🌐 言語
Less is Enough: LLMの特徴空間における多様なデータの合成
本リポジトリは論文「Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs」の公式実装です。
コアインサイト
✨ 賢く働く、無駄に努力しない。
LLMの後処理段階では、表面的に多様なテキストを大量に追加するのではなく、本当に不足している重要な特徴を正確に特定し合成する方が効果的です。わずかな数のターゲットを絞った合成サンプルだけで、特徴活性化カバレッジ(FAC)のギャップを大幅に埋めることができ、下流タスクで明確な性能向上が得られます。
この洞察がなぜシンプルで強力なのか?
従来のデータ合成は量や表面的な多様性(語彙、文型、トピック分布)に焦点を当てていましたが、これらは多くの場合弱い代理指標にすぎません。モデルの下流性能を真に決定するのは、ターゲットタスクに必要な重要特徴のカバレッジです。
我々の研究で明らかになったこと:
- 「見た目が非常に異なる」多くのテキストは、実際には非常に重複した特徴を活性化している;
- FACは、標準的な多様性指標(単語レベルのDistinct-1/2やn-gram Entropy、構文レベルのPOS-tag Distinct-2、埋め込みレベルのPair CosDistやSemantic Entropyなど)よりも下流性能をはるかに正確に予測する。
- インストラクションフォローにおいて、FAC Synthesisは従来のSOTAであるMAGPIEと同等の性能を達成しつつ、MAGPIEの150倍少ないデータで済む。
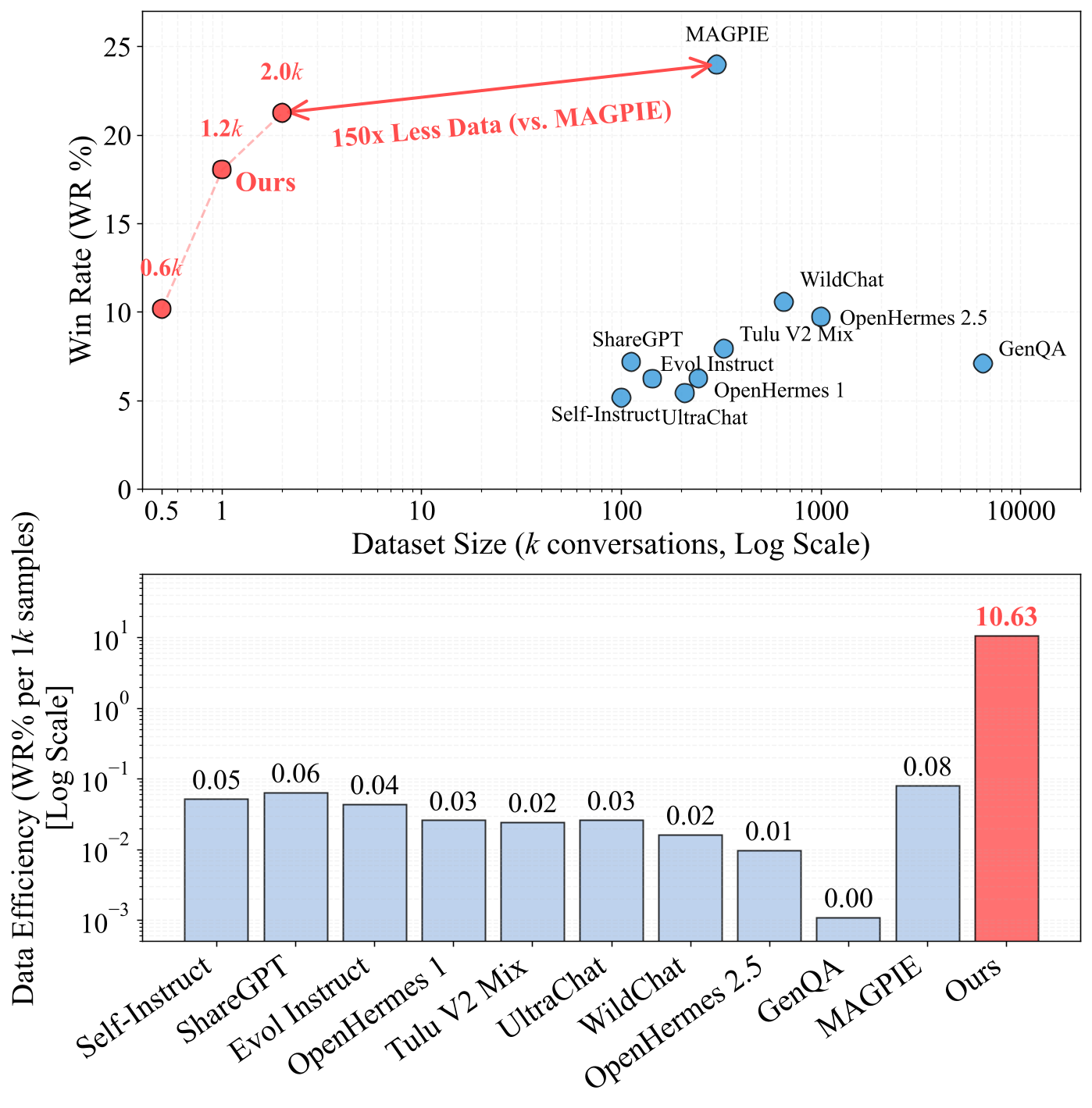
図1: インストラクションフォロー用データセットの効率フロンティア。提案手法は、AlpacaEval 2.0でMAGPIEと同等のWin Rateをわずか2K合成サンプル(MAGPIEは300K)で達成しています。
はじめに
インストール
git clone https://github.com/Zhongzhi660/FAC-Synthesis.git
cd FAC-Synthesis
pip install -r requirements.txtRepository Structure
FAC-Synthesis/
├── LICENSE
├── README.md
├── requirements.txt
│
├── sae_pretrain/ # SAE pretraining
│ ├── datasets/ # pretraining corpora (constructed from public sources)
│ └── outputs/ # SAE pre-trained weights
│
├── sae_feature_analysis/ # SAE feature analysis pipeline
│ ├── interpret_features/ # feature interpretation (span collection + annotation)
│ ├── identify_task_relevant_features/ # task-relevant feature identification
│ └── identify_missing_features/ # missing-feature discovery (coverage gap)
│
├── fac_synthesis/ # FAC synthesis pipeline
│ ├── step1_contrastive_pair_construction/ # Step-1: contrastive pair construction
│ └── step2_feature_covered_sample_synthesis/ # Step-2: feature-covered synthesis
│
└── training_scripts/ # Downstream training / evaluation scripts
├── toxicity_detection/
├── reward_modeling/
├── instruction_following/
└── behavior_steering/スパースオートエンコーダの事前学習
