ACEBench: 도구 사용에서 매치 포인트를 누가 차지하는가?
English | 中文
📚 목차
---🛠️ 업데이트 [[맨 위로]](#content)
[2025.10.29]
1 normal_atom_enum_9, normal_atom_number_17, normal_atom_list_34 데이터셋에서 가능한 답변을 수정하였습니다.
📘 1\. 초록 [[맨 위로]](#content)
Large Language Models (LLMs) have demonstrated significant potential in decision-making and reasoning, particularly when integrated with various tools to effectively solve complex problems. However, existing benchmarks for evaluating LLMs' tool usage face several limitations: (1) limited evaluation scenarios, often lacking assessments in real multi-turn dialogue contexts; (2) narrow evaluation dimensions, with insufficient detailed assessments of how LLMs use tools; and (3) reliance on LLMs or real API executions for evaluation, which introduces significant overhead. To address these challenges, we introduce ACEBench, a comprehensive benchmark for assessing tool usage in LLMs. ACEBench categorizes data into three primary types based on evaluation methodology: Normal, Special, and Agent. "Normal" evaluates tool usage in basic scenarios; "Special" evaluates tool usage in situations with ambiguous or incomplete instructions; "Agent" evaluates tool usage through multi-agent interactions to simulate real-world, multi-turn dialogues. We conducted extensive experiments using ACEBench, analyzing various LLMs in-depth and providing a more granular examination of error causes across different data types.
📊 2.벤치마크 데이터 분석 [[맨 위로]](#content)
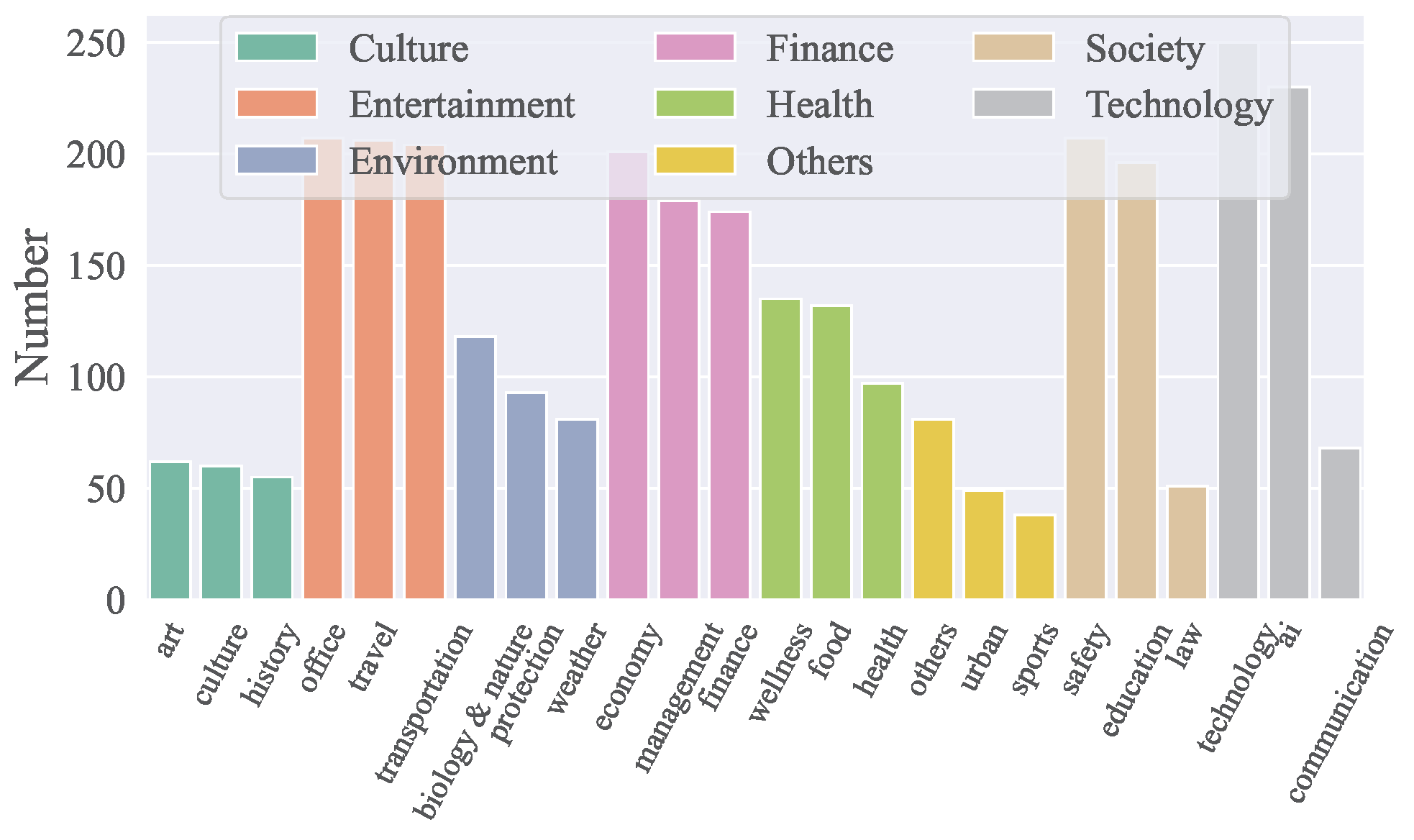
API 도메인
- ACEBench는 기술, 금융, 엔터테인먼트, 사회, 건강, 문화, 환경 등 8개 주요 도메인과 68개 하위 도메인을 포함합니다.
