
Hệ điều hành AI cá nhân của bạn
Không phải là chatbot mà bạn mở ra. Là một AI luôn hoạt động, luôn quan sát. Đặt tên cho nó. Định hình nó. Kết nối nó với mọi thứ bạn sử dụng. Tiếp cận nó theo bất kỳ cách nào bạn làm việc. Mã nguồn mở, tự lưu trữ, thuộc về bạn mãi mãi.

Xem CORE hoạt động
Xem CORE nhận một nhiệm vụ văn bản thuần, thu thập ngữ cảnh từ GitHub và bộ nhớ, lên kế hoạch làm việc, chạy một phiên Claude Code, và mở một PR:
Luôn quan sát. Luôn sẵn sàng.
Hầu hết các công cụ AI đều chờ được yêu cầu. CORE thì quan sát.
Kết nối CORE với các ứng dụng của bạn và nó sẽ giám sát hoạt động trên tất cả chúng. Một email đến từ khách hàng, một vấn đề GitHub được giao, một cảnh báo Sentry phát ra, một cuộc họp kết thúc. CORE nhìn thấy, kiểm tra bộ nhớ và các kỹ năng bạn đã thiết lập, rồi tự xử lý hoặc chuyển cho bạn phán xét. Bạn không kích hoạt nó. Nó tự nhận biết.
Cài đặt plugin CORE trong Claude Code, Codex, hoặc Cursor và các cuộc trò chuyện với agent cũng được giám sát. Ngữ cảnh được thảo luận, quyết định được đưa ra, mã được viết, tất cả đều bổ sung vào đồ thị tri thức bộ nhớ. Nhiệm vụ tiếp theo CORE nhận đã biết những gì xảy ra trong phiên trước của bạn.
Khi hành động, nó hành động trực tiếp. Nó có thể trả lời email, cập nhật các vấn đề Linear, tạo PR trên GitHub, gửi tin nhắn Slack, chạy lệnh terminal, điều khiển trình duyệt, và khởi tạo một phiên Claude Code hoặc Codex từ bất kỳ giao diện nào. Gửi một tin nhắn WhatsApp từ sân bay và CORE có thể khởi chạy phiên coding và mở PR trước khi bạn lên máy bay. Bạn quyết định khi nào nó tự động thực hiện và khi nào nó chờ lệnh của bạn. Xử lý cảnh báo Sentry tự động nhưng luôn hỏi trước khi hợp nhất. Phê duyệt kế hoạch trước khi bắt đầu phiên lập trình. Yêu cầu xác nhận trước khi gửi bất kỳ email nào. Mức độ tự động hóa là do bạn thiết lập, theo từng tác vụ, từng ứng dụng, từng hành động.
Bốn cách để truy cập
Một chatbot chỉ có một giao diện. Một hệ điều hành thì có nhiều.
Giọng nói. Nhấn Ctrl+Option trên Mac và nói điều cần làm. CORE thực hiện trong nền mà không làm gián đoạn công việc của bạn.
Scratchpad. Mở trang làm việc hàng ngày và viết [ ] Sửa lỗi xác thực từ issue #47. CORE sẽ nhận diện trong vòng 3 phút, tải ngữ cảnh từ kho mã và trí nhớ, rồi soạn thảo kế hoạch.
Nhắn tin. WhatsApp, Slack, Telegram. Gửi tác vụ từ sân bay, từ điện thoại, từ trên giường. CORE luôn có đầy đủ ngữ cảnh của bạn bất kể tin nhắn xuất phát từ đâu.
Trò chuyện. Mở bảng điều khiển và trò chuyện trực tiếp như với một trợ lý. Khi bạn muốn đối thoại qua lại trước khi giao việc.
Một AI, bốn giao diện, cùng một bộ nhớ và ngữ cảnh đứng sau tất cả.
Cá nhân hóa theo ý bạn
Đặt tên cho nó. Chọn cách nó giao tiếp. Thiết lập các quy tắc mà nó tuân theo ở mọi nơi.
