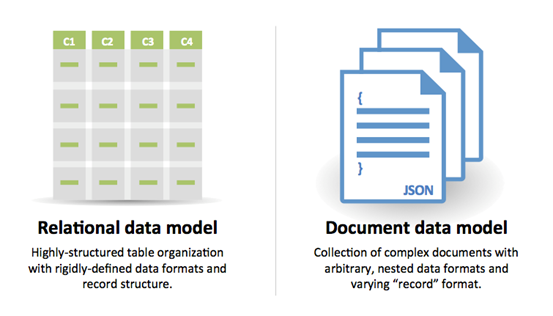
Quelle: Übergang von RDBMS zu NoSQL
Gründe für SQL:
- Strukturierte Daten
- Striktes Schema
- Relationale Daten
- Bedarf an komplexen Joins
- Transaktionen
- Klare Muster für Skalierung
- Etablierter: Entwickler, Community, Code, Tools, usw.
- Suchvorgänge über Index sind sehr schnell
- Semistrukturierte Daten
- Dynamisches oder flexibles Schema
- Nicht-relationale Daten
- Kein Bedarf an komplexen Joins
- Speicherung vieler TB (oder PB) an Daten
- Sehr datenintensive Arbeitslast
- Sehr hohe Durchsatzrate für IOPS
- Schnelles Einlesen von Clickstream- und Logdaten
- Leaderboard- oder Bewertungsdaten
- Temporäre Daten, wie z. B. ein Warenkorb
- Häufig abgerufene ('heiße') Tabellen
- Metadaten-/Lookup-Tabellen
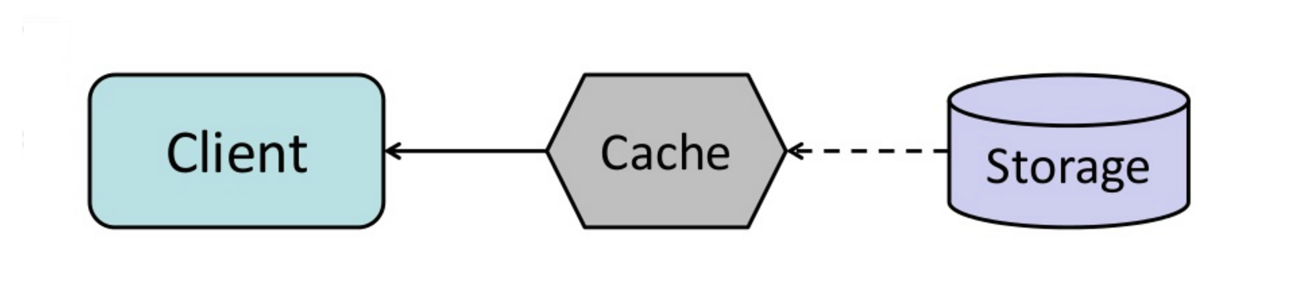
Cache
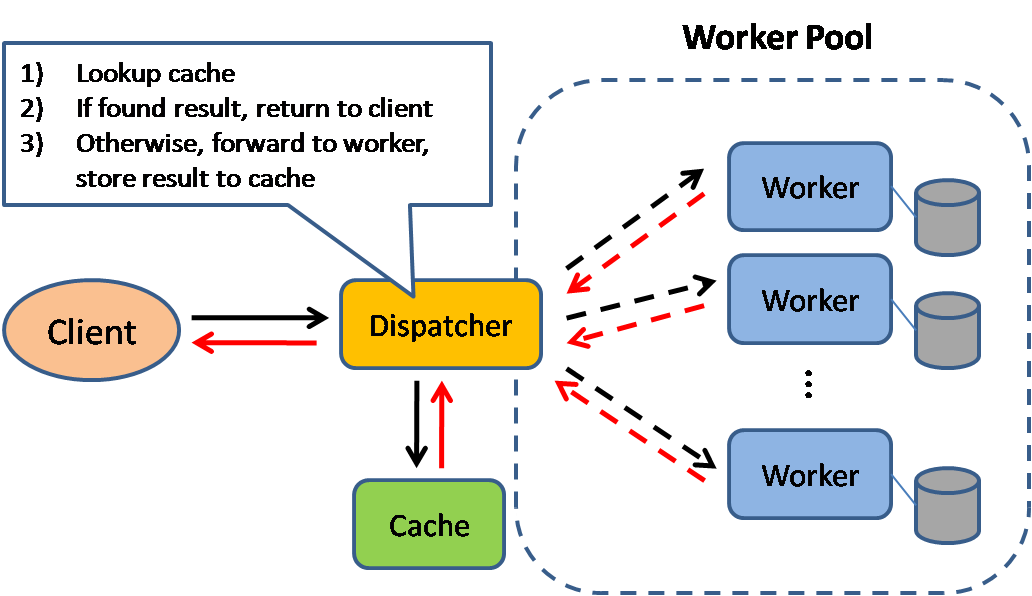
Quelle: Skalierbare Systemdesign-Muster
Caching verbessert die Ladezeiten von Seiten und kann die Belastung Ihrer Server und Datenbanken verringern. In diesem Modell prüft der Dispatcher zunächst, ob die Anfrage bereits gestellt wurde und versucht, das vorherige Ergebnis zu finden und zurückzugeben, um die tatsächliche Ausführung zu sparen.
Datenbanken profitieren oft von einer gleichmäßigen Verteilung von Lese- und Schreibvorgängen über ihre Partitionen. Beliebte Elemente können die Verteilung verzerren und Engpässe verursachen. Ein Cache vor der Datenbank kann helfen, ungleichmäßige Lasten und Verkehrsspitzen abzufangen.
