
Ваш персональный ИИ-ОС
Это не просто чат-бот, который вы запускаете. Это ИИ, который всегда включен, всегда наблюдает. Дайте ему имя. Настройте его. Подключите ко всему, что вы используете. Общайтесь с ним так, как работаете вы. Открытый исходный код, самохостинг, навсегда ваш.

Смотрите, как это работает
Посмотрите, как CORE берет текстовую задачу, собирает контекст из GitHub и памяти, планирует работу, запускает сессию Claude Code и открывает PR:
Всегда наблюдает. Всегда готов.
Большинство ИИ-инструментов ждут команды. CORE наблюдает.
Подключите его к своим приложениям, и он будет следить за активностью во всех них. Приходит письмо от клиента, назначается задача на GitHub, появляется алерт Sentry, заканчивается встреча. CORE видит это, сверяется с вашей памятью и заданными навыками и либо решает сам, либо выносит на ваш суд. Вы не инициируете его. Он замечает сам.
Установите плагин CORE в Claude Code, Codex или Cursor, и ваши агентские диалоги тоже будут отслеживаться. Обсуждаемый контекст, принятые решения, написанный код — всё это попадает в граф знаний памяти. Следующая задача, которую возьмет CORE, уже знает, что произошло в прошлой сессии.
Когда он действует, то делает это напрямую. Может отвечать на письма, обновлять задачи Linear, создавать PR в GitHub, отправлять сообщения в Slack, выполнять команды терминала, управлять браузером и запускать сессию Claude Code или Codex с любого интерфейса. Отправьте сообщение WhatsApp из аэропорта — CORE сможет запустить кодинг-сессию и открыть PR до вашего посадки. Вы решаете, где оно действует самостоятельно, а где ждет вашего вызова. Обрабатывайте оповещения Sentry автоматически, но всегда спрашивайте перед слиянием. Одобряйте план перед началом кодовой сессии. Требуйте подтверждения перед отправкой любого письма. Уровень автономии вы настраиваете сами — для каждой задачи, каждого приложения, каждого действия.
Четыре способа взаимодействия
У чат-бота один интерфейс. У ОС — много.
Голос. Нажмите Ctrl+Option на Mac и скажите, что нужно сделать. CORE выполнит это в фоновом режиме, не прерывая ваш поток работы.
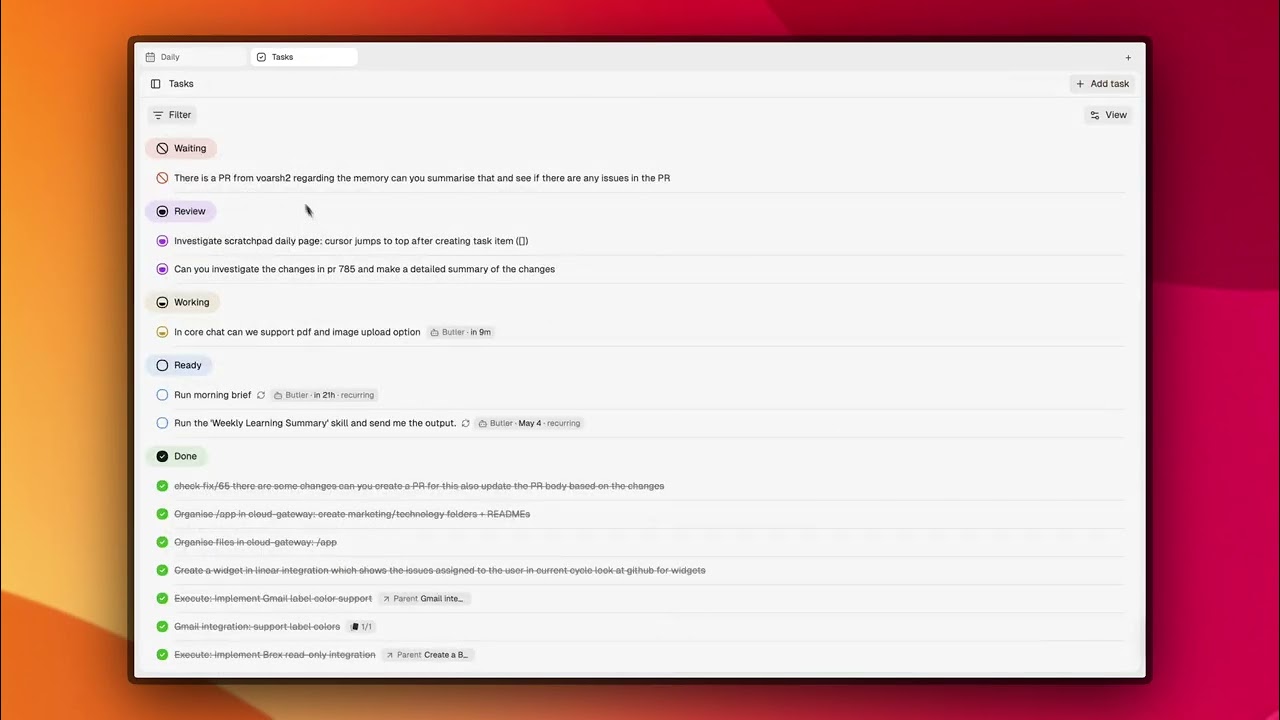
Черновик. Откройте вашу ежедневную страницу и напишите: [ ] Исправить ошибку авторизации из issue #47. CORE заметит задачу в течение 3 минут, загрузит контекст из репозитория и памяти, и составит план.
