🌐 Langue
Less is Enough : Synthétiser des données diverses dans l'espace des caractéristiques des LLM
Voici la mise en œuvre officielle de l'article : Less is Enough : Synthétiser des données diverses dans l'espace des caractéristiques des LLM.
Idée principale
✨ Travaillez plus intelligemment, pas plus durement.
Dans la phase post-entraînement des LLMs, au lieu d’ajouter aveuglément de grandes quantités de textes diversifiés en surface, il est plus efficace d’identifier et de synthétiser précisément les véritables caractéristiques clés manquantes. Avec seulement un petit nombre d’échantillons synthétiques ciblés, nous pouvons combler de manière significative les lacunes dans la Couverture d’Activation des Caractéristiques (FAC), conduisant à des améliorations nettes des performances sur les tâches aval.
Pourquoi cette idée est-elle à la fois simple et puissante ?
La synthèse de données traditionnelle privilégie la quantité et la diversité de surface (vocabulaire, structures de phrases, distribution des sujets), mais ce ne sont souvent que de faibles indicateurs. Ce qui détermine réellement la performance aval du modèle est la couverture des caractéristiques clés requises par la tâche cible.
Notre travail révèle :
- De nombreux textes qui « semblent très différents » activent en réalité des caractéristiques fortement superposées ;
- FAC prédit la performance aval bien mieux que les métriques de diversité standard, incluant Distinct-1/2 et n-gram Entropy au niveau des mots, POS-tag Distinct-2 au niveau syntaxique, ainsi que Pair CosDist et Semantic Entropy au niveau des embeddings.
- Pour le suivi d’instructions, la synthèse FAC obtient des performances comparables à l’état de l’art précédent MAGPIE, tout en nécessitant 150× moins de données que MAGPIE.
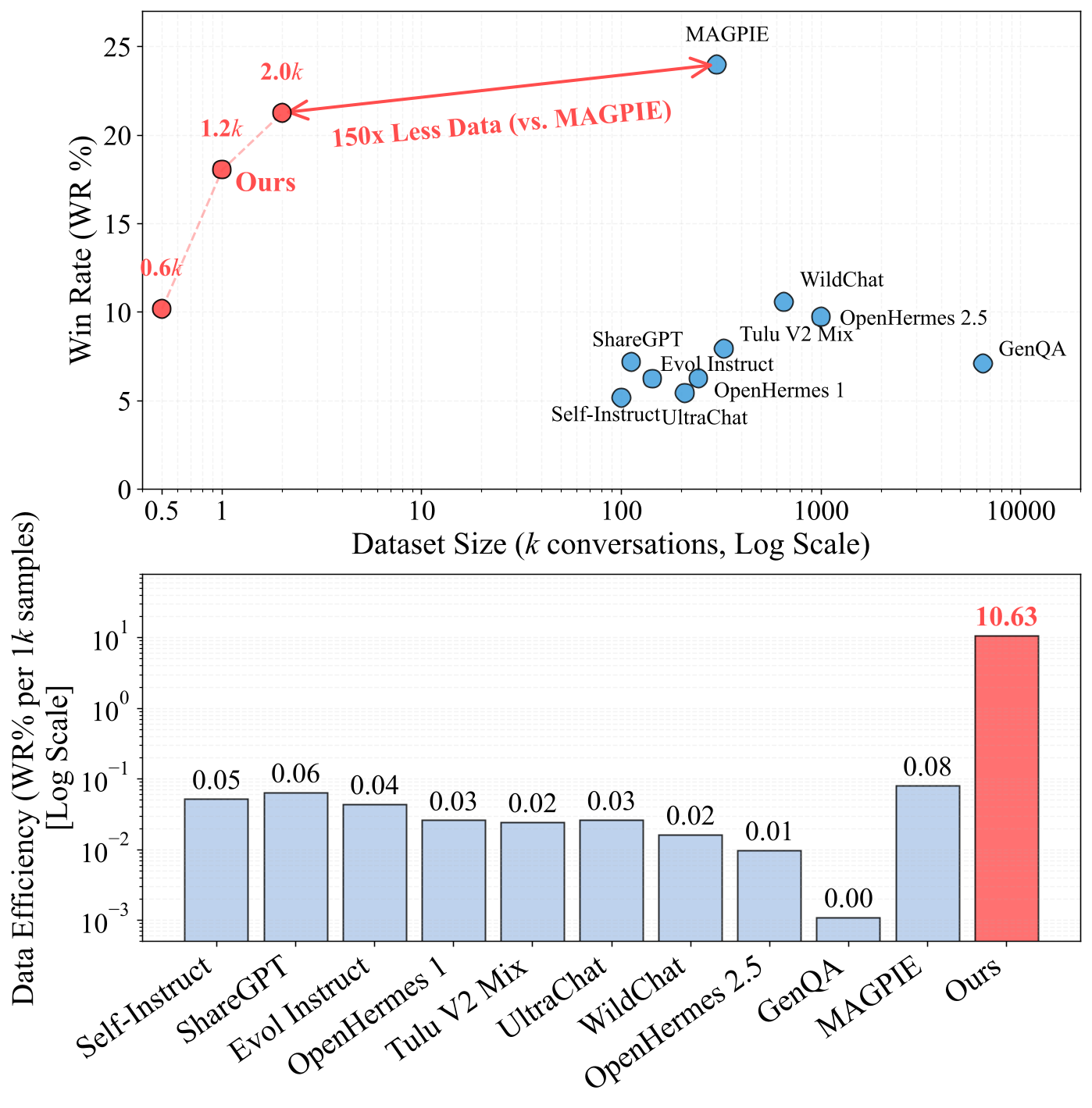
Figure 1 : La frontière d’efficacité des ensembles de données de suivi d’instructions. Notre méthode proposée atteint un taux de réussite sur AlpacaEval 2.0 comparable à MAGPIE tout en utilisant seulement 2K échantillons synthétiques (contre 300K pour MAGPIE).