Chọn một trong năm cá tính tích hợp sẵn — sự hiệu quả khô khan của TARS, sự trang trọng trung thành của Alfred, hay sự thực tế ấm áp của Hudson — hoặc tự viết cá tính riêng. Cá tính ấy thể hiện trong mọi tác vụ nó thực hiện, mọi kế hoạch nó soạn, mọi tin nhắn gửi thay bạn.
Chọn giọng nói cho các tương tác bằng âm thanh. Từ đó, nó sẽ phát âm và hành xử như AI bạn đã cấu hình, trên mọi giao diện.
CORE trong thực tế
Nói rồi quay lại với PR.
Nhấn Ctrl+Option, nói: "Sửa điều kiện tranh chấp trong luồng thanh toán từ issue #312."
CORE tải issue, lấy các commit liên quan và các chuỗi Slack, soạn thảo kế hoạch, và chạy một phiên Claude Code. Bạn quay lại đã thấy bản diff. Bạn chưa từng phải ngồi vào bàn làm việc.
Viết vào ban đêm, xem lại vào buổi sáng.
Bảng ghi chú: [ ] Xử lý tồn đọng tối nay bắt đầu lúc 11 giờ đêm
CORE lấy dữ liệu từ Linear, GitHub và trí nhớ, ưu tiên và xử lý khi bạn ngủ. Các phiên chạy suôn sẻ đang chờ bạn đánh giá. Các phiên bị kẹt sẽ quay lại với một câu hỏi ngắn gọn, không phải là một tab bị treo.
Gửi tin nhắn từ bất cứ đâu.
WhatsApp từ sân bay: "Triển khai refactor xác thực."
CORE đã biết nhánh, ngữ cảnh và sở thích của bạn. Nó đang chạy trên Railway. Nó khởi động phiên trước khi bạn lên máy bay.
Điều tra cảnh báo trước khi thành sự cố.
Sentry báo lúc 2 giờ sáng. CORE điều tra, lấy các trace liên quan và các sự cố trước đó từ trí nhớ, đề xuất giải pháp và ping bạn trên Slack: "Issue #847, đã đề xuất sửa, chờ bạn duyệt." Bạn duyệt từ điện thoại.
Nhận báo cáo đã biết tuần của bạn.
Nhiệm vụ định kỳ, mỗi sáng lúc 8 giờ. CORE lấy từ email, GitHub, Linear và Slack, chỉ hiển thị những gì thật sự cần chú ý, bỏ qua phần không cần, và tự động biến follow-up thành nhiệm vụ.
Những gì có bên trong CORE
| | | |---|---| | Trí nhớ | Đồ thị kiến thức theo thời gian trên mọi công cụ và cuộc trò chuyện. Sở thích, quyết định, mục tiêu và chỉ thị, để mỗi nhiệm vụ bắt đầu với ngữ cảnh đã sẵn sàng. | | Nhiệm vụ | Đơn vị công việc một lần hoặc định kỳ với đặc tả của bạn, kế hoạch của CORE, trạng thái trực tiếp và luồng chat riêng. Mỗi nhiệm vụ có thể khởi tạo phiên code, trình duyệt hoặc terminal. | | Kết nối | Hơn 50 ứng dụng qua một điểm MCP, cùng