Client-Caching
Caches können sich auf der Client-Seite (Betriebssystem oder Browser), Server-Seite oder in einer eigenen Cache-Schicht befinden.
CDN-Caching
CDNs werden als eine Art Cache betrachtet.
Webserver-Caching
Reverse Proxies und Caches wie Varnish können statische und dynamische Inhalte direkt ausliefern. Webserver können ebenfalls Anfragen cachen und Antworten zurückgeben, ohne die Anwendungsserver zu kontaktieren.
Datenbank-Caching
Ihre Datenbank enthält normalerweise ein gewisses Maß an Caching in der Standardkonfiguration, optimiert für einen generischen Anwendungsfall. Die Anpassung dieser Einstellungen an spezifische Nutzungsmuster kann die Leistung weiter steigern.
Anwendungs-Caching
In-Memory-Caches wie Memcached und Redis sind Key-Value-Stores zwischen Ihrer Anwendung und Ihrem Datenspeicher. Da die Daten im RAM gehalten werden, ist der Zugriff viel schneller als bei typischen Datenbanken, bei denen die Daten auf Festplatte gespeichert sind. RAM ist begrenzter als Festplattenspeicher, daher können Cache-Invalidierungs-Algorithmen wie Least Recently Used (LRU)) helfen, „kalte“ Einträge zu entfernen und „heiße“ Daten im RAM zu halten.
Redis bietet folgende zusätzliche Funktionen:
- Persistenzoption
- Eingebaute Datenstrukturen wie sortierte Sets und Listen
- Zeilenebene
- Abfrageebene
- Vollständig geformte serialisierbare Objekte
- Vollständig gerendertes HTML
Caching auf Datenbankabfrage-Ebene
Jedes Mal, wenn Sie die Datenbank abfragen, hashen Sie die Abfrage als Schlüssel und speichern das Ergebnis im Cache. Dieser Ansatz leidet unter Ablaufproblemen:
- Schwer zu löschendes, zwischengespeichertes Ergebnis bei komplexen Abfragen
- Wenn ein Datenstück wie eine Tabellenzelle geändert wird, müssen alle zwischengespeicherten Abfragen gelöscht werden, die die geänderte Zelle enthalten könnten
Caching auf Objektebene
Betrachten Sie Ihre Daten als Objekt, ähnlich wie Sie es mit Ihrem Anwendungscode tun. Lassen Sie Ihre Anwendung den Datensatz aus der Datenbank zu einer Klasseninstanz oder Datenstruktur(en) zusammensetzen:
- Entfernen Sie das Objekt aus dem Cache, wenn sich die zugrundeliegenden Daten geändert haben
- Ermöglicht asynchrone Verarbeitung: Worker erstellen Objekte, indem sie das aktuellste zwischengespeicherte Objekt konsumieren
- Benutzersitzungen
- Komplett gerenderte Webseiten
- Aktivitätsstreams
- Benutzergrafdaten
Wann sollte der Cache aktualisiert werden
Da Sie nur eine begrenzte Menge an Daten im Cache speichern können, müssen Sie bestimmen, welche Strategie zur Cache-Aktualisierung am besten für Ihren Anwendungsfall geeignet ist.
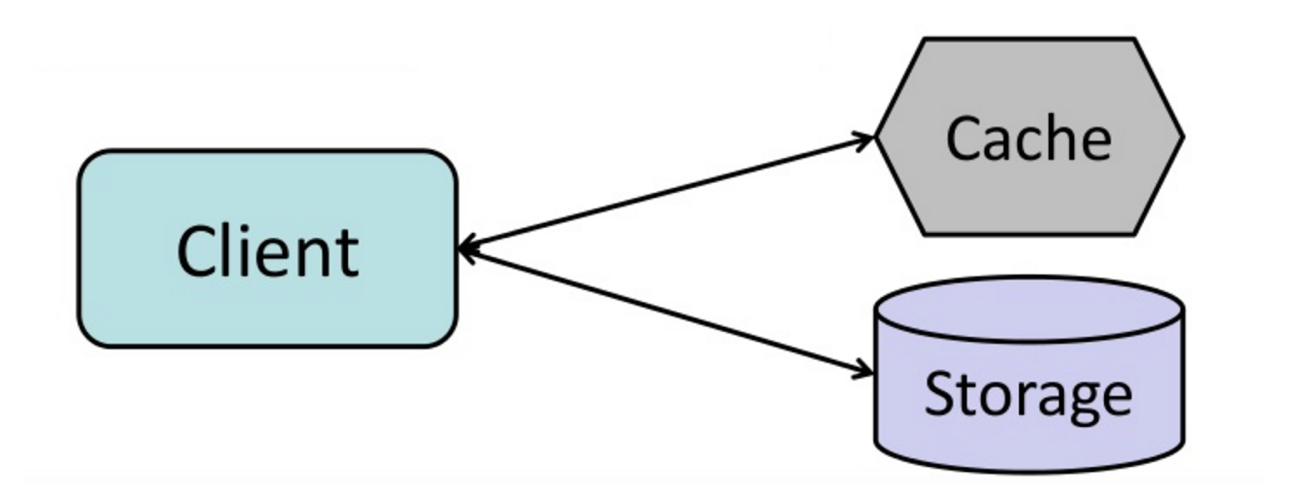
#### Cache-aside
Quelle: From cache to in-memory data grid
Die Anwendung ist dafür verantwortlich, aus dem Speicher zu lesen und zu schreiben. Der Cache interagiert nicht direkt mit dem Speicher. Die Anwendung tut Folgendes:
- Suche nach Eintrag im Cache, was zu einem Cache-Miss führt
- Lade Eintrag aus der Datenbank
- Füge Eintrag zum Cache hinzu
- Gib Eintrag zurück
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userNachfolgende Lesezugriffe auf in den Cache hinzugefügte Daten sind schnell. Cache-aside wird auch als Lazy Loading bezeichnet. Es werden nur angeforderte Daten zwischengespeichert, wodurch vermieden wird, dass der Cache mit nicht angeforderten Daten gefüllt wird.