Pour commencer
Installation
git clone https://github.com/Zhongzhi660/FAC-Synthesis.git
cd FAC-Synthesis
pip install -r requirements.txtRepository Structure
FAC-Synthesis/
├── LICENSE
├── README.md
├── requirements.txt
│
├── sae_pretrain/ # SAE pretraining
│ ├── datasets/ # pretraining corpora (constructed from public sources)
│ └── outputs/ # SAE pre-trained weights
│
├── sae_feature_analysis/ # SAE feature analysis pipeline
│ ├── interpret_features/ # feature interpretation (span collection + annotation)
│ ├── identify_task_relevant_features/ # task-relevant feature identification
│ └── identify_missing_features/ # missing-feature discovery (coverage gap)
│
├── fac_synthesis/ # FAC synthesis pipeline
│ ├── step1_contrastive_pair_construction/ # Step-1: contrastive pair construction
│ └── step2_feature_covered_sample_synthesis/ # Step-2: feature-covered synthesis
│
└── training_scripts/ # Downstream training / evaluation scripts
├── toxicity_detection/
├── reward_modeling/
├── instruction_following/
└── behavior_steering/Pré-entraînement des Autoencodeurs Parcimonieux
La plupart des scripts pour le pré-entraînement des SAE se trouvent danssae_pretrain/. Nous fournissons des points de contrôle SAE pré-entraînés sur Hugging Face :
- Llama-3.1-8B-Instruct SAE : Zhongzhi1228/sae_llama_l16_h65536
- Qwen2-7B-Instruct SAE : Zhongzhi1228/sae_qwen_l14_h65536
- Mistral-7B-Instruct SAE : Zhongzhi1228/sae_mistral_l16_h65536
# Step-1: Collect hidden activations from the backbone LLM (e.g., layer 16)
python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16Step-2: Train SAEs on the target layer (e.g., layer 16)
python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16Analyse des caractéristiques de SAE
Les scripts d'analyse des caractéristiques se trouvent danssae_feature_analysis/. Pour regrouper les plages d'activation et générer des interprétations des caractéristiques lisibles par l'homme, exécutez :# Step-1: Group extracted activation spans
python groupby_textspans.py /xxx/threshold_0.0Step-2: Annotate feature explanations based on grouped spans
python annotate_explanations.py /xxx/threshold_0.0.tsvStep-3: Identify task-relevant features from the explanations
python annotate_toxicity.py /xxx/threshold_0.0_explained.tsvStep-4: Identify missing features via FAC analysis
python identify_fac.py anchor_features.tsv (complete) task_features.tsv (currently available)Synthèse de données guidée par la couverture
Les scripts de synthèse guidée par la couverture se trouvent dans fac_synthesis/. Pour générer des requêtes synthétiques, exécutez# Step-1 (1): Contrastive Pair Construction
python generate_data_llama_r1.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8
Step-1 (2): Feature-Covered Sample Synthesis
python analyze_step1_synthetic_data.py
python merge_step1_failed_cases.pyStep-2: Feature-Covered Sample Synthesis
python generate_data_llama_r2.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8Remerciements
Lors de la phase d'évaluation, nos scripts d'entraînement et de test en aval sont adaptés des dépôts open-source suivants :
Citation
Si vous trouvez ce travail utile pour votre recherche, veuillez citer notre article 🤩 :
@article{li2026less,
title={Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs},
author={Li, Zhongzhi and Wu, Xuansheng and Li, Yijiang and Hu, Lijie and Liu, Ninghao},
journal={arXiv preprint arXiv:2602.10388},
year={2026}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-05-27 ---