🌐 Idioma
Menos es suficiente: Síntesis de datos diversos en el espacio de características de los LLMs
Esta es la implementación oficial del artículo: Menos es suficiente: Síntesis de datos diversos en el espacio de características de los LLMs.
Idea principal
✨ Trabaja de manera más inteligente, no más dura.
En la etapa de post-entrenamiento de los LLMs, en lugar de agregar ciegamente grandes cantidades de texto superficialmente diverso, es más efectivo identificar y sintetizar de manera precisa aquellas características clave verdaderamente ausentes. Con solo un pequeño número de muestras sintéticas dirigidas, podemos llenar significativamente los vacíos en la Cobertura de Activación de Características (FAC), lo que conduce a claras mejoras de desempeño en tareas posteriores.
¿Por qué este hallazgo es simple pero poderoso?
La síntesis de datos tradicional se enfoca en la cantidad y la diversidad superficial (vocabulario, patrones de oración, distribución de temas), pero estos suelen ser solo indicadores débiles. Lo que realmente determina el desempeño del modelo en tareas posteriores es la cobertura de las características clave requeridas por la tarea objetivo.
Nuestro trabajo revela:
- Muchos textos que "parecen muy diferentes" en realidad activan características altamente superpuestas;
- FAC predice el desempeño en tareas posteriores mucho mejor que métricas estándar de diversidad, incluyendo Distinct-1/2 y Entropía n-gram a nivel de palabra, POS-tag Distinct-2 a nivel sintáctico, y Pair CosDist y Entropía Semántica a nivel de embedding.
- Para seguimiento de instrucciones, FAC Synthesis logra un desempeño comparable al anterior SOTA MAGPIE, requiriendo 150× menos datos que MAGPIE.
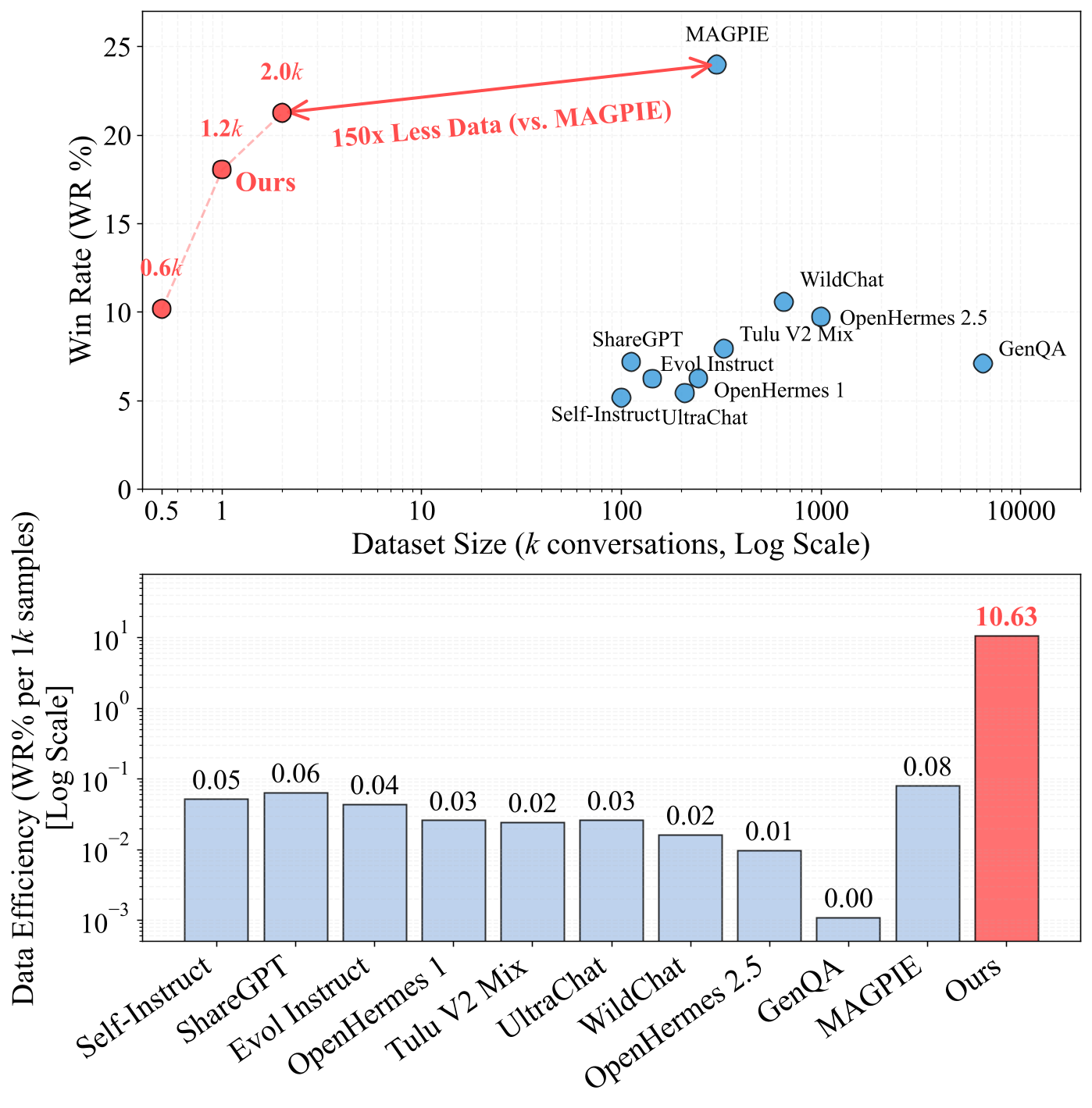
Figura 1: La Frontera de Eficiencia de los Conjuntos de Datos para Seguimiento de Instrucciones. Nuestro método propuesto logra una Tasa de Éxito en AlpacaEval 2.0 comparable a MAGPIE usando solo 2K muestras sintéticas (vs. 300K para MAGPIE).
