BIRD-INTERACT 1.0 


⚠️ ประกาศ
โปรดทราบว่าก่อนกระบวนการประเมินของคุณ เมื่อ Docker ทำการโหลดฐานข้อมูล อาจเกิดข้อผิดพลาดเป็นครั้งคราวเนื่องจากสภาพแวดล้อมไม่สอดคล้องกัน (ข้อผิดพลาดเหล่านี้จะไม่หยุดกระบวนการแต่จะปรากฏใน log ของ Docker) ส่งผลให้บางฐานข้อมูลอาจโหลดไม่สำเร็จและกลายเป็นฐานข้อมูลเปล่า ซึ่งจะทำให้ผลการประเมินต่ำผิดปกติ 👉 ดังนั้น เราขอแนะนำอย่างยิ่งให้ตรวจสอบ log ของ Docker เพื่อหาข้อผิดพลาด ก่อนดำเนินการประเมิน และตรวจสอบให้แน่ใจว่าฐานข้อมูลทั้งหมดถูกโหลดสำเร็จ👉 เราได้อัปเดต แนวทางการส่งผลงาน ซึ่งขณะนี้รองรับ scaffolds ของ agent ที่ปรับแต่งเองแล้ว สามารถดูแนวทางการส่งผลงานฉบับละเอียดได้ ที่นี่
📰 ข่าวสาร
- [2026-03-29] 🔥🔥🔥 BIRD-Interact-ADK: เราได้ปล่อย BIRD-Interact-ADK ซึ่งเป็นการนำไปใช้โดยอิงกับ Google ADK ด้วยสถาปัตยกรรม 3-microservices (agent, user simulator และ DB Env) แบบโมดูลาร์ สามารถเปลี่ยน agent, ตัวจำลองผู้ใช้ หรือสภาพแวดล้อมฐานข้อมูลของคุณเองได้อย่างง่ายดาย รองรับการประมวลผลแบบขนานและผู้ให้บริการ LLM ที่ LiteLlm-compatible ทุกเจ้า แนะนำให้ใช้ implementation นี้สำหรับการวิจัยของคุณ
- [2026-02-08] 🔥🔥🔥 Bird-Interact paper ของเราได้รับการตอบรับที่ ICLR 2026 (Oral)! เจอกันที่ Rio 🇧🇷!
- [2025-11-06] 🐛 แก้ไขบั๊ก & 🐳 อัปเดต Docker: อัปเดตเวอร์ชัน sqlglot เป็น 26.16.4 เพื่อแก้ไขบั๊กที่ parser SQL ไม่สามารถแปลง SQL ได้ถูกต้องสำหรับ user simulator คุณสามารถแก้ไขได้โดยติดตั้งใหม่ด้วย
pip install sqlglot==26.16.4ใน envbird_interact_evalภาพbird_interact_evalก็ได้รับการอัปเดตแล้ว คุณจึงสามารถ pull และสร้าง containerbird_interact_evalใหม่ได้ - [2025-10-21] 🐳 อัปเดต Docker: เราได้เพิ่ม docker สำหรับ Full DB Env และได้อัปโหลด docker images 3 ภาพ (Base/Full DB Env และสภาพแวดล้อมประเมินสำหรับทั้ง
a-Interactและc-Interact) ไปยัง Docker Hub เพื่อความสะดวกในการตั้งค่าสภาพแวดล้อม ไม่ต้องดาวน์โหลด DB dumps และ build images ด้วยตนเองอีกต่อไป! - [2025-10-08] 📝 Bird-Interact paper ของเราเปิดให้อ่านสาธารณะแล้ว!
- [2025-08-26] 🚀 เรารู้สึกตื่นเต้นที่จะประกาศเปิดตัว BIRD-Interact-Full (600) set!
