
你的个人AI操作系统
不是一个你临时打开的聊天机器人。而是一个始终在线、始终关注你的AI。 为它命名。塑造它。连接你用的一切工具。无论你如何工作,都能随时访问它。 开源,自托管,永久属于你。

看它如何工作
观看CORE处理纯文本任务、从GitHub和记忆中收集上下文、规划工作、运行Claude Code会话,并打开PR:
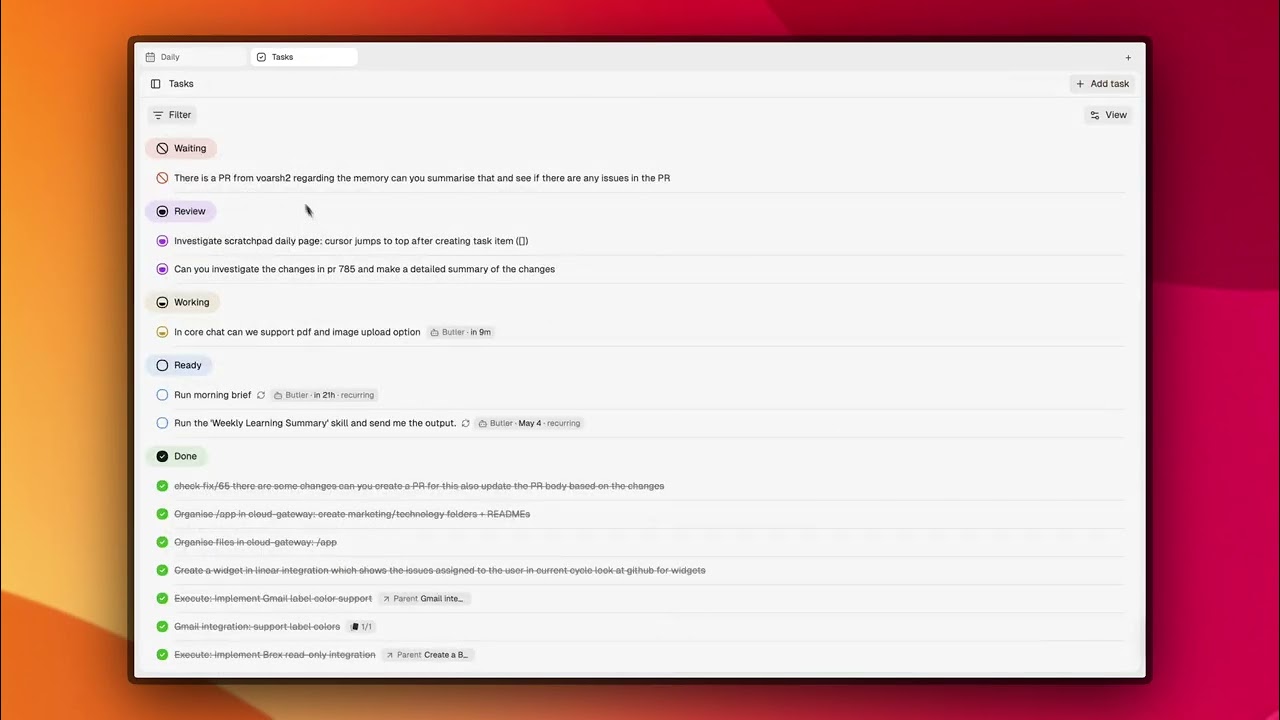
时刻监控,随时待命。
大多数AI工具都在等待请求。而CORE在观察。
将它连接到你的应用,它会监控所有应用的活动。客户的一封邮件到达,GitHub问题被分配,Sentry警报触发,会议结束。CORE会看到这些,检查你的记忆和已设置的技能,然后要么自动处理,要么呈现给你判断。你无需主动触发它。它会自动注意到。
在Claude Code、Codex或Cursor中安装CORE插件,你的代理对话也会被监控。讨论的上下文、做出的决定、编写的代码,都会反馈到记忆知识图中。CORE接下来的任务已经知道你上一轮发生了什么。
它行动时,直接行动。它能回复邮件、更新Linear问题、提交GitHub PR、发送Slack消息、运行终端命令、驱动浏览器,并可从任何界面启动Claude Code或Codex会话。从机场发送WhatsApp消息,CORE可以在你登机前就启动编码会话并打开PR。 你可以决定它自主操作的范围,以及哪些地方需要等你指令。比如,自动处理 Sentry 警报,但合并代码前总是询问你。编码会话开始前需要你批准方案。任何邮件发出前都需确认。每个任务、每个应用、每个动作的自主等级都可自定义。
四种交互方式
聊天机器人只有一种界面,操作系统有很多。
语音。 Mac 上按 Ctrl+Option,说出你要做的事。CORE 在后台运行,不打断你的工作流。
便签。 打开你的每日页面,写下 [ ] 修复第 #47 号问题中的认证 bug。CORE 会在 3 分钟内识别,自动从你的代码库和记忆中加载上下文,并草拟解决方案。
消息。 WhatsApp、Slack、Telegram。无论是在机场、手机上还是床上,都能发送任务。CORE 能获取你的全部上下文,不论消息来自哪里。
对话。 打开仪表盘,直接与之对话,就像与任何助手交流一样。当你想在委托前多聊几句时。
一个 AI,四种界面,背后始终共享同一记忆和上下文。
个性化定制
给它起个名字。选择它的说话风格。设置它在各处遵循的规则。
可选五种内置人格——TARS 的冷静高效、Alfred 的忠诚正式、Hudson 的温暖务实——或自定义你的专属人格。无论是执行任务、草拟方案,还是代你发送消息,个性都会贯穿始终。
选择语音交互时的声音。从此以后,无论在哪个界面,它都会以你配置的方式发声和行动。
CORE 实际应用
说出需求,回来就是一个 PR。
按 Ctrl+Option,说: “修复第 #312 号问题中结账流程的竞态条件。”
CORE 加载问题,提取相关提交和 Slack 讨论,拟定方案,并启动 Claude Code 会话。你回来时,已经有了 diff。全程无需坐在工位前。