##### Nachteil(e): Cache-aside
- Jeder Cache-Miss führt zu drei Zugriffen, was zu einer spürbaren Verzögerung führen kann.
- Daten können veraltet sein, wenn sie in der Datenbank aktualisiert werden. Dieses Problem wird durch das Setzen einer Time-to-Live (TTL) gemildert, die ein Update des Cache-Eintrags erzwingt, oder durch die Verwendung von Write-through.
- Fällt ein Knoten aus, wird er durch einen neuen, leeren Knoten ersetzt, was die Latenz erhöht.
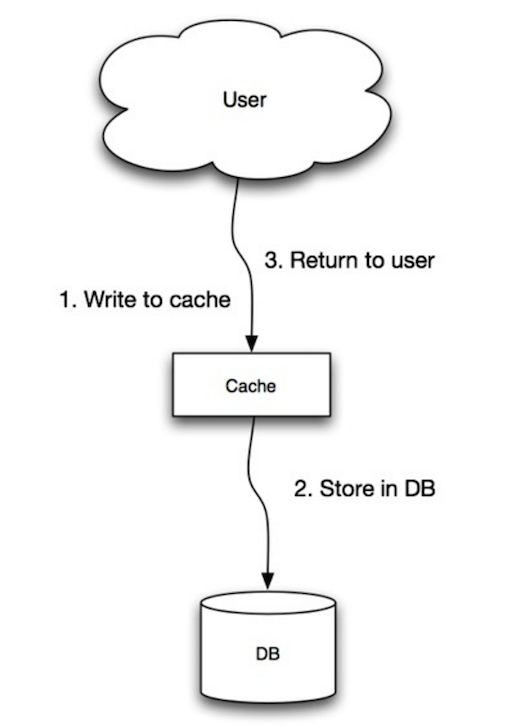
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilität, Muster
Die Anwendung verwendet den Cache als Hauptdatenspeicher, liest und schreibt Daten darin, während der Cache für das Lesen und Schreiben in die Datenbank verantwortlich ist:
- Die Anwendung fügt einen Eintrag zum Cache hinzu oder aktualisiert ihn
- Der Cache schreibt den Eintrag synchron in den Datenspeicher
- Rückgabe
set_user(12345, {"foo":"bar"})Cache-Code:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Nachteil(e): Write-through
- Wenn ein neuer Knoten aufgrund eines Ausfalls oder Skalierung erstellt wird, wird der neue Knoten keine Einträge cachen, bis der Eintrag in der Datenbank aktualisiert wird. Cache-aside in Verbindung mit Write-through kann dieses Problem mindern.
- Die meisten geschriebenen Daten werden möglicherweise nie gelesen, was durch eine TTL minimiert werden kann.
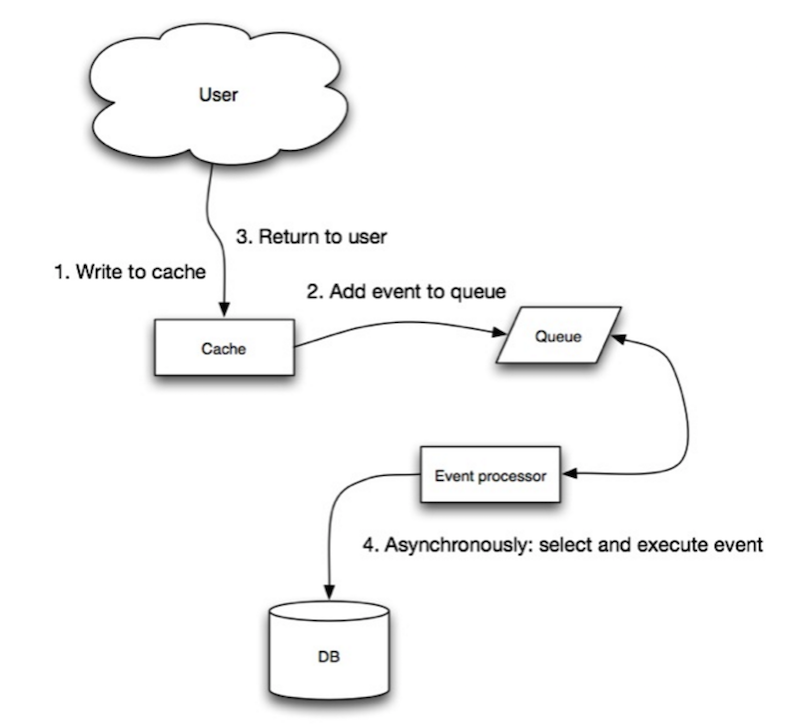
Quelle: Skalierbarkeit, Verfügbarkeit, Stabilitätsmuster
Beim Write-behind führt die Anwendung Folgendes aus:
- Hinzufügen/Aktualisieren des Eintrags im Cache
- Asynchrones Schreiben des Eintrags in den Datenspeicher, was die Schreibleistung verbessert
- Es kann zu Datenverlust kommen, wenn der Cache ausfällt, bevor sein Inhalt den Datenspeicher erreicht.
- Die Implementierung von Write-behind ist komplexer als die von Cache-aside oder Write-through.
Quelle: Vom Cache zum In-Memory Data Grid
Der Cache kann so konfiguriert werden, dass kürzlich abgerufene Cache-Einträge automatisch vor deren Ablauf aktualisiert werden.