Мессенджеры. WhatsApp, Slack, Telegram. Отправьте задачу из аэропорта, с телефона, из постели. CORE всегда в курсе вашего контекста, независимо от источника сообщения.
Чат. Откройте дашборд и общайтесь напрямую, как с любым ассистентом. Когда нужно обсудить детали перед делегированием.
Один ИИ, четыре точки доступа, единая память и контекст на всех.
Сделайте его своим
Дайте ему имя. Выберите стиль общения. Задайте правила, которых он придерживается всегда.
Выберите одну из пяти встроенных личностей — сухая эффективность TARS, преданная формальность Альфреда, теплая практичность Хадсона — или напишите свою. Личность проявляется в каждой задаче, каждом плане, каждом сообщении от вашего имени.
Настройте голос для устных взаимодействий. С этого момента ИИ будет звучать и вести себя так, как вы выбрали — во всех интерфейсах.
CORE в действии
Скажите — и возвращайтесь к PR.
Нажмите Ctrl+Option, скажите: «Исправь гонку в процессе оформления заказа из issue #312.»
CORE загрузит задачу, найдет связанные коммиты и ветки Slack, составит план и запустит сессию Claude Code. Вы вернетесь к диффу. За столом вас не было.
Напишите ночью, проверьте утром.
Черновик: [ ] Разобрать накопившиеся задачи за ночь, начиная с 23:00
CORE собирает данные из Linear, GitHub и памяти, расставляет приоритеты и выполняет задачи, пока вы спите. Готовые решения ждут вашего одобрения. Зависшие сессии возвращаются с одним чётким вопросом, а не зависшим окном.
Сообщайте ему откуда угодно.
WhatsApp из аэропорта: "Задеплой рефакторинг авторизации."
CORE уже знает ветку, контекст и ваши предпочтения. Он работает на Railway. Сессия запускается до вашего выхода на посадку.
Проверяйте алерты до того, как они станут инцидентами.
Sentry сработал в 2 ночи. CORE исследует, подтягивает связанные трассы и прошлые инциденты из памяти, предлагает исправление и пишет вам в Slack: "Issue #847, предложено исправление, ждёт вашего одобрения." Вы подтверждаете с телефона.
Получайте краткий отчёт, который уже знает вашу неделю.
Повторяющаяся задача, каждое утро в 8:00. CORE собирает данные из почты, GitHub, Linear и Slack, выделяет то, что действительно требует внимания, пропускает неважное и автоматически превращает последующие действия в задачи.