c-interact และ a-interact เท่านั้น 👉 สำหรับรายละเอียดเพิ่มเติม กรุณาเยี่ยมชม เว็บไซต์โครงการ
- [2025-08-26] 📬 เราจะส่ง Ground Truth & Test cases ไปยังรายชื่ออีเมลของเราในสัปดาห์นี้
- [2025-08-26] 💾 ในอีกเรื่องหนึ่ง เราได้ปล่อยเวอร์ชัน SQLite ของ LiveSQLBench-Lite เพื่อให้งานวิจัยในเครื่องทำได้ง่ายขึ้น
- [2025-08-22] แก้ไขบั๊ก: ในโค้ด Bird-Interact-Agent เราได้แก้ไขบั๊กที่เมื่อประเมิน phase-2 SQL, phase-1 SQL ที่ถูกเก็บไว้ไม่สามารถรันได้สำเร็จ ส่งผลให้ success rate ของ Phase-2 ต่ำลง บั๊กนี้ส่งผลเฉพาะ task ที่ phase1 sql มีการดำเนินการกับฐานข้อมูล เช่น CREATE table เป็นต้น
🧸 ภาพรวม
BIRD-INTERACT เป็น benchmark สำหรับ text-to-SQL แบบโต้ตอบ ออกแบบการประเมิน Text-to-SQL ใหม่ผ่านมุมมองปฏิสัมพันธ์แบบไดนามิก สภาพแวดล้อมผสานฐานความรู้เชิงลำดับชั้น, เอกสารฐานข้อมูล และตัวจำลองผู้ใช้แบบขับเคลื่อนด้วยฟังก์ชัน เพื่อจำลองสภาพแวดล้อมองค์กรที่แท้จริงสำหรับการดำเนินการ CRUD ทั้งหมด มีโหมดทดสอบเข้มข้นสองแบบ: (1) Conversational Interaction แบบ passive และ (2) Agentic Interaction แบบ active ครอบคลุม 600 task ที่มี annotation รวมถึง BI, CRUD และอื่นๆ แต่ละ task มี test case ที่สามารถรันได้ การประเมินทั่วไปมีปฏิสัมพันธ์ 1,968-5,496 turn ระหว่างโมเดลและผู้ใช้จำลอง ขณะที่โมเดล reasoning ชั้นนำในปัจจุบันแก้ไขได้เพียง ≈24% และ ≈18% ของ task เน้นความท้าทายของ benchmark นี้
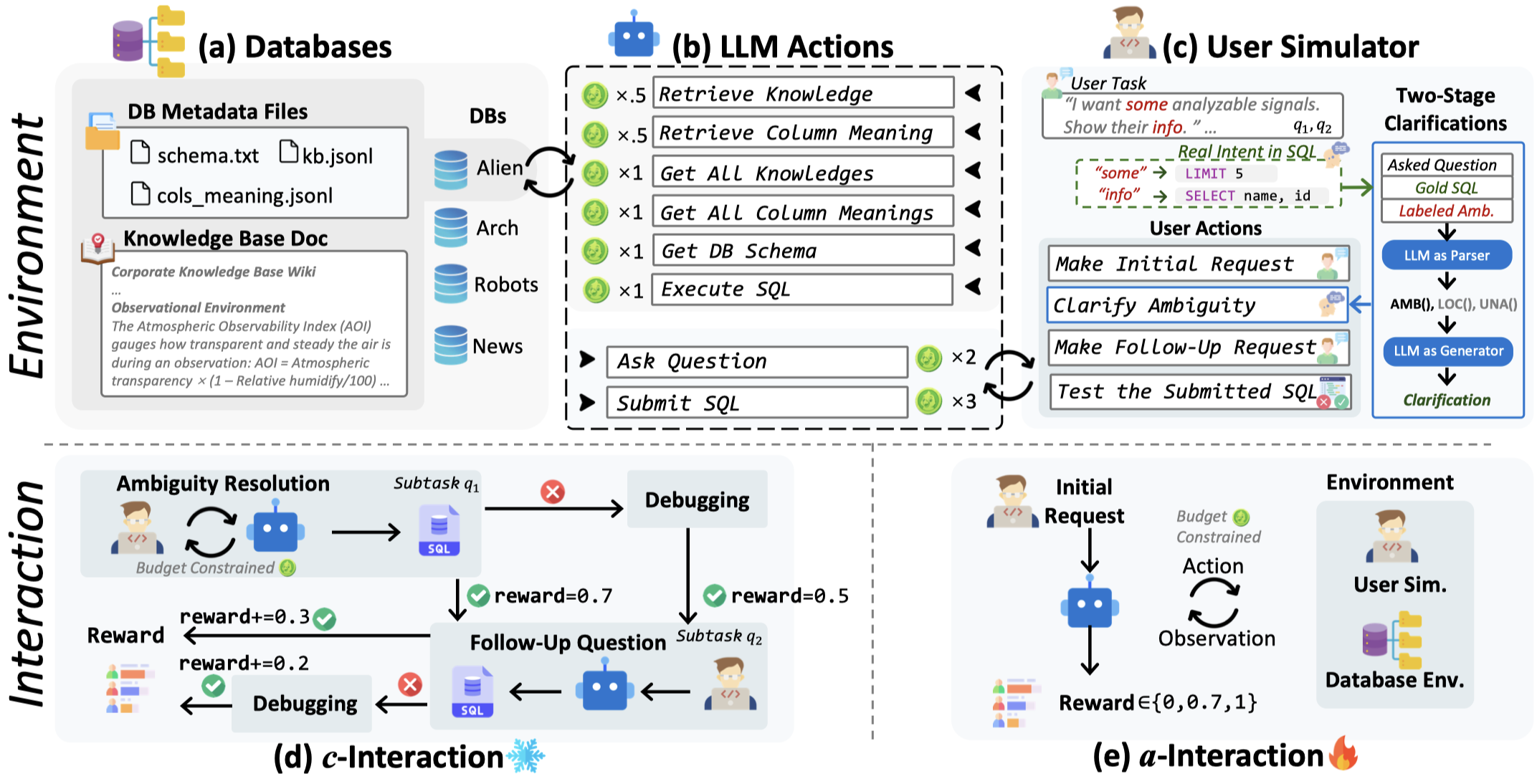
✅ สองโหมดการประเมิน
BIRD-INTERACT รองรับสองโหมดการประเมินตามที่กล่าวไว้ข้างต้น:
- c-Interact: Conversational Interaction ซึ่งเป็นโหมด passive และ workflow ถูกกำหนดตายตัว สามารถดูโค้ดและข้อมูลรายละเอียดได้ใน
bird_interact_conv - a-Interact: Agentic Interaction ซึ่งเป็นโหมด active แบบ embodied โดย workflow มีความไดนามิกและนำโดยโมเดล สามารถดูโค้ดและข้อมูลรายละเอียดได้ใน
bird_interact_agent
🐣 Lite Version
เรากำลังเปิดตัวเวอร์ชัน lite ของ BIRD-INTERACT, bird-interact-lite-exp ซึ่งประกอบด้วย 270 task คุณภาพสูงจากโลกจริงสำหรับ PostgreSQL เป็นจุดเริ่มต้นที่ดีสำหรับการทดลองอย่างรวดเร็ว