- 중국어와 영어로 총 4,538개의 API를 포함하고 있습니다.
- 도메인별 API 분포는 아래 그림에 시각화되어 있습니다:
데이터 구성
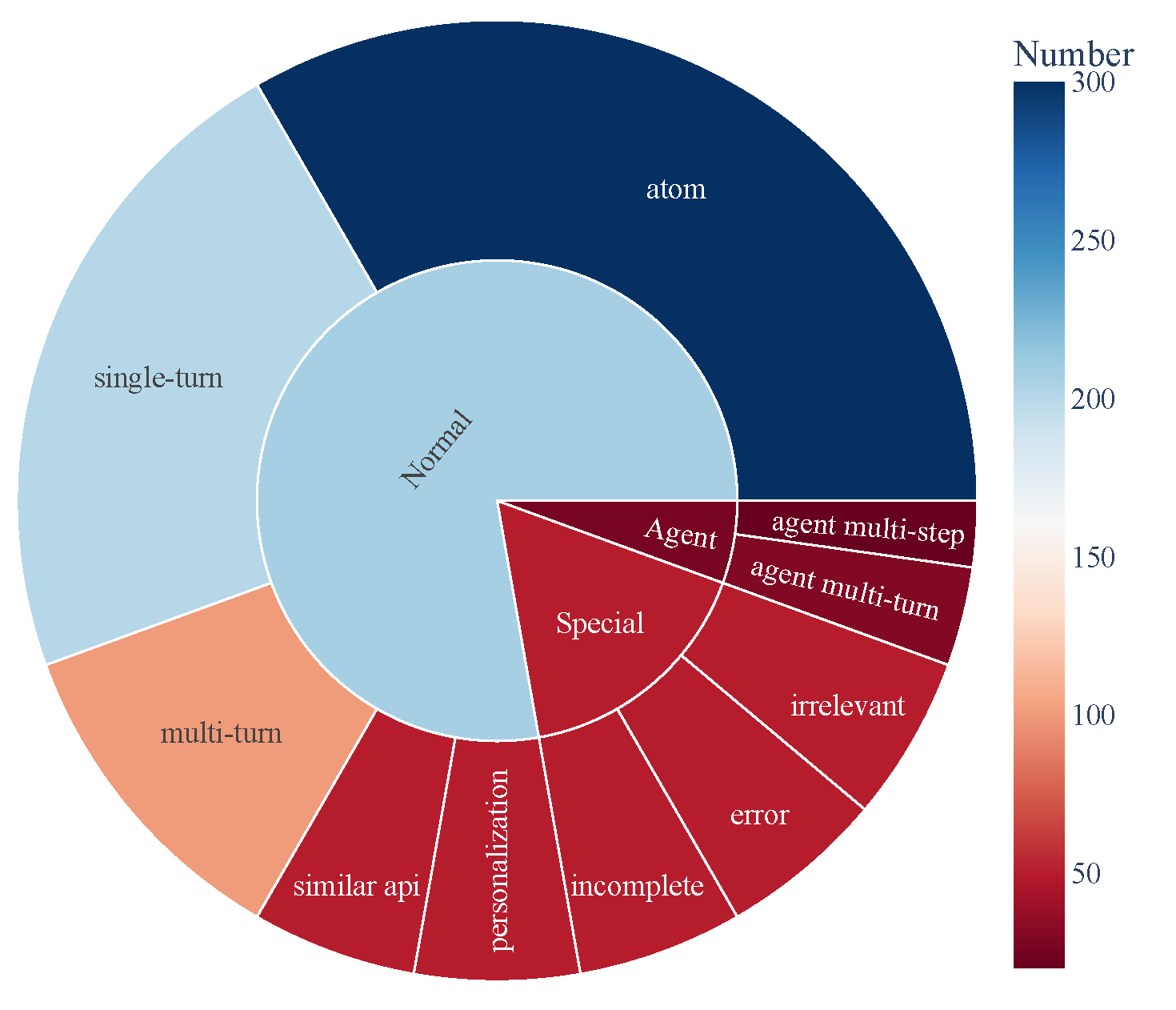
- ACEBench는 세 가지 주요 범주의 테스트 샘플로 구성됩니다:
- 일반(Normal): 기본 도구 사용 시나리오.
