ACEBench:谁将在工具使用中赢得赛点?
English | 中文
📚 目录
---🛠️ 更新 [[返回顶部]](#content)
[2025.10.29]
1 我们已修正 normal_atom_enum_9、normal_atom_number_17 和 normal_atom_list_34 数据集中的可能答案。
📘 1\. 摘要 [[返回顶部]](#content)
Large Language Models (LLMs) have demonstrated significant potential in decision-making and reasoning, particularly when integrated with various tools to effectively solve complex problems. However, existing benchmarks for evaluating LLMs' tool usage face several limitations: (1) limited evaluation scenarios, often lacking assessments in real multi-turn dialogue contexts; (2) narrow evaluation dimensions, with insufficient detailed assessments of how LLMs use tools; and (3) reliance on LLMs or real API executions for evaluation, which introduces significant overhead. To address these challenges, we introduce ACEBench, a comprehensive benchmark for assessing tool usage in LLMs. ACEBench categorizes data into three primary types based on evaluation methodology: Normal, Special, and Agent. "Normal" evaluates tool usage in basic scenarios; "Special" evaluates tool usage in situations with ambiguous or incomplete instructions; "Agent" evaluates tool usage through multi-agent interactions to simulate real-world, multi-turn dialogues. We conducted extensive experiments using ACEBench, analyzing various LLMs in-depth and providing a more granular examination of error causes across different data types.