🦜 Full Version
เวอร์ชันเต็มของ BIRD-INTERACT, bird-interact-full เป็น benchmark ครบถ้วนที่มี 600 task สำหรับ PostgreSQL ครอบคลุมการดำเนินการ SQL และ query ของผู้ใช้หลากหลาย เวอร์ชันเต็มกำลังจะมาเร็วๆนี้
ผลลัพธ์ประสิทธิภาพของโมเดลบน BIRD-INTERACT-FULL
#### 1. c-Interact Text-to-SQL ประสิทธิภาพ | อันดับ | ชื่อโมเดล | รางวัลปกติ | ค่าใช้จ่ายเฉลี่ย (USD)/งาน | ระดับ | |:----:|:-------------------|:-----------------:|:-------------------:|:------------------:| | 1 | Gemini-2.5-Pro | 20.92 | $0.04 | 🏆 แชทยอดเยี่ยม | | 2 | O3-Mini | 20.27 | $0.07 | 🏆 แชทยอดเยี่ยม | | 3 | Claude-Sonnet-4 | 18.35 | $0.29 | 💎 แชทดี | | 4 | Qwen-3-Coder-480B | 17.75 | $0.11 | 💎 แชทดี | | 5 | Deepseek-Chat-V3.1 | 15.15 | $0.12 | ✨ มาตรฐาน | | 6 | Claude-Sonnet-3.7 | 13.87 | $0.29 | ✨ มาตรฐาน | | 7 | GPT-5 | 12.58 | $0.08 | ⚪ พื้นฐาน |
#### 2. a-Interact Text-to-SQL ประสิทธิภาพ | อันดับ | ชื่อโมเดล | รางวัลปกติ | ค่าใช้จ่ายเฉลี่ย (USD)/งาน | ระดับ | |:----:|:-------------------|:-----------------:|:-------------------:|:------------------------:| | 1 | GPT-5 | 25.52 | $0.24 | 🏆 ปฏิสัมพันธ์ยอดเยี่ยม | | 2 | Claude-Sonnet-4 | 23.28 | $0.51 | 🏆 ปฏิสัมพันธ์ยอดเยี่ยม | | 3 | Claude-Sonnet-3.7 | 17.45 | $0.60 | 💎 ปฏิสัมพันธ์ดี | | 4 | Gemini-2.5-Pro | 17.33 | $0.22 | 💎 ปฏิสัมพันธ์ดี | | 5 | O3-Mini | 16.43 | $0.06 | ✨ มาตรฐาน | | 6 | Deepseek-Chat-V3.1 | 13.47 | $0.06 | ✨ มาตรฐาน | | 7 | Qwen-3-Coder-480B | 10.58 | $0.07 | ⚪ พื้นฐาน |
\ พารามิเตอร์งบประมาณ: งบประมาณเริ่มต้น/งบประมาณความอดทนของผู้ใช้ วัดโดยสกุลเงินเสมือน bird-coin*s. ดูรายละเอียดเพิ่มเติมที่ bird_interact_agent/README.md
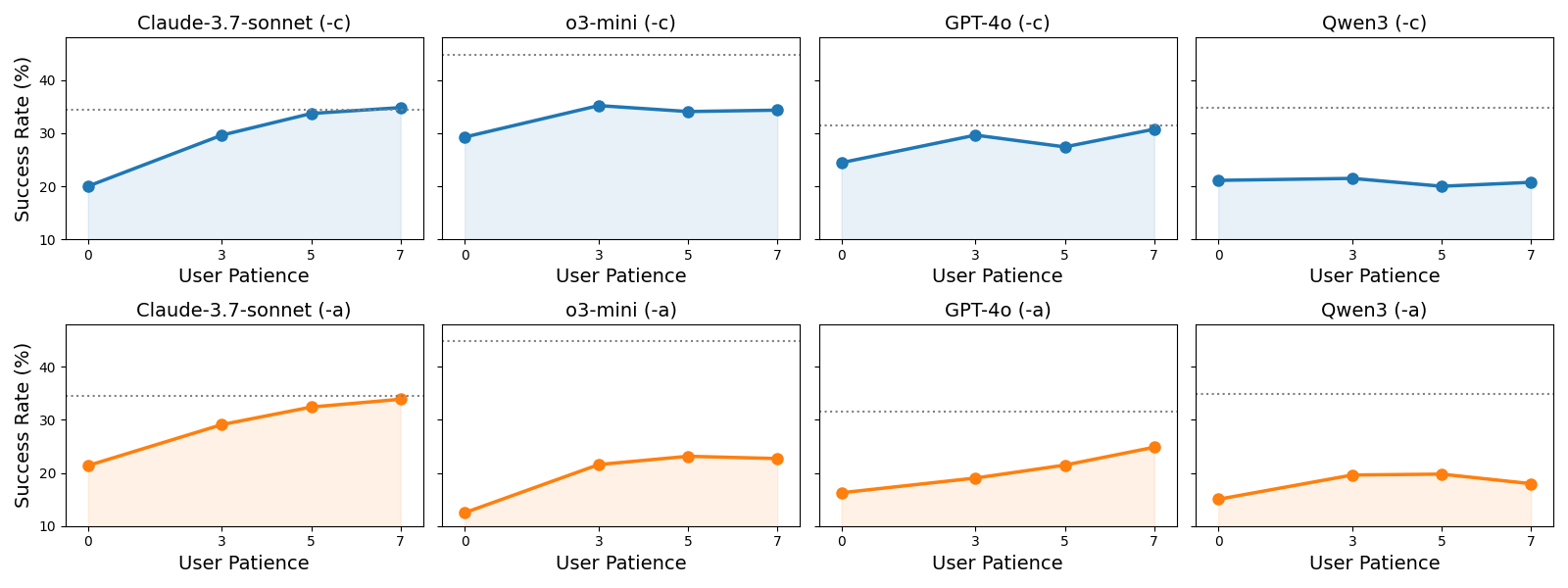
การปรับขนาดเวลาปฏิสัมพันธ์ (ITS)
