🌐 언어
Less is Enough: LLM의 특성 공간에서 다양한 데이터 합성하기
본 논문 Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs의 공식 구현입니다.
핵심 인사이트
✨ 더 똑똑하게 일하세요, 더 열심히가 아니라.
LLM의 사후 훈련 단계에서는 표면적으로 다양한 대용량 텍스트를 무작정 추가하기보다는, 정말로 누락된 핵심 특성을 정확하게 식별하고 합성하는 것이 훨씬 더 효과적입니다. 소수의 타깃 합성 샘플만으로도 Feature Activation Coverage (FAC)의 격차를 크게 메울 수 있어, 다운스트림 작업에서 명확한 성능 향상을 이끌어낼 수 있습니다.
왜 이 통찰이 단순하면서도 강력한가요?
전통적인 데이터 합성은 양과 표면적 다양성(어휘, 문장 패턴, 주제 분포)에 집중하지만, 이는 종종 약한 대리 지표에 불과합니다. 모델의 다운스트림 성능을 진정으로 결정하는 것은 목표 작업에 필요한 핵심 특성의 커버리지입니다.
우리의 연구에서 밝혀진 점:
- "겉보기에는 매우 다른" 많은 텍스트가 실제로는 매우 유사한 특성을 활성화합니다.
- FAC는 다운스트림 성능을 표준 다양성 지표들보다 훨씬 더 잘 예측합니다. 여기에는 단어 수준의 Distinct-1/2 및 n-gram Entropy, 구문 수준의 POS-tag Distinct-2, 임베딩 수준의 Pair CosDist 및 Semantic Entropy가 포함됩니다.
- 인스트럭션 팔로잉에서, FAC Synthesis는 기존 SOTA인 MAGPIE와 유사한 성능을 달성하면서도 MAGPIE보다 150배 적은 데이터만을 필요로 합니다.
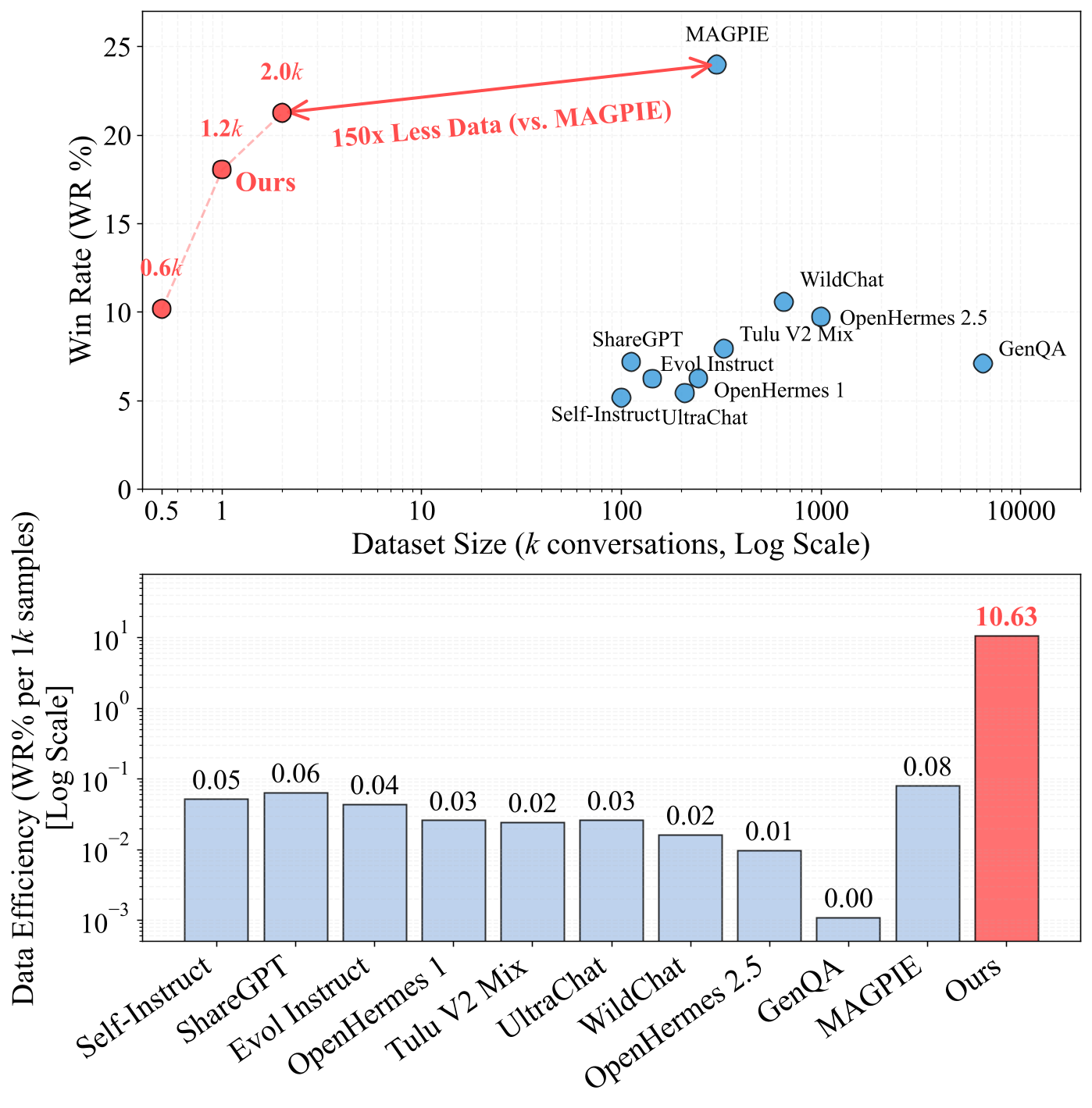
그림 1: 인스트럭션 팔로잉 데이터셋의 효율 프론티어. 제안한 방법은 2K 합성 샘플만으로(대 MAGPIE의 300K) AlpacaEval 2.0에서 MAGPIE와 유사한 Win Rate를 달성합니다.