trigger webhook cho tự động hóa chủ động. GitHub, Linear, Jira, Slack, Gmail, Calendar, Sentry, Notion, Todoist và nhiều hơn nữa. | | Kỹ năng | Hướng dẫn tái sử dụng tự động kích hoạt theo ngữ cảnh. Ví dụ: "luôn lấy các issue liên quan từ Linear trước khi lên kế hoạch sửa," "chạy test trước khi mở PR," hoặc "đăng tóm tắt lên Slack khi nhiệm vụ hoàn thành." Hơn 100 kỹ năng có sẵn, hoặc tự viết thêm. | | Gateway | Chạy Claude Code, Codex, agent trình duyệt và lệnh terminal trên máy bạn hoặc trong Docker và Railway, để CORE vẫn hoạt động khi laptop của bạn đóng. | | Không phụ thuộc mô hình | Dùng nhà cung cấp bạn chọn: Anthropic, OpenAI hoặc mô hình open-weight. Tự host toàn bộ stack để cách ly hoàn toàn. |
So sánh CORE
| | CORE | OpenClaw | Hermes Agent | Devin / Copilot | |---|:---:|:---:|:---:|:---:| | Nhiều giao diện (giọng nói, bảng ghi chú, chat, nhắn tin) | ✅ | Một phần | ❌ | ❌ | | Trí nhớ liên tục qua các nhiệm vụ | ✅ | ❌ | ✅ | ❌ | | Ủy quyền cho các agent lập trình (Claude Code, Codex) | ✅ | ❌ | ❌ | ✅ | | Lập kế hoạch nhiệm vụ có cấu trúc với sự phê duyệt của con người | ✅ | ❌ | ❌ | Một phần | | Tùy chỉnh tên, cá tính và giọng nói | ✅ | ❌ | ❌ | ❌ | | Kết nối với hơn 50 ứng dụng | ✅ | Một phần | Một phần | ❌ | | Truy cập terminal và trình duyệt qua gateway | ✅ | ✅ | ✅ | ✅ | | Con người kiểm soát theo mặc định | ✅ | ❌ | ❌ | ❌ | | Mã nguồn mở và có thể tự triển khai | ✅ | ✅ | ✅ | ❌ |
Bắt đầu nhanh
Mã nguồn mở và tự triển khai. Dữ liệu của bạn luôn nằm trong hạ tầng của bạn.
Chọn hướng đi của bạn:
| Tôi muốn... | Làm thế nào | |---|---| | Thử trên máy của tôi | Chạy lệnh cài đặt một bước dưới đây (cần Docker) | | Triển khai trên máy chủ hoặc VPS | Triển khai Railway một bước | | Sử dụng ứng dụng Mac | Tham gia danh sách chờ |
Cài đặt và khởi động CORE:
npm install -g @redplanethq/corebrain && corebrain setupTrình hướng dẫn thiết lập yêu cầu thư mục cài đặt, nhà cung cấp AI, khóa API và mô hình chat. Nó tạo ra các bí mật, khởi động ngăn xếp và mở http://localhost:3033.
Hầu hết các cài đặt cục bộ mất vài phút khi Docker đang chạy.
Hoặc triển khai trên Railway:

Kết nối một gateway để CORE có thể chạy các agent lập trình, điều khiển trình duyệt của bạn, và truy cập các thư mục cục bộ:
