🌐 语言
少即足够:在LLM特征空间中合成多样化数据
这是论文《少即足够:在LLM特征空间中合成多样化数据》的官方实现。
核心见解
✨ 聪明工作,而不是苦干。
在大语言模型的后训练阶段,与其盲目添加大量表面多样化文本,不如更有效地精准识别和合成那些真正缺失的关键特征。仅需少量有针对性的合成样本,我们就能显著填补特征激活覆盖率(FAC)的空白,从而在下游任务上带来明显的性能提升。
为什么这个洞见简单却强大?
传统的数据合成关注于数量和表面多样性(词汇、句式、主题分布),但这些通常只是弱代理。真正决定模型下游性能的是目标任务所需关键特征的覆盖率。
我们的工作揭示:
- 许多“看起来非常不同”的文本实际上激活了高度重叠的特征;
- FAC比标准多样性指标更好地预测下游性能,包括词级的Distinct-1/2和n-gram熵、句法级的POS-tag Distinct-2、嵌入级的Pair CosDist和语义熵。
- 对于指令遵循,FAC合成在仅需MAGPIE的1/150数据量的情况下,实现了与先前SOTA MAGPIE相当的性能。
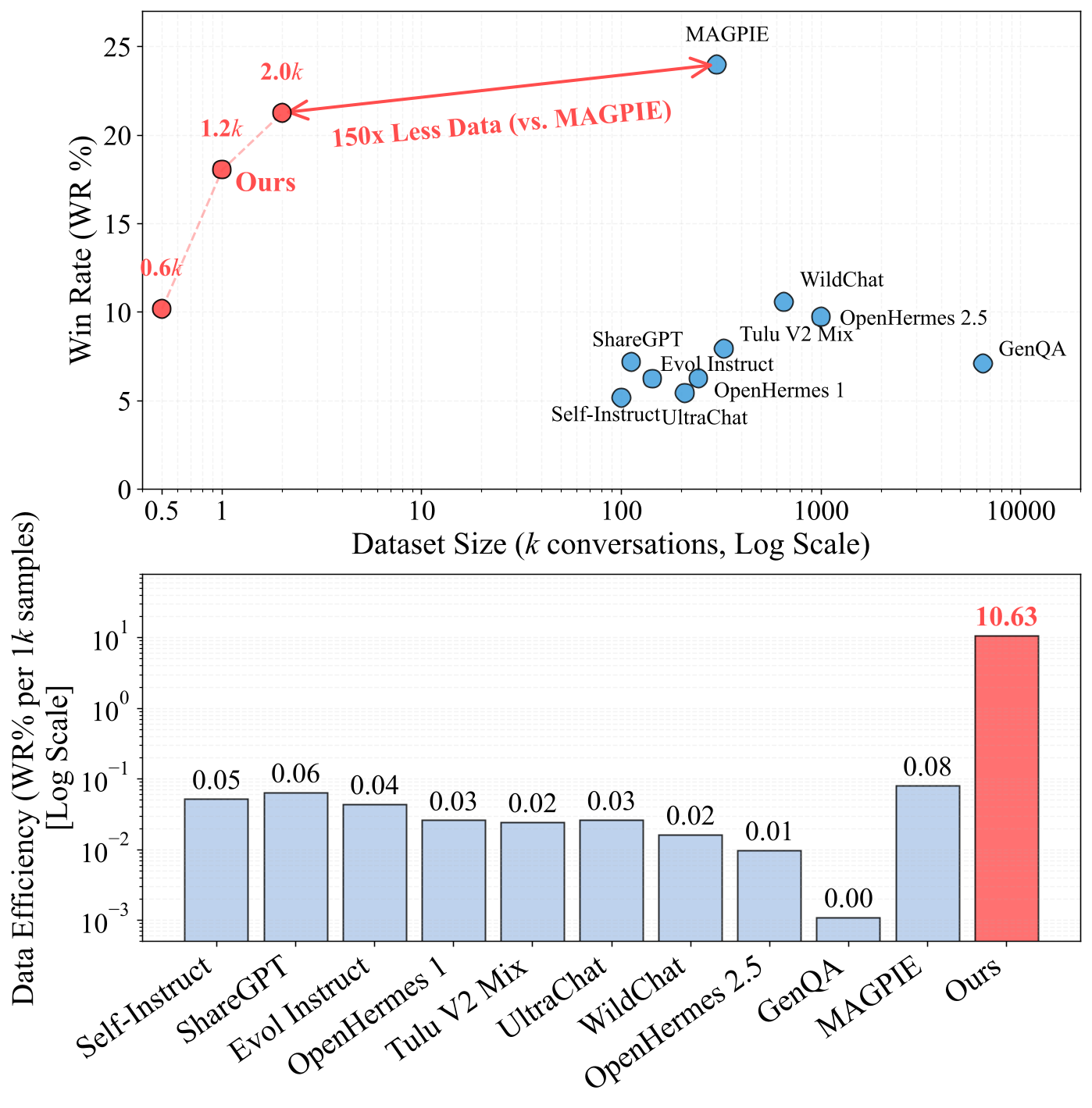
图1: 指令遵循数据集的效率前沿。我们提出的方法在仅使用2K合成样本(MAGPIE为300K)的情况下,在AlpacaEval 2.0上实现了与MAGPIE相当的胜率。
入门指南
安装
git clone https://github.com/Zhongzhi660/FAC-Synthesis.git
cd FAC-Synthesis
pip install -r requirements.txtRepository Structure
FAC-Synthesis/
├── LICENSE
├── README.md
├── requirements.txt
│
├── sae_pretrain/ # SAE pretraining
│ ├── datasets/ # pretraining corpora (constructed from public sources)
│ └── outputs/ # SAE pre-trained weights
│
├── sae_feature_analysis/ # SAE feature analysis pipeline
│ ├── interpret_features/ # feature interpretation (span collection + annotation)
│ ├── identify_task_relevant_features/ # task-relevant feature identification
│ └── identify_missing_features/ # missing-feature discovery (coverage gap)
│
├── fac_synthesis/ # FAC synthesis pipeline
│ ├── step1_contrastive_pair_construction/ # Step-1: contrastive pair construction
│ └── step2_feature_covered_sample_synthesis/ # Step-2: feature-covered synthesis
│
└── training_scripts/ # Downstream training / evaluation scripts
├── toxicity_detection/
├── reward_modeling/
├── instruction_following/
└── behavior_steering/稀疏自编码器预训练
大部分 SAE 预训练脚本位于sae_pretrain/ 目录中。我们在 Hugging Face 上提供了预训练的 SAE 检查点:
- Llama-3.1-8B-Instruct SAE: Zhongzhi1228/sae_llama_l16_h65536
