ACEBench: ¿Quién Gana el Punto de Partido en el Uso de Herramientas?
📃 Artículo · 🏆 Tabla de Clasificación (Actualizada Continuamente)
English | 中文
📚 Contenido
- 1\. Resumen
- 2\. Estadísticas del Benchmark
- 3\. Tabla de Clasificación
- 4\. Configuración
- 5\. Datos
- 6\. Inferencia
- 6.1\. Script de Inferencia
- 6.2\. Ejemplos de Inferencia
- 7\. Evaluación
- Citación
🛠️ Actualizaciones [[Volver Arriba]](#content)
[2025.10.29]
1 Hemos corregido las posibles respuestas en los conjuntos de datos normal_atom_enum_9, normal_atom_number_17, y normal_atom_list_34.
📘 1\. Resumen [[Volver Arriba]](#content)
Large Language Models (LLMs) have demonstrated significant potential in decision-making and reasoning, particularly when integrated with various tools to effectively solve complex problems. However, existing benchmarks for evaluating LLMs' tool usage face several limitations: (1) limited evaluation scenarios, often lacking assessments in real multi-turn dialogue contexts; (2) narrow evaluation dimensions, with insufficient detailed assessments of how LLMs use tools; and (3) reliance on LLMs or real API executions for evaluation, which introduces significant overhead. To address these challenges, we introduce ACEBench, a comprehensive benchmark for assessing tool usage in LLMs. ACEBench categorizes data into three primary types based on evaluation methodology: Normal, Special, and Agent. "Normal" evaluates tool usage in basic scenarios; "Special" evaluates tool usage in situations with ambiguous or incomplete instructions; "Agent" evaluates tool usage through multi-agent interactions to simulate real-world, multi-turn dialogues. We conducted extensive experiments using ACEBench, analyzing various LLMs in-depth and providing a more granular examination of error causes across different data types.
📊 2.Análisis de Datos de Referencia [[Volver al Inicio]](#content)
Dominio de las APIs
- ACEBench cubre 8 dominios principales y 68 subdominios, incluyendo tecnología, finanzas, entretenimiento, sociedad, salud, cultura, medio ambiente y más.