Refresh-ahead kann zu geringerer Latenz im Vergleich zu Read-through führen, wenn der Cache genau vorhersagen kann, welche Elemente wahrscheinlich zukünftig benötigt werden.
##### Nachteil(e): Refresh-ahead
- Wenn nicht genau vorhergesagt wird, welche Elemente in Zukunft benötigt werden, kann dies zu einer geringeren Performance führen als ohne Refresh-Ahead.
Nachteil(e): Cache
- Es muss Konsistenz zwischen Caches und der maßgeblichen Quelle wie der Datenbank durch Cache-Invalidierung aufrechterhalten werden.
- Cache-Invalidierung ist ein schwieriges Problem, es entsteht zusätzliche Komplexität im Zusammenhang mit dem Zeitpunkt der Aktualisierung des Caches.
- Es sind Änderungen an der Anwendung erforderlich, wie z. B. das Hinzufügen von Redis oder Memcached.
Quelle(n) und weiterführende Literatur
- From cache to in-memory data grid
- Scalable system design patterns
- Introduction to architecting systems for scale
- Scalability, availability, stability, patterns
- Scalability
- AWS ElastiCache strategies
- Wikipedia)
Asynchronität
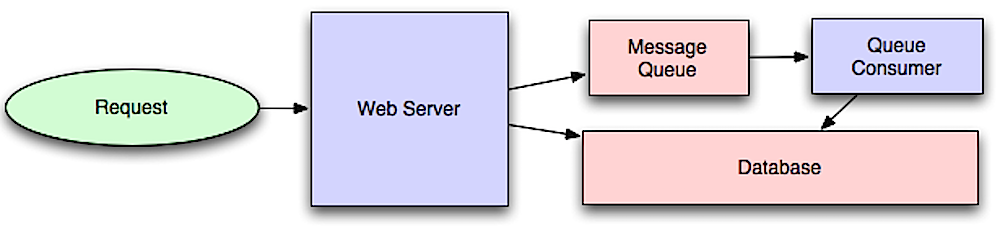
Quelle: Intro to architecting systems for scale
Asynchrone Workflows helfen, Anforderungszeiten für aufwendige Operationen zu verkürzen, die sonst inline ausgeführt würden. Sie können auch helfen, indem sie zeitaufwändige Arbeiten im Voraus erledigen, wie z. B. periodische Aggregationen von Daten.
Message Queues
Message Queues empfangen, halten und liefern Nachrichten aus. Wenn eine Operation zu langsam ist, um sie inline auszuführen, kann eine Message Queue mit folgendem Ablauf verwendet werden:
- Eine Anwendung veröffentlicht einen Job in der Warteschlange und benachrichtigt den Nutzer über den Jobstatus
- Ein Worker nimmt den Job aus der Warteschlange, verarbeitet ihn und signalisiert anschließend, dass der Job abgeschlossen ist
Redis ist als einfacher Message Broker nützlich, aber Nachrichten können verloren gehen.
RabbitMQ ist beliebt, erfordert jedoch die Anpassung an das 'AMQP'-Protokoll und das Verwalten eigener Nodes.
Amazon SQS ist gehostet, kann jedoch eine hohe Latenz aufweisen und es besteht die Möglichkeit, dass Nachrichten doppelt zugestellt werden.
Aufgabenwarteschlangen
Aufgabenwarteschlangen empfangen Aufgaben und die zugehörigen Daten, führen diese aus und liefern dann ihre Ergebnisse. Sie können die Planung unterstützen und werden verwendet, um rechenintensive Jobs im Hintergrund auszuführen.
Celery unterstützt die Planung und bietet hauptsächlich Unterstützung für Python.
Rückstau (Back pressure)
Wenn Warteschlangen signifikant wachsen, kann die Warteschlangengröße größer als der Arbeitsspeicher werden, was zu Cache-Verlusten, Festplattenzugriffen und noch langsamerer Leistung führt. Rückstau kann helfen, indem die Warteschlangengröße begrenzt wird und so eine hohe Durchsatzrate und gute Antwortzeiten für bereits in der Warteschlange befindliche Jobs erhalten bleiben. Sobald die Warteschlange voll ist, erhalten Clients einen „Server busy“- oder HTTP-503-Statuscode, um es später erneut zu versuchen. Clients können die Anfrage zu einem späteren Zeitpunkt erneut senden, eventuell mit exponentiellem Backoff.
Nachteil(e): Asynchronität
- Anwendungsfälle wie kostengünstige Berechnungen und Echtzeit-Workflows sind möglicherweise besser für synchrone Operationen geeignet, da die Einführung von Warteschlangen Verzögerungen und Komplexität verursachen kann.
Quellen und weiterführende Literatur
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- What is the difference between a message queue and a task queue?