📊 2.基准数据分析 [[返回顶部]](#content)
API领域
- ACEBench涵盖了8个主要领域和68个子领域,包括技术、金融、娱乐、社会、健康、文化、环境等。
- 共包含4,538个API,涵盖中英文。
- 各领域API分布如下面图所示:
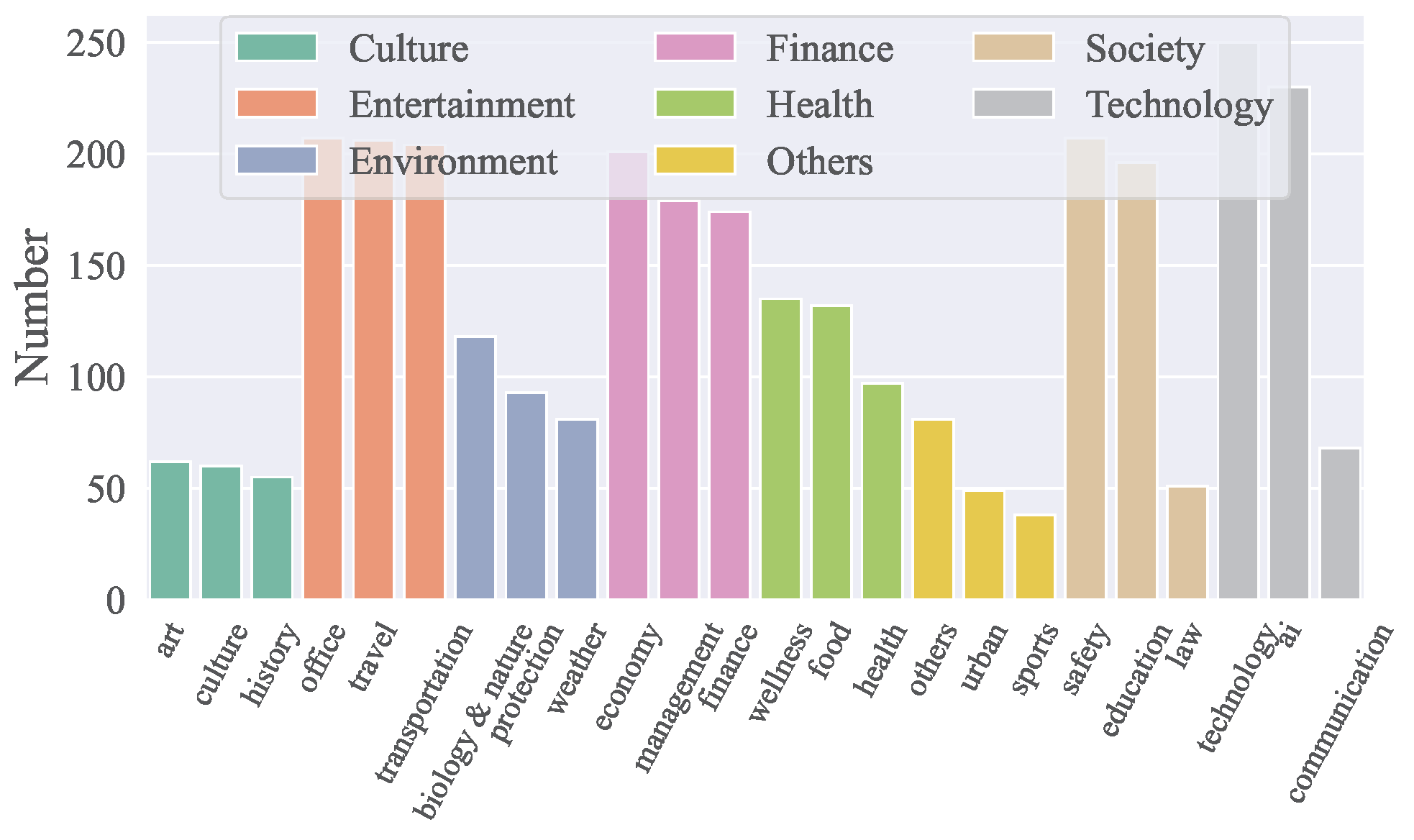
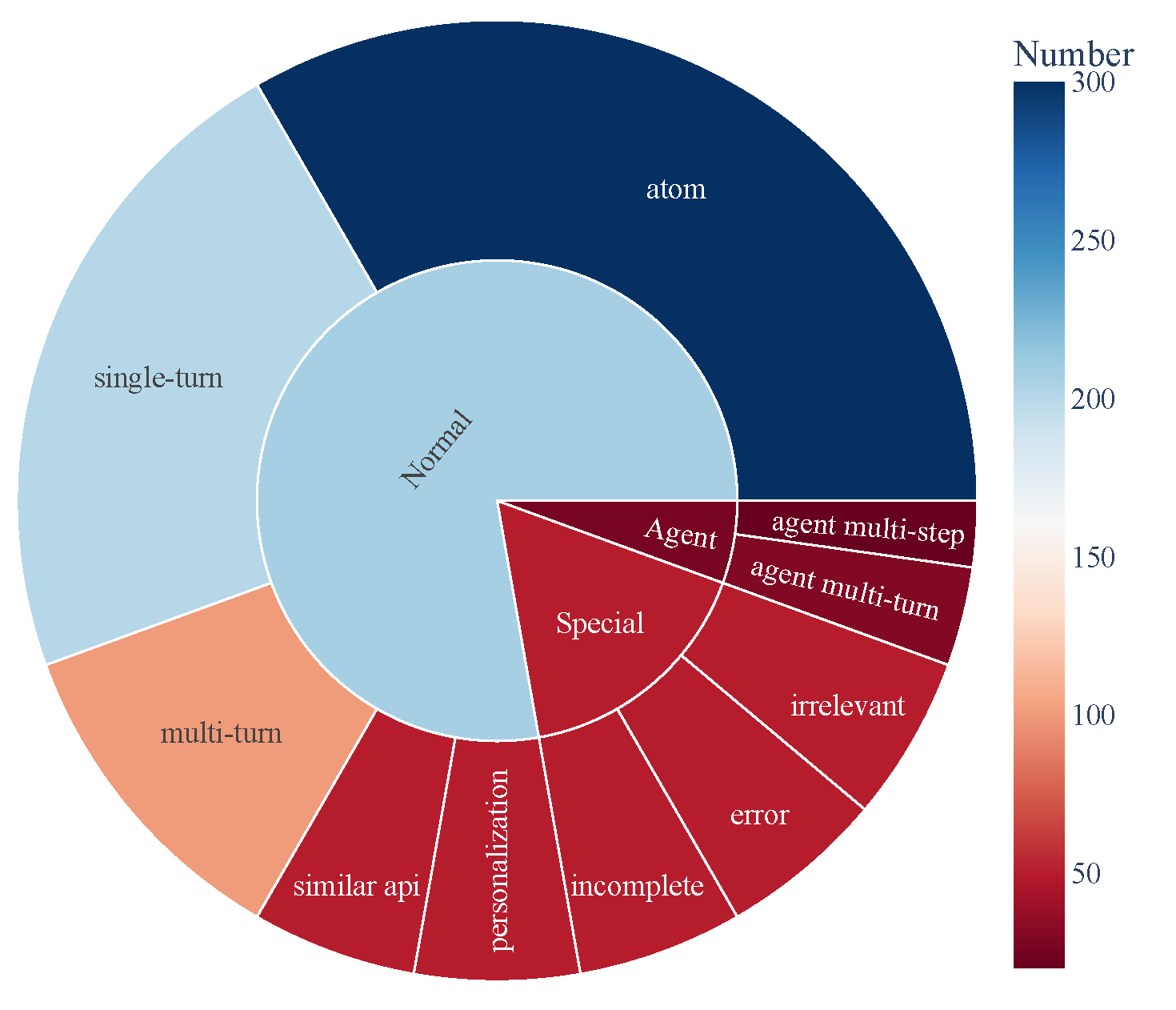
数据组成
- ACEBench包含三大类测试样本:
- Normal:基础工具使用场景。
- Agent:涉及用户与环境的多轮交互。
- Special:需要多步骤或处理不可行工具调用的复杂场景。
- 数据组成如下图,展示了工具使用能力的全面覆盖:
🏆 3\. 排行榜 [[返回顶部]](#content)
| 模型 | normal | special | agent | overall | | ------------------------------------- | ------ | ------- | ----- | ------- | | 闭源模型 | | gpt-4o-2024-11-20 | 0.927 | 0.933 | 0.715 | 0.896 | | gpt-4-turbo-2024-04-09 | 0.917 | 0.913 | 0.725 | 0.886 |
| qwen-max | 0.887 | 0.740 | 0.685 | 0.817 | | o1-preview | 0.830 | 0.793 | 0.735 | 0.806 | | deepseek-chat | 0.926 | 0.733 | 0.350 | 0.785 | | gpt-4o-mini-2024-07-18 | 0.834 | 0.813 | 0.390 | 0.760 | | claude-3-5-sonnet-20241022 | 0.835 | 0.820 | 0.350 | 0.756 | | gemini-1.5-pro | 0.822 | 0.800 | 0.250 | 0.728 | | o1-mini | 0.774 | 0.673 | 0.610 | 0.722 | | doubao-pro-32k | 0.750 | 0.593 | 0.235 | 0.628 | | 开源模型 | | Qwen2.5-Coder-32B-Instruct-local | 0.908 | 0.813 | 0.715 | 0.853 | | Qwen2.5-32B-Instruct-local | 0.852 | 0.747 | 0.690 | 0.799 | | Qwen2.5-72B-Instruct-local | 0.873 | 0.773 | 0.525 | 0.793 | | Qwen2.5-Coder-14B-Instruct-local | 0.868 | 0.647 | 0.525 | 0.756 | | Qwen2.5-14B-Instruct-local | 0.790 | 0.540 | 0.250 | 0.640 | | Llama-3.1-70B-Instruct-local | 0.753 | 0.473 | 0.435 | 0.629 | | Qwen2.5-7B-Instruct-local | 0.759 | 0.447 | 0.125 | 0.578 | | DeepSeek-Coder-V2-Lite-Instruct-local | 0.688 | 0.413 | 0.015 | 0.511 | | Qwen2.5-Coder-7B-Instruct-local | 0.735 | 0.193 | 0.125 | 0.496 | | watt-tool-8B-local | 0.763 | 0.100 | 0.040 | 0.474 | | ToolACE-8B-local | 0.782 | 0.013 | 0.040 | 0.462 | | Hammer2.1-7b-local | 0.627 | 0.260 | 0.185 | 0.461 | | Meta-Llama-3.1-8B-Instruct-local | 0.450 | 0.267 | 0.040 | 0.338 | | Qwen2.5-Coder-3B-Instruct-local | 0.495 | 0.100 | 0.065 | 0.323 | | Phi-3-mini-128k-instruct-local | 0.389 | 0.253 | 0.015 | 0.295 | | Qwen2.5-3B-Instruct-local | 0.408 | 0.127 | 0.065 | 0.280 | | Llama-3.2-3B-Instruct-local | 0.327 | 0.100 | 0.000 | 0.216 | | xLAM-7b-r-local | 0.187 | 0.013 | 0.075 | 0.123 | | Hammer2.1-3b-local | 0.118 | 0.013 | 0.015 | 0.074 |
🛠️ 4\. 环境配置 [[返回顶部]](#content)
执行以下命令以安装推理和评估所需的依赖项:
pip install -r requirements.txt🗂️ 5\. 数据 [[返回顶部]](#content)
所有数据存储在 data_all 目录中,分为英文和中文两部分,分别位于 data_en 和 data_zh 文件夹中。每个文件夹包含多个 JSON 文件,命名格式为 data_{category}.json,其中 category 表示数据的类型。
data_all/
├── possible_answer_en/
│ ├── data_{normal}.json
│ ├── data_{special}.json
│ ├── data_{agent}.json
├── possible_answer_zh/
│ ├── data_{normal}.json
│ ├── data_{special}.json
│ ├── data_{agent}.json
...🧠 6\. 推理 [[返回顶部]](#content)
6.1 推理脚本
要使用 cmodels 进行推理,请使用 generate.py 脚本。该脚本支持多种模型、类别和语言。