การปรับขนาดเวลาปฏิสัมพันธ์ (ITS) หมายถึงความสามารถของโมเดลในการเพิ่มประสิทธิภาพปลายทางอย่างต่อเนื่องผ่านปฏิสัมพันธ์หลายรอบ เมื่อประสิทธิภาพแบบโต้ตอบนี้สูงกว่าประสิทธิภาพแบบรอบเดียวในงานที่ระบุชัดเจนและไม่กำกวม เรากล่าวว่าโมเดลนั้นเป็นไปตาม กฎ ITS เมื่อความอดทนของผู้ใช้เพิ่มขึ้นและรอบปฏิสัมพันธ์สะสม ประสิทธิภาพจะดีขึ้นต่อเนื่อง แสดงให้เห็นว่าโมเดลสามารถสื่อสารอย่างมีประสิทธิภาพในบทสนทนาที่ยาวนาน ปัจจุบันพบว่า claude-3-7-sonnet เท่านั้นที่เป็นไปตามกฎ ITS
การตั้งค่าสภาพแวดล้อม
- รัน Docker container สำหรับฐานข้อมูล bird-interact-lite, ฐานข้อมูล bird-interact-full และสภาพแวดล้อมการประเมินผล:
bird-interact-lite คุณสามารถคอมเมนต์ postgresql_full service ใน docker-compose.yml เพื่อเร่งการตั้งค่าสภาพแวดล้อม
เริ่มต้นสภาพแวดล้อมโดยการรัน:
cd env
docker compose pull
docker compose up -d
``
รอเป็นเวลาหลายนาทีเพื่อการเริ่มต้นฐานข้อมูล คุณสามารถติดตามความคืบหน้าการสร้างได้โดย:
`bash
docker compose logs -f --tail=100 bird_interact_postgresql_full # or bird_interact_postgresql for bird-interact-lite
`
หากเสร็จสิ้นแล้ว คุณควรเห็นบันทึกโดยไม่มีข้อผิดพลาด เช่น:
`bash
bird_interact_postgresql_full | 2025-10-28 17:58:30.413 HKT [1] LOG: database system is ready to accept connection
`
หากคุณเคยสร้างคอนเทนเนอร์มาก่อนและต้องการสร้างใหม่อีกครั้ง คุณสามารถรันคำสั่งต่อไปนี้:
`bash
docker compose down -v # this cmd removes the containers and the volumes
docker compose pull # pull the latest images from Docker Hub
docker compose up -d --force-recreate # build and start the containers again. --force-recreate means force the recreation of the containers.
# Or docker compose up -d --force-recreate bird_interact_eval to only recreate the bird_interact_eval container about evalution code environment.
`
คำสั่งนี้จะรัน 3 คอนเทนเนอร์โดยใช้อิมเมจที่สร้างไว้ล่วงหน้าจาก Docker Hub:
bird_interact_postgresql: ฐานข้อมูล PostgreSQL สำหรับ bird-interact-lite
bird_interact_postgresql_full: ฐานข้อมูล PostgreSQL สำหรับ bird-interact-full