晚上写下任务,早上来审查。
便签: [ ] 从今晚11点开始处理未完成的工作
CORE从Linear、GitHub和记忆中拉取内容,进行优先排序,并在你睡觉时完成处理。顺利的流程等待你审查。卡住的流程只带回来一个精准的问题,而不是停滞的标签页。
随时随地发送消息给它。
在机场用WhatsApp: “发布认证重构。”
CORE已经知道分支、上下文和你的偏好。它在Railway上运行,在你登机前启动流程。
在警报变成事故前调查问题。
Sentry在凌晨2点触发。 CORE调查,拉取相关追踪和历史事件,提出修复方案,并在Slack上通知你:“Issue #847,已提议修复,等待你审查。”你用手机批准。
获取已知你本周情况的简报。
每天早晨8点的周期性任务。 CORE从邮件、GitHub、Linear和Slack拉取内容,优先显示真正需要关注的事项,跳过无需处理的内容,并自动将后续事项转为任务。
CORE的内部结构
| | | |---|---| | 记忆 | 跨所有工具和对话的时间知识图谱。偏好、决策、目标和指令,使每个任务都以完整上下文开始。 | | 任务 | 一次性或周期性工作单元,包含你的规范、CORE的计划、实时状态和专属聊天线程。每个任务可启动编码、浏览器或终端会话。 | | 连接器 | 通过一个MCP端点连接50+应用,还支持Webhook触发主动自动化。GitHub、Linear、Jira、Slack、Gmail、Calendar、Sentry、Notion、Todoist等。 | | 技能 | 可复用的指令,根据上下文自动触发。例如:“规划修复前总是拉取相关Linear问题”,“PR前运行测试”,“任务完成后在Slack发布总结”。内置100+,也可自定义。 | | 网关 | 在你的设备或Docker和Railway上运行Claude Code、Codex、浏览器代理和终端命令,确保CORE在你关闭笔记本时也能持续工作。 | | 模型无关 | 可自选服务商:Anthropic、OpenAI或开源模型。可完全自托管,实现完全隔离。 |
CORE对比分析
| | CORE | OpenClaw | Hermes Agent | Devin / Copilot | |---|:---:|:---:|:---:|:---:| | 多种界面(语音、便签、聊天、消息) | ✅ | 部分 | ❌ | ❌ | | 跨任务的持久记忆 | ✅ | ❌ | ✅ | ❌ | | 委托给编码代理(Claude Code,Codex) | ✅ | ❌ | ❌ | ✅ | | 结构化任务规划并需人工批准 | ✅ | ❌ | ❌ | 部分 | | 自定义名称、个性和语音 | ✅ | ❌ | ❌ | ❌ | | 50+ 应用连接器 | ✅ | 部分 | 部分 | ❌ | | 通过网关访问终端和浏览器 | ✅ | ✅ | ✅ | ✅ | | 默认人工参与 | ✅ | ❌ | ❌ | ❌ | | 开源且可自托管 | ✅ | ✅ | ✅ | ❌ |