- Incluye un total de 4,538 APIs tanto en chino como en inglés.
- La distribución de APIs por dominios se visualiza en la figura a continuación:
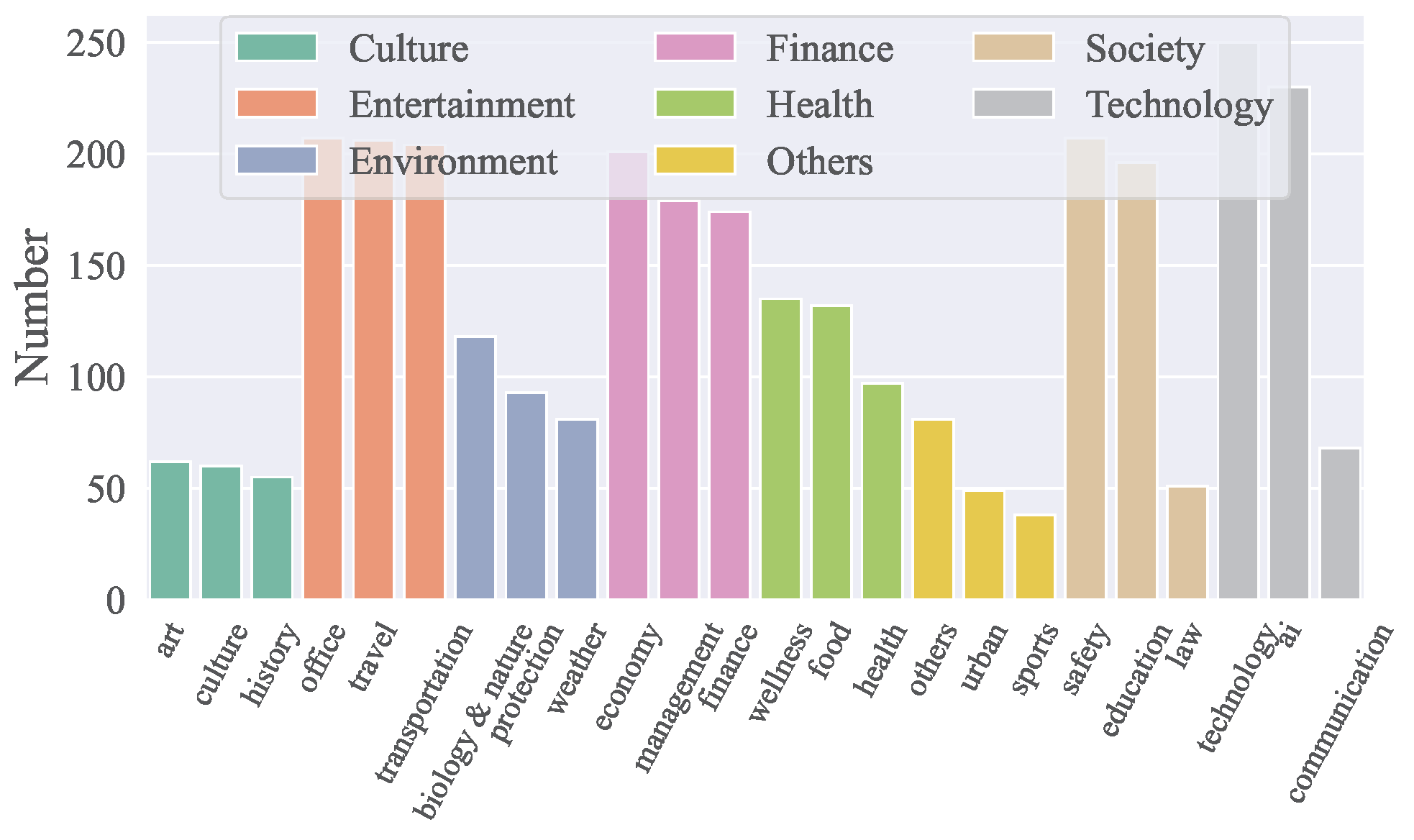
Composición de Datos
- ACEBench consiste en tres categorías principales de muestras de prueba:
- Normal: Escenarios básicos de uso de herramientas.
- Agente: Interacciones multi-turno que involucran usuarios y entornos.
- Especial: Escenarios complejos que requieren múltiples pasos o manejo de llamadas a herramientas inviables.
- La composición de los datos se visualiza a continuación, mostrando la cobertura integral de las capacidades de uso de herramientas:
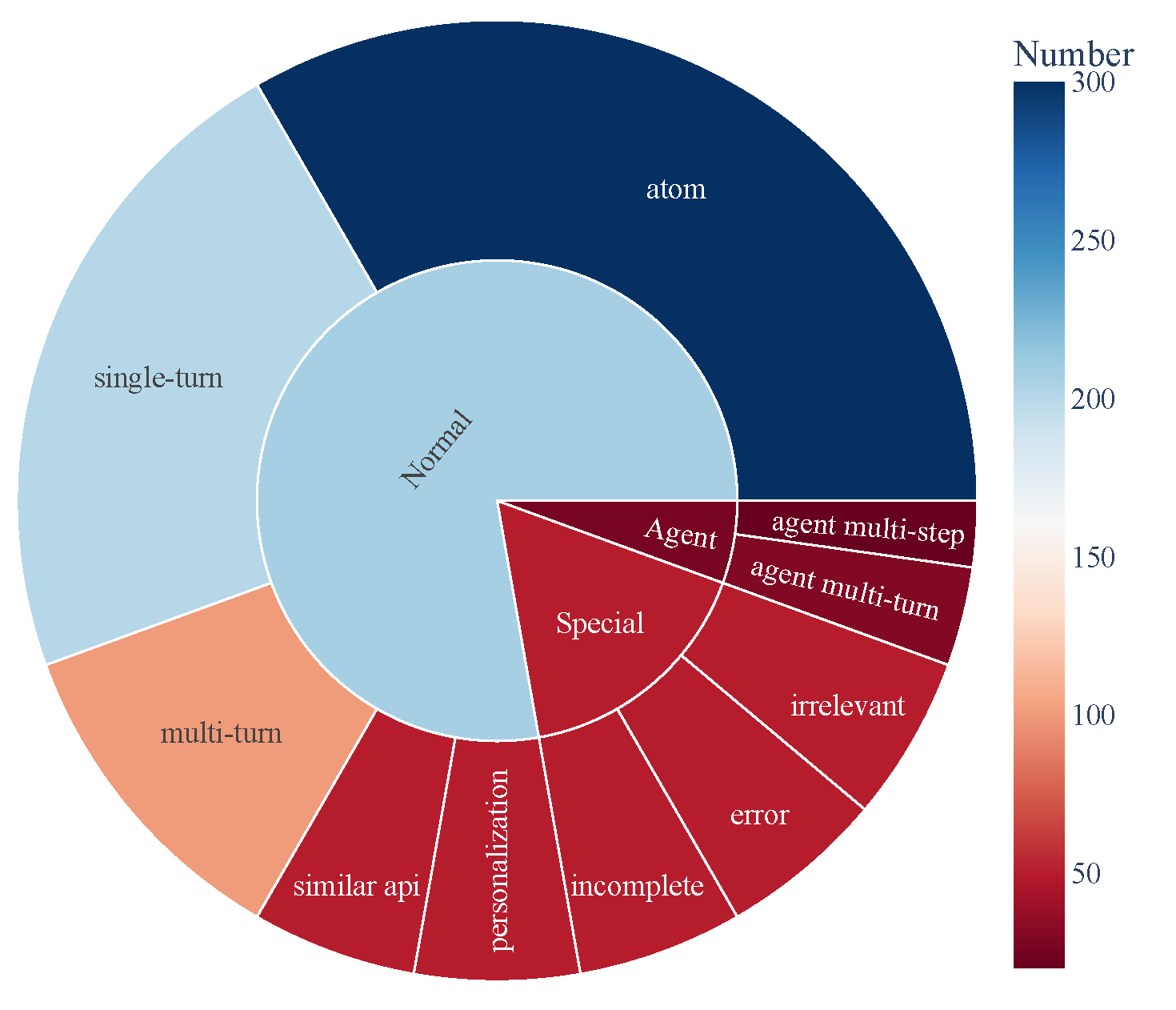
🏆 3\. Tabla de Clasificación [[Volver al Inicio]](#content)
| Modelo | normal | especial | agente | general | | ------------------------------------- | ------ | ------- | ----- | ------- | | modelo cerrado | | gpt-4o-2024-11-20 | 0.927 | 0.933 | 0.715 | 0.896 | | gpt-4-turbo-2024-04-09 | 0.917 | 0.913 | 0.725 | 0.886 | | qwen-max | 0.887 | 0.740 | 0.685 | 0.817 | | o1-preview | 0.830 | 0.793 | 0.735 | 0.806 | | deepseek-chat | 0.926 | 0.733 | 0.350 | 0.785 | | gpt-4o-mini-2024-07-18 | 0.834 | 0.813 | 0.390 | 0.760 | | claude-3-5-sonnet-20241022 | 0.835 | 0.820 | 0.350 | 0.756 | | gemini-1.5-pro | 0.822 | 0.800 | 0.250 | 0.728 | | o1-mini | 0.774 | 0.673 | 0.610 | 0.722 | | doubao-pro-32k | 0.750 | 0.593 | 0.235 | 0.628 | | modelo de código abierto | | Qwen2.5-Coder-32B-Instruct-local | 0.908 | 0.813 | 0.715 | 0.853 | | Qwen2.5-32B-Instruct-local | 0.852 | 0.747 | 0.690 | 0.799 | | Qwen2.5-72B-Instruct-local | 0.873 | 0.773 | 0.525 | 0.793 | | Qwen2.5-Coder-14B-Instruct-local | 0.868 | 0.647 | 0.525 | 0.756 | | Qwen2.5-14B-Instruct-local | 0.790 | 0.540 | 0.250 | 0.640 | | Llama-3.1-70B-Instruct-local | 0.753 | 0.473 | 0.435 | 0.629 | | Qwen2.5-7B-Instruct-local | 0.759 | 0.447 | 0.125 | 0.578 | | DeepSeek-Coder-V2-Lite-Instruct-local | 0.688 | 0.413 | 0.015 | 0.511 | | Qwen2.5-Coder-7B-Instruct-local | 0.735 | 0.193 | 0.125 | 0.496 | | watt-tool-8B-local | 0.763 | 0.100 | 0.040 | 0.474 | | ToolACE-8B-local | 0.782 | 0.013 | 0.040 | 0.462 | | Hammer2.1-7b-local | 0.627 | 0.260 | 0.185 | 0.461 | | Meta-Llama-3.1-8B-Instruct-local | 0.450 | 0.267 | 0.040 | 0.338 | | Qwen2.5-Coder-3B-Instruct-local | 0.495 | 0.100 | 0.065 | 0.323 | | Phi-3-mini-128k-instruct-local | 0.389 | 0.253 | 0.015 | 0.295 | | Qwen2.5-3B-Instruct-local | 0.408 | 0.127 | 0.065 | 0.280 | | Llama-3.2-3B-Instruct-local | 0.327 | 0.100 | 0.000 | 0.216 | | xLAM-7b-r-local | 0.187 | 0.013 | 0.075 | 0.123 | | Hammer2.1-3b-local | 0.118 | 0.013 | 0.015 | 0.074 |
🛠️ 4\. Configuración [[Volver arriba]](#content)
Ejecute el siguiente comando para instalar las dependencias necesarias para la inferencia y evaluación:
pip install -r requirements.txt🗂️ 5\. Datos [[Volver al inicio]](#content)
Todos los datos se almacenan en el directorio data_all, divididos en partes en inglés y chino, que se encuentran en las carpetas data_en y data_zh respectivamente. Cada carpeta contiene múltiples archivos JSON, nombrados en el formato data_{category}.json, donde category representa el tipo de datos.
data_all/
├── possible_answer_en/
│ ├── data_{normal}.json
│ ├── data_{special}.json
│ ├── data_{agent}.json
├── possible_answer_zh/
│ ├── data_{normal}.json
│ ├── data_{special}.json
│ ├── data_{agent}.json
...🧠 6\. Inferencia [[Volver arriba]](#content)
6.1 Script de Inferencia
Para ejecutar la inferencia con cmodels, use el script generate.py. Este script soporta varios modelos, categorías y lenguajes.
Uso Básico
python generate.py --model --model_path
--category --language Argumentos:
--model: Especifica el modelo a usar para la inferencia.--model_path: Especifica la ruta local al modelo (solo para modelos de código abierto).--category: Define la categoría de tareas o conjuntos de datos a evaluar. Las categorías disponibles se pueden encontrar en eval_checker/eval_checker_constant.py.--language: Especifica el idioma de la entrada/salida. Idiomas soportados: "en" (inglés), "zh" (chino)