Kommunikation
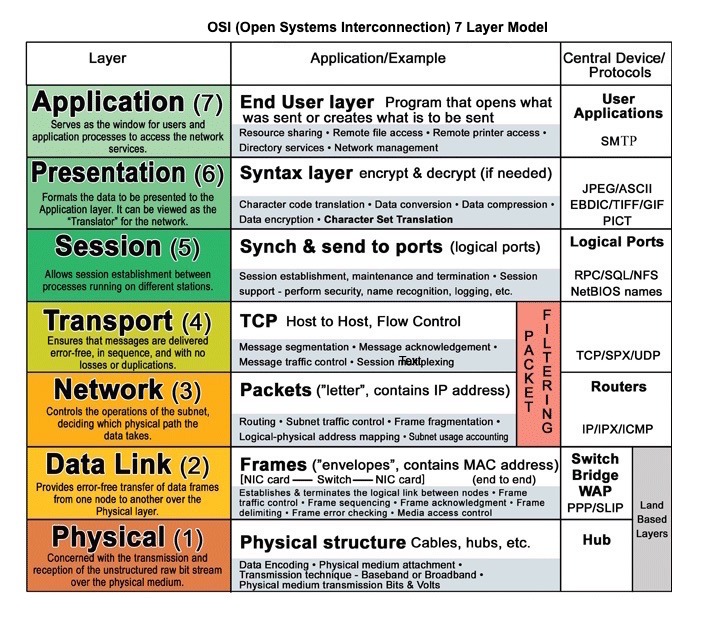
Quelle: OSI 7-Schichten-Modell
Hypertext Transfer Protocol (HTTP)
HTTP ist eine Methode zur Kodierung und Übertragung von Daten zwischen einem Client und einem Server. Es handelt sich um ein Request/Response-Protokoll: Clients stellen Anfragen und Server liefern Antworten mit relevanten Inhalten und Statusinformationen zur Anfrage. HTTP ist selbstständig und ermöglicht, dass Anfragen und Antworten durch viele Zwischenrouter und Server fließen, die Lastverteilung, Caching, Verschlüsselung und Kompression durchführen.
Eine grundlegende HTTP-Anfrage besteht aus einem Verb (Methode) und einer Ressource (Endpunkt). Nachfolgend sind gängige HTTP-Verben aufgeführt:
| Verb | Beschreibung | Idempotent* | Sicher | Cachefähig | |---|---|---|---|---| | GET | Liest eine Ressource | Ja | Ja | Ja | | POST | Erstellt eine Ressource oder löst einen Prozess zur Datenverarbeitung aus | Nein | Nein | Ja, falls die Antwort Frischeinformationen enthält | | PUT | Erstellt oder ersetzt eine Ressource | Ja | Nein | Nein | | PATCH | Aktualisiert eine Ressource teilweise | Nein | Nein | Ja, falls die Antwort Frischeinformationen enthält | | DELETE | Löscht eine Ressource | Ja | Nein | Nein |
*Kann mehrfach aufgerufen werden, ohne unterschiedliche Ergebnisse zu erzeugen.
HTTP ist ein Protokoll der Anwendungsschicht, das auf darunterliegenden Protokollen wie TCP und UDP basiert.
#### Quelle(n) und weiterführende Literatur: HTTP
Transmission Control Protocol (TCP)
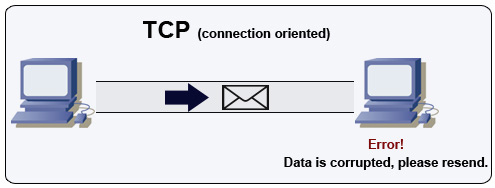
Quelle: How to make a multiplayer game
TCP ist ein verbindungsorientiertes Protokoll über ein IP-Netzwerk. Die Verbindung wird mittels eines Handshakes aufgebaut und beendet. Alle gesendeten Pakete sind garantiert in der ursprünglichen Reihenfolge und ohne Fehler am Ziel angekommen durch:
- Sequenznummern und Prüfsummenfelder für jedes Paket
- Bestätigungspakete) und automatische erneute Übertragung
Um einen hohen Durchsatz zu gewährleisten, können Webserver viele TCP-Verbindungen offen halten, was zu hohem Speicherverbrauch führt. Es kann teuer sein, viele offene Verbindungen zwischen Webserver-Threads und beispielsweise einem memcached Server zu haben. Connection Pooling kann helfen, zusätzlich zum Wechsel auf UDP, wo dies möglich ist.
TCP ist nützlich für Anwendungen, die hohe Zuverlässigkeit, aber geringere Zeitkritikalität erfordern. Beispiele sind Webserver, Datenbankinformationen, SMTP, FTP und SSH.
Verwenden Sie TCP statt UDP, wenn:
- Sie sicherstellen müssen, dass alle Daten unversehrt ankommen
- Sie automatisch die bestmögliche Netzauslastung erreichen möchten
User Datagram Protocol (UDP)
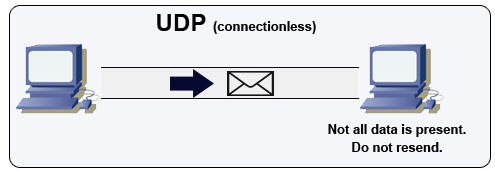
Quelle: How to make a multiplayer game
UDP ist verbindungslos. Datagramme (vergleichbar mit Paketen) sind nur auf Datagramm-Ebene garantiert. Datagramme können ihr Ziel in falscher Reihenfolge erreichen oder gar nicht. UDP unterstützt keine Staukontrolle. Ohne die Garantien, die TCP bietet, ist UDP im Allgemeinen effizienter.
UDP kann Broadcasts durchführen und Datagramme an alle Geräte im Subnetz senden. Dies ist nützlich bei DHCP, da der Client noch keine IP-Adresse erhalten hat und somit verhindert wird, dass TCP ohne IP-Adresse streamt.
UDP ist weniger zuverlässig, funktioniert aber gut in Echtzeit-Anwendungen wie VoIP, Videochat, Streaming und Echtzeit-Mehrspieler-Spielen.