- 에이전트(Agent): 사용자와 환경 간의 다중 턴 상호작용.
- 특수(Special): 여러 단계를 요구하거나 실행 불가능한 도구 호출을 처리하는 복잡한 시나리오.
- 데이터 구성은 아래와 같이 시각화되어 도구 사용 능력의 포괄적 범위를 보여줍니다:
🏆 3\. 리더보드 [[맨 위로]](#content)
| 모델 | 일반 | 특수 | 에이전트 | 전체 | | ------------------------------------- | ------ | ------- | ------- | ------- | | 비공개 소스 모델 | | gpt-4o-2024-11-20 | 0.927 | 0.933 | 0.715 | 0.896 | | gpt-4-turbo-2024-04-09 | 0.917 | 0.913 | 0.725 | 0.886 | | qwen-max | 0.887 | 0.740 | 0.685 | 0.817 | | o1-preview | 0.830 | 0.793 | 0.735 | 0.806 | | deepseek-chat | 0.926 | 0.733 | 0.350 | 0.785 | | gpt-4o-mini-2024-07-18 | 0.834 | 0.813 | 0.390 | 0.760 | | claude-3-5-sonnet-20241022 | 0.835 | 0.820 | 0.350 | 0.756 | | gemini-1.5-pro | 0.822 | 0.800 | 0.250 | 0.728 | | o1-mini | 0.774 | 0.673 | 0.610 | 0.722 | | doubao-pro-32k | 0.750 | 0.593 | 0.235 | 0.628 | | 오픈 소스 모델 | | Qwen2.5-Coder-32B-Instruct-local | 0.908 | 0.813 | 0.715 | 0.853 | | Qwen2.5-32B-Instruct-local | 0.852 | 0.747 | 0.690 | 0.799 | | Qwen2.5-72B-Instruct-local | 0.873 | 0.773 | 0.525 | 0.793 | | Qwen2.5-Coder-14B-Instruct-local | 0.868 | 0.647 | 0.525 | 0.756 | | Qwen2.5-14B-Instruct-local | 0.790 | 0.540 | 0.250 | 0.640 | | Llama-3.1-70B-Instruct-local | 0.753 | 0.473 | 0.435 | 0.629 | | Qwen2.5-7B-Instruct-local | 0.759 | 0.447 | 0.125 | 0.578 | | DeepSeek-Coder-V2-Lite-Instruct-local | 0.688 | 0.413 | 0.015 | 0.511 | | Qwen2.5-Coder-7B-Instruct-local | 0.735 | 0.193 | 0.125 | 0.496 | | watt-tool-8B-local | 0.763 | 0.100 | 0.040 | 0.474 | | ToolACE-8B-local | 0.782 | 0.013 | 0.040 | 0.462 | | Hammer2.1-7b-local | 0.627 | 0.260 | 0.185 | 0.461 | | Meta-Llama-3.1-8B-Instruct-local | 0.450 | 0.267 | 0.040 | 0.338 | | Qwen2.5-Coder-3B-Instruct-local | 0.495 | 0.100 | 0.065 | 0.323 | | Phi-3-mini-128k-instruct-local | 0.389 | 0.253 | 0.015 | 0.295 | | Qwen2.5-3B-Instruct-local | 0.408 | 0.127 | 0.065 | 0.280 | | Llama-3.2-3B-Instruct-local | 0.327 | 0.100 | 0.000 | 0.216 | | xLAM-7b-r-local | 0.187 | 0.013 | 0.075 | 0.123 | | Hammer2.1-3b-local | 0.118 | 0.013 | 0.015 | 0.074 |
🛠️ 4\. 설치 [[맨 위로 이동]](#content)
추론 및 평가에 필요한 의존성을 설치하려면 다음 명령어를 실행하세요:
pip install -r requirements.txt🗂️ 5\. 데이터 [[맨 위로]](#content)
모든 데이터는 data_all 디렉터리에 저장되어 있으며, 영어와 중국어 부분으로 나누어져 각각 data_en 및 data_zh 폴더에 위치합니다. 각 폴더에는 data_{category}.json 형식으로 이름 붙여진 여러 개의 JSON 파일이 포함되어 있으며, 여기서 category는 데이터 유형을 나타냅니다.