- Qwen2-7B-Instruct SAE: Zhongzhi1228/sae_qwen_l14_h65536
- Mistral-7B-Instruct SAE: Zhongzhi1228/sae_mistral_l16_h65536
# Step-1: Collect hidden activations from the backbone LLM (e.g., layer 16)
python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16Step-2: Train SAEs on the target layer (e.g., layer 16)
python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16分析SAE的特征
特征分析脚本位于sae_feature_analysis/。要对激活区间进行分组并生成可读的特征解释,请运行:# Step-1: Group extracted activation spans
python groupby_textspans.py /xxx/threshold_0.0Step-2: Annotate feature explanations based on grouped spans
python annotate_explanations.py /xxx/threshold_0.0.tsvStep-3: Identify task-relevant features from the explanations
python annotate_toxicity.py /xxx/threshold_0.0_explained.tsvStep-4: Identify missing features via FAC analysis
python identify_fac.py anchor_features.tsv (complete) task_features.tsv (currently available)覆盖引导的数据合成
覆盖引导的合成脚本位于 fac_synthesis/。要生成合成查询,请运行# Step-1 (1): Contrastive Pair Construction
python generate_data_llama_r1.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8
Step-1 (2): Feature-Covered Sample Synthesis
python analyze_step1_synthetic_data.py
python merge_step1_failed_cases.pyStep-2: Feature-Covered Sample Synthesis
python generate_data_llama_r2.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8致谢
在评估阶段,我们的下游训练和测试脚本改编自以下开源仓库:
引用
如果您发现这项工作对您的研究有帮助,请引用我们的论文 🤩:
@article{li2026less,
title={Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs},
author={Li, Zhongzhi and Wu, Xuansheng and Li, Yijiang and Hu, Lijie and Liu, Ninghao},
journal={arXiv preprint arXiv:2602.10388},
year={2026}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-05-27 ---
Original README: View on GitHub