시작하기
설치
git clone https://github.com/Zhongzhi660/FAC-Synthesis.git
cd FAC-Synthesis
pip install -r requirements.txtRepository Structure
FAC-Synthesis/
├── LICENSE
├── README.md
├── requirements.txt
│
├── sae_pretrain/ # SAE pretraining
│ ├── datasets/ # pretraining corpora (constructed from public sources)
│ └── outputs/ # SAE pre-trained weights
│
├── sae_feature_analysis/ # SAE feature analysis pipeline
│ ├── interpret_features/ # feature interpretation (span collection + annotation)
│ ├── identify_task_relevant_features/ # task-relevant feature identification
│ └── identify_missing_features/ # missing-feature discovery (coverage gap)
│
├── fac_synthesis/ # FAC synthesis pipeline
│ ├── step1_contrastive_pair_construction/ # Step-1: contrastive pair construction
│ └── step2_feature_covered_sample_synthesis/ # Step-2: feature-covered synthesis
│
└── training_scripts/ # Downstream training / evaluation scripts
├── toxicity_detection/
├── reward_modeling/
├── instruction_following/
└── behavior_steering/희소 오토인코더 사전 학습
SAE 사전 학습을 위한 대부분의 스크립트는sae_pretrain/에 위치해 있습니다. Hugging Face에서 사전 학습된 SAE 체크포인트를 제공합니다:
- Llama-3.1-8B-Instruct SAE: Zhongzhi1228/sae_llama_l16_h65536
- Qwen2-7B-Instruct SAE: Zhongzhi1228/sae_qwen_l14_h65536
- Mistral-7B-Instruct SAE: Zhongzhi1228/sae_mistral_l16_h65536
# Step-1: Collect hidden activations from the backbone LLM (e.g., layer 16)
python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16Step-2: Train SAEs on the target layer (e.g., layer 16)
python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16SAE 기능 분석
기능 분석 스크립트는sae_feature_analysis/에 위치해 있습니다. 활성화 구간을 그룹화하고 사람이 읽을 수 있는 기능 해석을 생성하려면 다음을 실행하세요:# Step-1: Group extracted activation spans
python groupby_textspans.py /xxx/threshold_0.0Step-2: Annotate feature explanations based on grouped spans
python annotate_explanations.py /xxx/threshold_0.0.tsvStep-3: Identify task-relevant features from the explanations
python annotate_toxicity.py /xxx/threshold_0.0_explained.tsvStep-4: Identify missing features via FAC analysis
python identify_fac.py anchor_features.tsv (complete) task_features.tsv (currently available)커버리지 기반 데이터 합성
커버리지 기반 합성 스크립트는 fac_synthesis/에 위치해 있습니다. 합성 쿼리를 생성하려면, 실행하세요# Step-1 (1): Contrastive Pair Construction
python generate_data_llama_r1.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8
Step-1 (2): Feature-Covered Sample Synthesis
python analyze_step1_synthetic_data.py
python merge_step1_failed_cases.pyStep-2: Feature-Covered Sample Synthesis
python generate_data_llama_r2.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8감사의 글
평가 단계에서, 우리의 다운스트림 학습 및 테스트 스크립트는 다음 오픈 소스 저장소에서 수정되었습니다:
인용
이 작업이 연구에 도움이 되었다면, 저희 논문을 인용해 주세요 🤩:
@article{li2026less,
title={Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs},
author={Li, Zhongzhi and Wu, Xuansheng and Li, Yijiang and Hu, Lijie and Liu, Ninghao},
journal={arXiv preprint arXiv:2602.10388},
year={2026}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-05-27 ---
Original README: View on GitHub