Primeros Pasos
Instalación
git clone https://github.com/Zhongzhi660/FAC-Synthesis.git
cd FAC-Synthesis
pip install -r requirements.txtRepository Structure
FAC-Synthesis/
├── LICENSE
├── README.md
├── requirements.txt
│
├── sae_pretrain/ # SAE pretraining
│ ├── datasets/ # pretraining corpora (constructed from public sources)
│ └── outputs/ # SAE pre-trained weights
│
├── sae_feature_analysis/ # SAE feature analysis pipeline
│ ├── interpret_features/ # feature interpretation (span collection + annotation)
│ ├── identify_task_relevant_features/ # task-relevant feature identification
│ └── identify_missing_features/ # missing-feature discovery (coverage gap)
│
├── fac_synthesis/ # FAC synthesis pipeline
│ ├── step1_contrastive_pair_construction/ # Step-1: contrastive pair construction
│ └── step2_feature_covered_sample_synthesis/ # Step-2: feature-covered synthesis
│
└── training_scripts/ # Downstream training / evaluation scripts
├── toxicity_detection/
├── reward_modeling/
├── instruction_following/
└── behavior_steering/Preentrenamiento de Autoencoders Escasos
La mayoría de los scripts para el preentrenamiento de SAE se encuentran ensae_pretrain/. Proporcionamos puntos de control SAE preentrenados en Hugging Face:
- Llama-3.1-8B-Instruct SAE: Zhongzhi1228/sae_llama_l16_h65536
- Qwen2-7B-Instruct SAE: Zhongzhi1228/sae_qwen_l14_h65536
- Mistral-7B-Instruct SAE: Zhongzhi1228/sae_mistral_l16_h65536
# Step-1: Collect hidden activations from the backbone LLM (e.g., layer 16)
python create_actvs_uni.py 0 0 1 meta-llama/Llama-3.1-8B-Instruct 16Step-2: Train SAEs on the target layer (e.g., layer 16)
python train_SAEs.py 0 16 meta-llama/Llama-3.1-8B-Instruct /sae_input/prompt_actvs_l16Análisis de las características de SAE
Los scripts de análisis de características se encuentran ensae_feature_analysis/. Para agrupar intervalos de activación y generar interpretaciones de características legibles para humanos, ejecute:# Step-1: Group extracted activation spans
python groupby_textspans.py /xxx/threshold_0.0Step-2: Annotate feature explanations based on grouped spans
python annotate_explanations.py /xxx/threshold_0.0.tsvStep-3: Identify task-relevant features from the explanations
python annotate_toxicity.py /xxx/threshold_0.0_explained.tsvStep-4: Identify missing features via FAC analysis
python identify_fac.py anchor_features.tsv (complete) task_features.tsv (currently available)Síntesis de datos guiada por cobertura
Los scripts de síntesis guiada por cobertura se encuentran en fac_synthesis/. Para generar consultas sintéticas, ejecute# Step-1 (1): Contrastive Pair Construction
python generate_data_llama_r1.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8
Step-1 (2): Feature-Covered Sample Synthesis
python analyze_step1_synthetic_data.py
python merge_step1_failed_cases.pyStep-2: Feature-Covered Sample Synthesis
python generate_data_llama_r2.py \
--features xxx.tsv \
--out xxx \
--temperature 0.8Agradecimientos
En la etapa de evaluación, nuestros scripts de entrenamiento y prueba posteriores se adaptan de los siguientes repositorios de código abierto:
Citación
Si encuentra este trabajo útil para su investigación, por favor cite nuestro artículo 🤩:
@article{li2026less,
title={Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs},
author={Li, Zhongzhi and Wu, Xuansheng and Li, Yijiang and Hu, Lijie and Liu, Ninghao},
journal={arXiv preprint arXiv:2602.10388},
year={2026}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-05-27 ---