Verwenden Sie UDP anstelle von TCP, wenn:
- Sie die niedrigste Latenz benötigen
- Späte Daten schlimmer als Datenverlust sind
- Sie Ihre eigene Fehlerkorrektur implementieren möchten
- Netzwerkprogrammierung für Spiele
- Wichtige Unterschiede zwischen TCP- und UDP-Protokollen
- Unterschied zwischen TCP und UDP
- Transmission Control Protocol
- User Datagram Protocol
- Memcache-Skalierung bei Facebook
Remote Procedure Call (RPC)
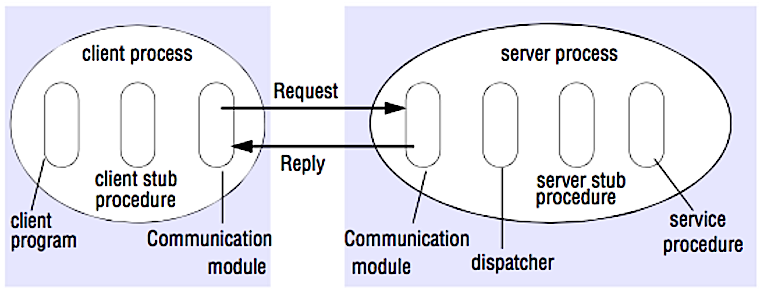
Quelle: Crack the system design interview
Bei einem RPC veranlasst ein Client die Ausführung einer Prozedur in einem anderen Adressraum, meist auf einem entfernten Server. Die Prozedur wird so programmiert, als wäre es ein lokaler Prozeduraufruf, wobei die Details der Kommunikation mit dem Server für das Clientprogramm abstrahiert werden. Remote-Aufrufe sind in der Regel langsamer und weniger zuverlässig als lokale Aufrufe, daher ist es hilfreich, RPC-Aufrufe von lokalen Aufrufen zu unterscheiden. Bekannte RPC-Frameworks sind Protobuf, Thrift und Avro.
RPC ist ein Request-Response-Protokoll:
- Client-Programm – Ruft die Client-Stub-Prozedur auf. Die Parameter werden wie bei einem lokalen Prozeduraufruf auf den Stack gelegt.
- Client-Stub-Prozedur – Marshalt (verpackt) die Prozedur-ID und Argumente in eine Anforderungsnachricht.
- Client-Kommunikationsmodul – Das Betriebssystem sendet die Nachricht vom Client zum Server.
- Server-Kommunikationsmodul – Das Betriebssystem übergibt die eingehenden Pakete an die Server-Stub-Prozedur.
- Server-Stub-Prozedur – Demarshallt die Ergebnisse, ruft die Server-Prozedur mit der passenden Prozedur-ID auf und übergibt die angegebenen Argumente.
- Die Serverantwort wiederholt die obigen Schritte in umgekehrter Reihenfolge.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC konzentriert sich darauf, Verhaltensweisen offenzulegen. RPCs werden häufig aus Leistungsgründen bei interner Kommunikation eingesetzt, da Sie native Aufrufe handhaben können, um sie besser an Ihre Anwendungsfälle anzupassen.
Wählen Sie eine native Bibliothek (auch SDK genannt), wenn:
- Sie Ihre Zielplattform kennen.
- Sie steuern möchten, wie auf Ihre "Logik" zugegriffen wird.
- Sie kontrollieren möchten, wie die Fehlerbehandlung außerhalb Ihrer Bibliothek erfolgt.
- Leistung und Benutzererfahrung sind Ihre Hauptanliegen.
#### Nachteil(e): RPC
- RPC-Clients werden eng an die Service-Implementierung gekoppelt.
- Für jede neue Operation oder jeden neuen Anwendungsfall muss eine neue API definiert werden.
- Das Debuggen von RPC kann schwierig sein.
- Sie können möglicherweise vorhandene Technologien nicht direkt nutzen. Beispielsweise kann zusätzlicher Aufwand erforderlich sein, um sicherzustellen, dass RPC-Aufrufe ordnungsgemäß zwischengespeichert werden auf Caching-Servern wie Squid.
Representational State Transfer (REST)
REST ist ein Architekturstil, der ein Client/Server-Modell erzwingt, bei dem der Client auf einen Satz von Ressourcen zugreift, die vom Server verwaltet werden. Der Server stellt eine Darstellung von Ressourcen und Aktionen bereit, die entweder Ressourcen manipulieren oder eine neue Darstellung von Ressourcen erhalten können. Die gesamte Kommunikation muss zustandslos und cachefähig sein.
Es gibt vier Eigenschaften einer RESTful-Schnittstelle:
- Ressourcen identifizieren (URI in HTTP) – Verwenden Sie unabhängig von der Operation die gleiche URI.
- Änderung durch Repräsentationen (Verben in HTTP) – Verwenden Sie Verben, Header und Body.
- Selbstbeschreibende Fehlermeldung (Statusantwort in HTTP) – Verwenden Sie Statuscodes, erfinden Sie das Rad nicht neu.
- HATEOAS (HTML-Schnittstelle für HTTP) – Ihr Webservice sollte vollständig im Browser zugänglich sein.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
REST konzentriert sich auf die Bereitstellung von Daten. Es minimiert die Kopplung zwischen Client und Server und wird häufig für öffentliche HTTP-APIs verwendet. REST nutzt eine allgemeinere und einheitlichere Methode zur Bereitstellung von Ressourcen über URIs, Repräsentation über Header und Aktionen über Verben wie GET, POST, PUT, DELETE und PATCH. Da REST zustandslos ist, eignet es sich hervorragend für horizontale Skalierung und Partitionierung.
#### Nachteil(e): REST
- Da REST auf die Bereitstellung von Daten ausgerichtet ist, eignet es sich möglicherweise nicht gut, wenn Ressourcen nicht auf natürliche Weise organisiert sind oder nicht in einer einfachen Hierarchie zugänglich sind. Beispielsweise lässt sich das Zurückgeben aller aktualisierten Datensätze der letzten Stunde, die einer bestimmten Ereignismenge entsprechen, nicht leicht als Pfad ausdrücken. Bei REST wird dies wahrscheinlich durch eine Kombination aus URI-Pfad, Abfrageparametern und möglicherweise dem Anfrageinhalt umgesetzt.