基本用法
python generate.py --model --model_path
--category --language --model:指定用于推理的模型。--model_path:指定模型的本地路径(仅适用于开源模型)。--category:定义要评估的任务或数据集类别。可用类别见 eval_checker/eval_checker_constant.py。--language:指定输入/输出的语言。支持的语言:“en”(英语)、“zh”(中文)
6.2\. 推理示例
针对闭源模型
python generate.py --model qwen-max --category test_all --language zh用于本地模型
python generate.py --model Qwen2.5-3B-Instruct-local --model-path /mnt/nas/ckpt/Qwen2.5-3B-Instruct --category test_all --language zh6.3\. 注意事项
- 运行程序前,确保环境变量 .env 文件配置正确。调用 OpenAI 需要使用外网,配置环境变量 https_proxy 和 http_proxy。使用 gemini 模型需要使用日本代理。
- 待评估的模型需在 model_inference/inference_map.py 中映射。通过 OpenAI 调用的模型可添加到 APIModelInference 列表,自定义推理模型可添加到 CommonInference 列表。 本地模型名称以 -local 结尾。
- 添加自定义评估模型时,参考 model_inference/model_infer.py 将模型类添加到 model_dict。
- 对 Hugging Face 上的开源模型进行评估,建议使用 LLaMA-Factory 结合 LoRA 权重后推理。
📈 7. 评估 [[返回顶部]](#content)
使用 eval_main.py 脚本评估模型性能。该脚本支持多种评估指标,适用于开源和闭源模型。
基本用法
python eval_main.py --model --category --language 📄 引用
如果您觉得我们的论文和资源有用,请考虑引用我们的论文:
@article{chen2025acebench,
title={ACEBench: Who Wins the Match Point in Tool Learning?},
author={Chen, Chen and Hao, Xinlong and Liu, Weiwen and Huang, Xu and Zeng, Xingshan and Yu, Shuai and Li, Dexun and Wang, Shuai and Gan, Weinan and Huang, Yuefeng and others},
journal={arXiv preprint arXiv:2501.12851},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-19 ---