data_all/
├── possible_answer_en/
│ ├── data_{normal}.json
│ ├── data_{special}.json
│ ├── data_{agent}.json
├── possible_answer_zh/
│ ├── data_{normal}.json
│ ├── data_{special}.json
│ ├── data_{agent}.json
...🧠 6\. 추론 [[맨 위로]](#content)
6.1 추론 스크립트
cmodels로 추론을 실행하려면 generate.py 스크립트를 사용하세요. 이 스크립트는 다양한 모델, 카테고리 및 언어를 지원합니다.
기본 사용법
python generate.py --model --model_path
--category --language --model: 추론에 사용할 모델을 지정합니다.--model_path: 모델의 로컬 경로를 지정합니다 (오픈 소스 모델에만 해당).--category: 평가할 작업 또는 데이터셋의 카테고리를 정의합니다. 사용 가능한 카테고리는 eval_checker/eval_checker_constant.py에서 확인할 수 있습니다.--language: 입력/출력의 언어를 지정합니다. 지원 언어: "en" (영어), "zh" (중국어)
6.2\. 추론 예제
비공개 소스 모델용
python generate.py --model qwen-max --category test_all --language zhpython generate.py --model Qwen2.5-3B-Instruct-local --model-path /mnt/nas/ckpt/Qwen2.5-3B-Instruct --category test_all --language zh6.3\. 주의사항
- 프로그램을 실행하기 전에 환경 변수 .env 파일이 올바르게 설정되어 있는지 확인하세요. OpenAI를 호출하려면 외부 네트워크를 사용해야 합니다. 환경 변수 https_proxy와 http_proxy를 설정하세요. gemini 모델을 사용하려면 일본 프록시를 사용해야 합니다.
- 평가할 모델은 model_inference/inference_map.py에 매핑되어야 합니다. OpenAI를 통해 호출되는 모델은 APIModelInference 리스트에 추가할 수 있으며, 커스터마이즈된 추론 모델은 CommonInference 리스트에 추가할 수 있습니다. 로컬 모델의 이름은 -local로 끝납니다.
- 커스터마이즈된 평가 모델을 추가하려면 model_inference/model_infer.py를 참고하여 model_dict에 모델 클래스를 추가하세요.
- 오픈 소스 모델은 Hugging Face에서 평가하세요. LoRA 가중치를 결합하여 추론하려면 LLaMA-Factory를 사용하는 것이 권장됩니다.
📈 7. 평가 [[맨 위로]](#content)
모델 성능을 평가하려면 eval_main.py 스크립트를 사용하세요. 이 스크립트는 다양한 평가 지표를 지원하며 오픈 소스 및 폐쇄 소스 모델 모두에 사용할 수 있습니다.
기본 사용법
python eval_main.py --model --category --language 📄 인용
저희 논문과 자료가 유용하다면, 논문을 인용해 주시기 바랍니다:
@article{chen2025acebench,
title={ACEBench: Who Wins the Match Point in Tool Learning?},
author={Chen, Chen and Hao, Xinlong and Liu, Weiwen and Huang, Xu and Zeng, Xingshan and Yu, Shuai and Li, Dexun and Wang, Shuai and Gan, Weinan and Huang, Yuefeng and others},
journal={arXiv preprint arXiv:2501.12851},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-19 ---