SAEの事前学習用スクリプトの大部分はsae_pretrain/にあります。Hugging Faceで事前学習済みのSAEチェックポイントを提供しています:
- Llama-3.1-8B-Instruct SAE: Zhongzhi1228/sae_llama_l16_h65536
- Qwen2-7B-Instruct SAE: Zhongzhi1228/sae_qwen_l14_h65536
- Mistral-7B-Instruct SAE: Zhongzhi1228/sae_mistral_l16_h65536
# Step-1: Collect hidden activations from the backbone LLM (e.g., layer 16)
python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16Step-2: Train SAEs on the target layer (e.g., layer 16)
python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16SAEの特徴分析
特徴分析スクリプトはsae_feature_analysis/ にあります。活性化スパンをグループ化し、人間が理解しやすい特徴の解釈を生成するには、次を実行してください:# Step-1: Group extracted activation spans
python groupby_textspans.py /xxx/threshold_0.0Step-2: Annotate feature explanations based on grouped spans
python annotate_explanations.py /xxx/threshold_0.0.tsvStep-3: Identify task-relevant features from the explanations
python annotate_toxicity.py /xxx/threshold_0.0_explained.tsvStep-4: Identify missing features via FAC analysis
python identify_fac.py anchor_features.tsv (complete) task_features.tsv (currently available)カバレッジ指向データ合成
カバレッジ指向合成スクリプトは fac_synthesis/ にあります。合成クエリを生成するには、次を実行してください。# Step-1 (1): Contrastive Pair Construction
python generate_data_llama_r1.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8
Step-1 (2): Feature-Covered Sample Synthesis
python analyze_step1_synthetic_data.py
python merge_step1_failed_cases.pyStep-2: Feature-Covered Sample Synthesis
python generate_data_llama_r2.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8謝辞
評価段階において、我々の下流のトレーニングおよびテストスクリプトは以下のオープンソースリポジトリから適応しています:
引用
この研究があなたの研究に役立った場合は、ぜひ私たちの論文を引用してください 🤩:
@article{li2026less,
title={Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs},
author={Li, Zhongzhi and Wu, Xuansheng and Li, Yijiang and Hu, Lijie and Liu, Ninghao},
journal={arXiv preprint arXiv:2602.10388},
year={2026}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-05-27 ---
Original README: View on GitHub