快速开始
开源并可自托管。您的数据保留在您的基础设施中。
选择您的路径:
| 我想要... | 操作方式 | |---|---| | 在我的电脑上试用 | 运行以下一键安装命令(需要 Docker) | | 部署到服务器或 VPS | 一键 Railway 部署 | | 使用 Mac 应用 | 加入候补名单 |
安装并启动 CORE:
npm install -g @redplanethq/corebrain && corebrain setup设置向导会要求输入安装目录、AI 提供商、API 密钥和聊天模型。它会生成密钥,启动服务,并打开 http://localhost:3033。
大多数本地安装在 Docker 运行后只需几分钟。
或者在 Railway 上部署:

连接网关,以便 CORE 可以运行编码代理、驱动你的浏览器并访问本地文件夹:
corebrain login
corebrain gateway setup你的第一个任务(设置后2分钟内完成):
- 打开 草稿本(你的每日页面,地址为
http://localhost:3033) - 输入
[ ] 总结我未完成的 GitHub 问题或者你平时会自己完成的任何任务 - CORE 会在3分钟内自动获取任务,收集已连接应用的上下文,并草拟执行方案
- 审核方案后,CORE 会自动执行并返回结果
文档
- 记忆 - 时序知识图谱,事实分类,意图驱动检索
- 草稿本 - 任务与创意的每日起点
- 任务 - 计划、状态、重复性工作和任务范围上下文
- 工具包 - 通过 MCP 跨 50+ 应用的 1000+ 操作
- CORE 代理 - 触发器、记忆、工具与执行
- 网关 - 支持 WhatsApp、Slack、Telegram、邮件、网页和 API 访问
- 技能 - 可复用的指令,用于可重复的工作流
- 自托管 - 全面部署指南
- 更新日志 - 已发布内容
基准测试
CORE 在 LoCoMo 基准测试 上,横跨单跳、多跳、开放领域和时序推理,平均准确率达到 88.24%。完整结果与基线对比见基准测试仓库。
安全性
- CASA 二级认证
- 传输过程使用 TLS 1.3
- AES-256 静态加密
- 您的数据绝不会被用于模型训练
- 支持自托管,实现完全隔离
- 安全策略
- 漏洞报告: harshith@poozle.dev
社区
我们正在公开构建 CORE。
我们公开分享路线图和架构决策,因为构建个人操作系统中最难的问题,最适合与实际用户一起解决。请为仓库加星,自行托管,分享你的成果,并对缺失或有问题的部分提交 issue。
- Discord - 提问、讨论、展示
- 贡献文档 - 如何为 CORE 做贡献
good-first-issue- 新手建议从这里开始
自托管你的个人 AI 操作系统。
为本仓库加星 · 阅读文档 · 加入 Discord
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-07 ---