corebrain login
corebrain gateway setupYêu cầu: Docker 20.10+, Docker Compose 2.20+, 4 vCPU / 8GB RAM
Hướng dẫn tự triển khai đầy đủ
Nhiệm vụ đầu tiên của bạn (2 phút sau khi thiết lập):
- Mở Scratchpad (trang hàng ngày của bạn tại
http://localhost:3033) - Gõ
[ ] Tóm tắt các issue GitHub đang mở của tôihoặc bất kỳ nhiệm vụ nào bạn thường tự làm - CORE sẽ tiếp nhận trong vòng 3 phút, thu thập ngữ cảnh từ các ứng dụng đã kết nối và phác thảo một kế hoạch
- Phê duyệt kế hoạch và CORE sẽ thực thi và trả lại kết quả
Tài liệu
- Memory - Đồ thị tri thức tạm thời, phân loại sự kiện, truy xuất theo ý định
- Scratchpad - Bề mặt hàng ngày nơi nhiệm vụ và ý tưởng bắt đầu
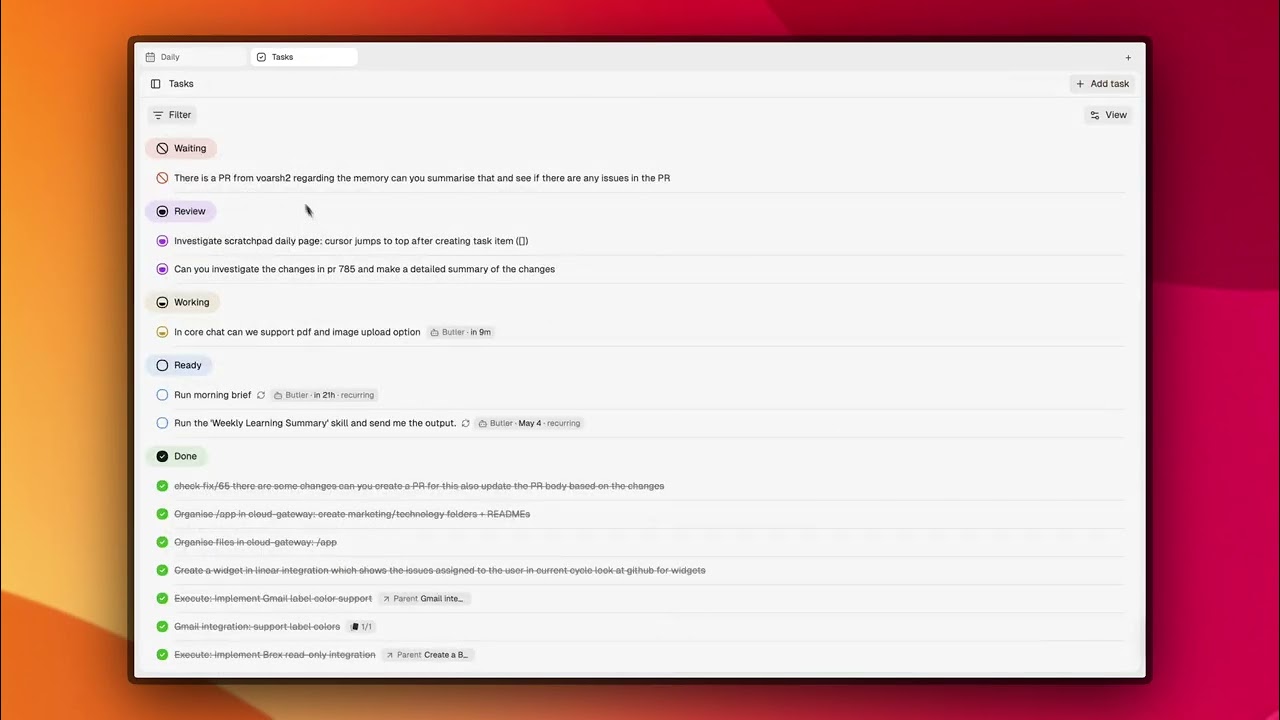
- Tasks - Kế hoạch, trạng thái, công việc định kỳ và ngữ cảnh theo nhiệm vụ
- Toolkit - Hơn 1000 hành động trên 50+ ứng dụng qua MCP
- CORE Agent - Kích hoạt, bộ nhớ, công cụ và thực thi
- Gateway - Truy cập WhatsApp, Slack, Telegram, email, web và API
- Skills - Hướng dẫn tái sử dụng cho các quy trình lặp lại
- Self-hosting - Hướng dẫn triển khai đầy đủ
- Changelog - Những gì đã phát hành
Benchmark
CORE đạt 88.24% độ chính xác trung bình trên chuẩn LoCoMo với các tác vụ suy luận đơn, đa bước, mở rộng miền và suy luận theo thời gian. Xem repo benchmark để biết kết quả đầy đủ và so sánh chuẩn.
Bảo mật
- Được chứng nhận CASA Tier 2
- TLS 1.3 khi truyền tải
- AES-256 khi lưu trữ
- Dữ liệu của bạn không bao giờ được sử dụng để huấn luyện mô hình
- Tự triển khai để cách ly hoàn toàn
- Chính sách bảo mật
- Lỗ hổng bảo mật: harshith@poozle.dev
Cộng đồng
Chúng tôi xây dựng CORE công khai.
Chúng tôi chia sẻ lộ trình và các quyết định kiến trúc một cách cởi mở vì những vấn đề khó nhất khi xây dựng hệ điều hành cá nhân được giải quyết tốt nhất cùng với những người sử dụng nó. Hãy đánh dấu repo, tự triển khai, chia sẻ những gì bạn xây dựng và mở issue cho những gì bị lỗi hoặc thiếu.
- Discord - câu hỏi, ý tưởng, trình diễn
- Tài liệu đóng góp - cách đóng góp cho CORE
good-first-issue- bắt đầu tại đây
Tự triển khai hệ điều hành AI cá nhân của bạn.
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-07 ---