- REST verlässt sich typischerweise auf wenige Verben (GET, POST, PUT, DELETE und PATCH), die manchmal nicht zum Anwendungsfall passen. Beispielsweise passt das Verschieben abgelaufener Dokumente in den Archivordner nicht sauber in diese Verben.
- Das Abrufen komplexer Ressourcen mit verschachtelten Hierarchien erfordert mehrere Roundtrips zwischen Client und Server, um einzelne Ansichten darzustellen, z. B. das Abrufen des Inhalts eines Blog-Eintrags und der Kommentare dazu. Für mobile Anwendungen mit variablen Netzwerkbedingungen sind diese mehrfachen Roundtrips äußerst unerwünscht.
- Mit der Zeit könnten weitere Felder zur API-Antwort hinzugefügt werden, und ältere Clients erhalten alle neuen Datenfelder, auch solche, die sie nicht benötigen; dadurch wird die Payload größer und die Latenz steigt.
Vergleich von RPC- und REST-Aufrufen
| Operation | RPC | REST |
|---|---|---|
| Anmeldung | POST /signup | POST /persons |
| Kündigung | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Person lesen | GET /readPerson?personid=1234 | GET /persons/1234 |
| Liste der Gegenstände einer Person lesen | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Gegenstand zur Liste einer Person hinzufügen | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Gegenstand aktualisieren | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Gegenstand löschen | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Quelle: Do you really know why you prefer REST over RPC
#### Quellen und weiterführende Literatur: REST und RPC
- Do you really know why you prefer REST over RPC
- Wann sind RPC-ähnliche Ansätze angemessener als REST?
- REST vs JSON-RPC
- Entlarvung der Mythen von RPC und REST
- Was sind die Nachteile der Verwendung von REST
- Crack the system design interview
- Thrift
- Warum REST für interne Nutzung und nicht RPC
Sicherheit
Dieser Abschnitt könnte ein paar Aktualisierungen gebrauchen. Überlegen Sie, beizutragen!
Sicherheit ist ein umfassendes Thema. Sofern Sie nicht über umfangreiche Erfahrung, einen Sicherheits-Hintergrund verfügen oder sich auf eine Position bewerben, die Sicherheitskenntnisse erfordert, müssen Sie wahrscheinlich nicht mehr als die Grundlagen wissen:
- Verschlüsseln Sie Daten während der Übertragung und im Ruhezustand.
- Säubern Sie alle Benutzereingaben oder jegliche Eingabeparameter, die dem Benutzer zugänglich sind, um XSS und SQL-Injection zu verhindern.
- Verwenden Sie parametrisierte Abfragen, um SQL-Injection zu vermeiden.
- Nutzen Sie das Prinzip der geringsten Privilegien.
Quelle(n) und weiterführende Literatur
Anhang
Gelegentlich werden Sie gebeten, „Überschlagsrechnungen“ durchzuführen. Zum Beispiel müssen Sie vielleicht abschätzen, wie lange das Erzeugen von 100 Bild-Thumbnails von der Festplatte dauert oder wie viel Speicher eine Datenstruktur benötigt. Die Zweierpotenztabelle und Latenzwerte, die jeder Programmierer kennen sollte sind dabei nützliche Referenzen.
Zweierpotenztabelle
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Quelle(n) und weiterführende Literatur
Latenzzahlen, die jeder Programmierer kennen sollte
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Praktische Kennzahlen basierend auf den obigen Zahlen:
- Sequenzielles Lesen von HDD mit 30 MB/s
- Sequenzielles Lesen über 1 Gbps Ethernet mit 100 MB/s
- Sequenzielles Lesen von SSD mit 1 GB/s
- Sequenzielles Lesen aus dem Hauptspeicher mit 4 GB/s
- 6-7 weltweite Round-Trips pro Sekunde
- 2.000 Round-Trips pro Sekunde innerhalb eines Rechenzentrums
#### Quelle(n) und weiterführende Literatur
- Latenzzeiten, die jeder Programmierer kennen sollte - 1
- Latenzzeiten, die jeder Programmierer kennen sollte - 2
- Designs, Lektionen und Ratschläge aus dem Bau großer verteilter Systeme
- Software-Engineering-Ratschläge aus dem Bau großskaliger verteilter Systeme
Weitere Fragen zum Systemdesign-Interview
Gängige Fragen zum Systemdesign-Interview mit Links zu Ressourcen, wie man jede löst.
| Frage | Referenz(en) |
|---|---|
| Entwerfen Sie einen Datei-Sync-Dienst wie Dropbox | youtube.com |
| Entwerfen Sie eine Suchmaschine wie Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Entwerfen Sie einen skalierbaren Web-Crawler wie Google | quora.com |
| Entwerfen Sie Google Docs | code.google.com
neil.fraser.name |
| Entwerfen Sie einen Key-Value-Store wie Redis | slideshare.net |
| Entwerfen Sie ein Cache-System wie Memcached | slideshare.net |
| Entwerfen Sie ein Empfehlungssystem wie das von Amazon | hulu.com
ijcai13.org |
| Entwerfen Sie ein TinyURL-System wie Bitly | n00tc0d3r.blogspot.com |
| Entwerfen Sie eine Chat-App wie WhatsApp | highscalability.com
| Entwerfen Sie ein Bilder-Sharing-System wie Instagram | highscalability.com
highscalability.com |
| Entwerfen Sie die Facebook-Newsfeed-Funktion | quora.com
quora.com
slideshare.net |
| Entwerfen Sie die Facebook-Timeline-Funktion | facebook.com
highscalability.com |
| Entwerfen Sie die Facebook-Chat-Funktion | erlang-factory.com
facebook.com |
| Entwerfen Sie eine Graph-Suchfunktion wie Facebooks | facebook.com
facebook.com
facebook.com |
| Entwerfen Sie ein Content Delivery Network wie CloudFlare | figshare.com |
| Entwerfen Sie ein Trending Topic System wie das von Twitter | michael-noll.com
snikolov .wordpress.com |
| Entwerfen Sie ein System zur zufälligen ID-Generierung | blog.twitter.com
github.com |
| Geben Sie die Top-k-Anfragen in einem Zeitintervall zurück | cs.ucsb.edu
wpi.edu |
| Entwerfen Sie ein System, das Daten aus mehreren Rechenzentren bereitstellt | highscalability.com |
| Entwerfen Sie ein Online-Multiplayer-Kartenspiel | indieflashblog.com
buildnewgames.com |
| Entwerfen Sie ein Garbage Collection System | stuffwithstuff.com
washington.edu |
| Entwerfen Sie einen API-Rate-Limiter | https://stripe.com/blog/ |
| Entwerfen Sie eine Börse (wie NASDAQ oder Binance) | Jane Street
Golang Implementation
Go Implementation |
| Fügen Sie eine Systemdesign-Frage hinzu | Contribute |
Architekturen aus der realen Welt
Artikel darüber, wie reale Systeme entworfen werden.