bird_interact_eval: สภาพแวดล้อมสำหรับประเมินผลทั้ง a-Interact และ c-Interact ตอนนี้ คุณสามารถเริ่มสภาพแวดล้อมประเมินผลได้โดยรันคำสั่งต่อไปนี้:
bash
docker compose exec bird_interact_eval bash
`- (ไม่บังคับ) สร้างสภาพแวดล้อมด้วยตนเอง (หากต้องการสร้างอิมเมจจากศูนย์):
- ดาวน์โหลดดัมพ์ฐานข้อมูล
- bird-interact-lite แตกไฟล์และเปลี่ยนชื่อเป็น
bird-interact-full แตกไฟล์และเปลี่ยนชื่อเป็น env/postgre_table_dumps_full
สร้างสภาพแวดล้อมด้วยตนเองโดยรัน docker-compose.build.yml
`bash
cd env/
docker compose -f docker-compose.build.yml build
docker compose -f docker-compose.build.yml up -d
`- (แนะนำ) ตรวจสอบว่า container ฐานข้อมูลถูกสร้างและทำงานสำเร็จหรือไม่
- พิมพ์บันทึกการสร้าง container เพื่อตรวจสอบว่าฐานข้อมูลถูกสร้างสำเร็จโดยไม่มีข้อผิดพลาด
bash
docker logs bird_interact_postgresql > build_bird_interact_postgresql.log 2>&1
docker logs bird_interact_postgresql_full > build_bird_interact_postgresql_full.log 2>&1
`
หากเกิดข้อผิดพลาด "เกิดข้อผิดพลาดระหว่างการนำเข้า:" จะถูกพิมพ์ในไฟล์บันทึก- ตรวจสอบให้แน่ใจว่าคอนเทนเนอร์ฐานข้อมูลอยู่ในสภาพดี
ใช้สคริปต์ Python ที่เราจัดเตรียมไว้เพื่อตรวจสอบเมทาดาทาของฐานข้อมูล:
`bash
docker compose exec bird_interact_eval bash
cd /app/env
python check_db_metadata.py --host bird_interact_postgresql
python check_db_metadata.py --host bird_interact_postgresql_full
`
ผลลัพธ์ที่คาดหวัง:
- bird-interact-lite:
- 📈 ฐานข้อมูลทั้งหมด: 18
- 📋 ตารางทั้งหมด: 175
- 🔢 คอลัมน์ทั้งหมด: 2286
- 📈 จำนวนแถวเฉลี่ยต่อตาราง: 1,038.48
- 💾 ขนาดรวม: 207.15 MB (ประมาณ)
- bird-interact-full:
- 📈 ฐานข้อมูลทั้งหมด: 22
- 📋 ตารางทั้งหมด: 244
- 🔢 คอลัมน์ทั้งหมด: 2011
- 📈 จำนวนแถวเฉลี่ยต่อตาราง: 1,121.19
- 💾 ขนาดรวม: 272.00 MB (ประมาณ)
📦 รายละเอียดชุดข้อมูล
คำอธิบายชุดข้อมูล
- ฐานข้อมูล: ฐานข้อมูล PostgreSQL ฉบับเต็มสามารถดาวน์โหลดได้จาก bird-interact-lite และ bird-interact-full
- ข้อมูล: แต่ละอินสแตนซ์ข้อมูลประกอบด้วยส่วนหลักดังต่อไปนี้:
selected_database: ชื่อฐานข้อมูล
query: คำถามผู้ใช้ที่ชัดเจน
amb_user_query: คำถามผู้ใช้ที่ถูกเติมความคลุมเครือ
user_query_ambiguity: ความคลุมเครือที่ถูกเติมลงในคำถามผู้ใช้
non_critical_ambiguity: ความคลุมเครือที่ไม่สำคัญ เช่น order, limit ฯลฯ
knowledge_ambiguity: ความคลุมเครือที่เกิดจากการปกปิดข้อมูลภายนอก
sol_sql: คำตอบ SQL ที่เป็นจริง
preprocess_sql: คำสั่ง SQL ที่ต้องดำเนินการก่อนรันคำตอบหรือการทำนาย
clean_up_sql: คำสั่ง SQL ที่ต้องดำเนินการหลังจากทดสอบเพื่อคืนค่าฐานข้อมูล
test_cases: ชุดกรณีทดสอบเพื่อยืนยัน SQL ที่แก้ไขแล้ว
follow_up: คำถามติดตามผลที่มีการติดป้ายกำกับ
external_knowledge: ความรู้ภายนอกที่เกี่ยวข้องกับงานเฉพาะการประเมินผล: โค้ดประเมินผลมีอยู่ในไดเรกทอรี ./evaluation
ดูแลโดย: ทีม BIRD & Google Cloud
สัญญาอนุญาต: cc-by-sa-4.0
HuggingFace Dataset Card: bird-interact-lite
และ bird-interact-full สำหรับ PostgreSQL; และ mini-interact สำหรับ SQLite.
การใช้งานชุดข้อมูล
เพื่อหลีกเลี่ยงการรั่วไหลของข้อมูลโดยการรวบรวมอัตโนมัติ เราจะไม่รวม sql ของคำตอบ GT และกรณีทดสอบพร้อมกับข้อมูล
กรุณาอีเมลไปที่ bird.bench25@gmail.com พร้อมแท็กหัวข้อว่า
[bird-interact-lite GT&Test Cases] หรือ [bird-interact-full GT&Test Cases] สำหรับรับ ground truth และกรณีทดสอบของชุดข้อมูล bird-interact-lite หรือ bird-interact-full ซึ่งจะถูกส่งให้อัตโนมัติการรวมข้อมูลสาธารณะกับ ground truth และกรณีทดสอบ
จากนั้นใช้สคริปต์ต่อไปนี้เพื่อรวมข้อมูลสาธารณะกับ ground truth และกรณีทดสอบ:
ขอยกตัวอย่างเวอร์ชันเต็ม:
(1) รัน:
bash cp /path/to/bird_interact_data.jsonl /path/to/bird-interact-full/bird_interact_data.jsonlสิ่งนี้จะสร้างไฟล์ใหม่ที่/path/to/bird_interact_data.jsonlซึ่งมีข้อมูลที่รวมไว้แล้ว(2) จากนั้นแทนที่ข้อมูลสาธารณะเดิมด้วยข้อมูลที่รวมแล้ว:
เช่นเดียวกันกับเวอร์ชันอื่น ๆ: bird-interact-lite, เวอร์ชัน mini ฯลฯ เพียงแค่ตั้งค่า path สำหรับข้อมูลสาธารณะ, ข้อมูล ground truth และ test cases ให้ถูกต้อง แล้วจึงแทนที่ข้อมูลสาธารณะด้วยข้อมูลที่รวมกันไว้