6.2\. Ejemplos de inferencia
para modelo de código cerrado
python generate.py --model qwen-max --category test_all --language zhpython generate.py --model Qwen2.5-3B-Instruct-local --model-path /mnt/nas/ckpt/Qwen2.5-3B-Instruct --category test_all --language zh6.3\. Precauciones
- Antes de ejecutar el programa, asegúrese de que el archivo de variables de entorno .env esté correctamente configurado. Para invocar OpenAI, debe usar la red externa. Configure las variables de entorno https_proxy y http_proxy. Para usar el modelo gemini, debe usar el proxy japonés.
- El modelo a evaluar debe estar mapeado en model_inference/inference_map.py. El modelo invocado a través de OpenAI puede añadirse a la lista APIModelInference, y el modelo de inferencia personalizado puede añadirse a la lista CommonInference. El nombre de un modelo local termina con -local.
- Para agregar un modelo de evaluación personalizado, agregue la clase del modelo a model_dict refiriéndose a model_inference/model_infer.py.
- Evalúe el modelo de código abierto en Hugging Face. Se recomienda usar LLaMA-Factory para combinar los pesos LoRA y luego inferir.
📈 7. Evaluación [[Volver arriba]](#content)
Para evaluar el rendimiento de los modelos, use el script eval_main.py. Este script soporta varias métricas de evaluación y puede usarse tanto para modelos de código abierto como cerrados.
Uso básico
python eval_main.py --model --category --language 📄 Cita
Si encuentra útil nuestro artículo y recursos, por favor considere citar nuestro artículo:
@article{chen2025acebench,
title={ACEBench: Who Wins the Match Point in Tool Learning?},
author={Chen, Chen and Hao, Xinlong and Liu, Weiwen and Huang, Xu and Zeng, Xingshan and Yu, Shuai and Li, Dexun and Wang, Shuai and Gan, Weinan and Huang, Yuefeng and others},
journal={arXiv preprint arXiv:2501.12851},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-19 ---