Quelle: Twitter timelines at scale
Konzentrieren Sie sich bei den folgenden Artikeln nicht auf kleinste Details, sondern:
- Identifizieren Sie gemeinsame Prinzipien, Technologien und Muster in diesen Artikeln
- Studieren Sie, welche Probleme durch jede Komponente gelöst werden, wo sie funktioniert und wo nicht
- Überprüfen Sie die gewonnenen Erkenntnisse
Unternehmensarchitekturen
| Unternehmen | Referenz(en) |
|---|---|
| Amazon | Amazon Architektur |
| Cinchcast | Produktion von 1.500 Stunden Audio täglich |
| DataSift | Echtzeit-Datenanalyse bei 120.000 Tweets pro Sekunde |
| Dropbox | Wie wir Dropbox skaliert haben |
| ESPN | Betrieb mit 100.000 duh nuh nuhs pro Sekunde |
| Google | Google Architektur |
| Instagram | 14 Millionen Nutzer, Terabytes an Fotos
Was Instagram antreibt |
| Justin.tv | Live-Video-Übertragungsarchitektur von Justin.tv |
| Facebook | Memcached-Skalierung bei Facebook
TAO: Facebooks verteiltes Datenspeichersystem für das soziale Netzwerk
Facebooks Foto-Speicherung
Wie Facebook Live Streams für 800.000 gleichzeitige Zuschauer bereitstellt |
| Flickr | Flickr Architektur |
| Mailbox | Von 0 auf eine Million Nutzer in 6 Wochen |
| Netflix | Ein 360-Grad-Blick auf den gesamten Netflix-Stack
Netflix: Was passiert, wenn Sie Play drücken? |
| Pinterest | Von 0 auf dutzende Milliarden Seitenaufrufe pro Monat
18 Millionen Besucher, 10-faches Wachstum, 12 Mitarbeiter |
| Playfish | 50 Millionen monatliche Nutzer und steigend |
| PlentyOfFish | PlentyOfFish Architektur |
| Salesforce | Wie sie 1,3 Milliarden Transaktionen pro Tag verarbeiten |
| Stack Overflow | Stack Overflow Architektur |
| TripAdvisor | 40M Besucher, 200M dynamische Seitenaufrufe, 30TB Daten |
| Tumblr | 15 Milliarden Seitenaufrufe pro Monat |
| Twitter | Twitter 10.000 Prozent schneller machen
250 Millionen Tweets pro Tag mit MySQL speichern
150M aktive Nutzer, 300K QPS, ein 22 MB/S-Datenstrom
Timelines im großen Maßstab
Große und kleine Daten bei Twitter
Betrieb bei Twitter: Skalierung über 100 Millionen Nutzer hinaus
Wie Twitter 3.000 Bilder pro Sekunde verarbeitet |
| Uber | Wie Uber seine Echtzeit-Marktplattform skaliert
Lektionen aus dem Skalieren von Uber auf 2000 Ingenieure, 1000 Services und 8000 Git-Repositories |
| WhatsApp | Die WhatsApp-Architektur, die Facebook für 19 Milliarden Dollar kaufte |
| YouTube | YouTube Skalierbarkeit
YouTube Architektur |
Ingenieurblogs von Unternehmen
Architekturen von Unternehmen, bei denen Sie sich bewerben.>
Fragen, denen Sie begegnen, könnten aus demselben Bereich stammen.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Möchten Sie einen Blog hinzufügen? Um doppelte Arbeit zu vermeiden, sollten Sie Ihren Firmenblog zu folgendem Repository hinzufügen:
In Entwicklung
Interessiert daran, einen Abschnitt hinzuzufügen oder bei einem laufenden mitzuhelfen? Mitmachen!
- Verteiltes Rechnen mit MapReduce
- Konsistentes Hashing
- Scatter Gather
- Mitmachen
Danksagungen
Quellen und Danksagungen sind über dieses Repository verteilt aufgeführt.
Besonderer Dank an:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Kontaktinformationen
Zögern Sie nicht, mich zu kontaktieren, um etwaige Probleme, Fragen oder Kommentare zu besprechen.
Meine Kontaktdaten finden Sie auf meiner GitHub-Seite.
Lizenz
Ich stelle Ihnen Code und Ressourcen in diesem Repository unter einer Open-Source-Lizenz zur Verfügung. Da dies mein persönliches Repository ist, erhalten Sie die Lizenz für meinen Code und meine Ressourcen von mir und nicht von meinem Arbeitgeber (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---