Что внутри CORE
| | | |---|---| | Память | Темпоральный граф знаний по каждому инструменту и разговору. Предпочтения, решения, цели и директивы, чтобы каждая задача начиналась с загруженным контекстом. | | Задачи | Одноразовые или повторяющиеся рабочие единицы с вашим ТЗ, планом CORE, текущим состоянием и отдельной веткой чата. Каждая задача может запускать кодинг, браузерные или терминальные сессии. | | Коннекторы | 50+ приложений через одну MCP-точку, плюс триггеры webhook для проактивной автоматизации. GitHub, Linear, Jira, Slack, Gmail, Calendar, Sentry, Notion, Todoist и другие. | | Навыки | Переиспользуемые инструкции, которые автоматически срабатывают по контексту. Например: "всегда подтягивать связанные задачи Linear перед планированием фикса," "запускать тесты перед открытием PR," или "публиковать итог в Slack после завершения задачи." 100+ встроенных, или напишите свои. | | Шлюз | Запускает Claude Code, Codex, браузерных агентов и терминальные команды на вашем ПК или в Docker и Railway, чтобы CORE продолжал работу, даже когда ваш ноутбук закрыт. | | Агностичность к моделям | Используйте любого провайдера: Anthropic, OpenAI или открытые модели. Развёртывайте весь стек у себя для полной изоляции. |
Сравнение CORE
| | CORE | OpenClaw | Hermes Agent | Devin / Copilot | |---|:---:|:---:|:---:|:---:| | Несколько интерфейсов (голос, черновик, чат, мессенджеры) | ✅ | Частично | ❌ | ❌ | | Постоянная память между задачами | ✅ | ❌ | ✅ | ❌ | | Делегирует задачи кодирующим агентам (Claude Code, Codex) | ✅ | ❌ | ❌ | ✅ | | Структурированное планирование задач с одобрением человека | ✅ | ❌ | ❌ | Частично | | Пользовательское имя, личность и голос | ✅ | ❌ | ❌ | ❌ | | Более 50 подключаемых приложений | ✅ | Частично | Частично | ❌ | | Доступ к терминалу и браузеру через шлюз | ✅ | ✅ | ✅ | ✅ | | Человек в цикле по умолчанию | ✅ | ❌ | ❌ | ❌ | | Открытый исходный код и возможность самостоятельного хостинга | ✅ | ✅ | ✅ | ❌ |
Быстрый старт
Открытый исходный код и самостоятельный хостинг. Ваши данные остаются в вашей инфраструктуре.
Выберите свой путь:
| Я хочу... | Как | |---|---| | Попробовать на своем компьютере | Запустите установку в один шаг ниже (требуется Docker) | | Развернуть на сервере или VPS | Развертывание одним кликом через Railway | | Использовать приложение для Mac | Присоединиться к листу ожидания |
Установите и запустите CORE:
npm install -g @redplanethq/corebrain && corebrain setupМастер установки запрашивает каталог установки, провайдера ИИ, API-ключ и модель чата. Он генерирует секреты, запускает стек и открывает http://localhost:3033.
Большинство локальных установок занимает несколько минут после запуска Docker.
Или разверните на Railway:

Подключите шлюз, чтобы CORE мог запускать кодирующих агентов, управлять вашим браузером и получать доступ к локальным папкам:
corebrain login
corebrain gateway setupТребования: Docker 20.10+, Docker Compose 2.20+, 4 vCPU / 8GB RAM
Полное руководство по самостоятельному размещению
Ваше первое задание (2 минуты после установки):
- Откройте Scratchpad (ваша ежедневная страница по адресу
http://localhost:3033) - Введите
[ ] Подытожить мои открытые задачи GitHubили любую задачу, которую обычно выполняете сами - CORE подхватит её в течение 3 минут, соберёт контекст из подключённых приложений и составит план
- Одобрите план, CORE выполнит его и вернёт результат
Документация
- Память - временной граф знаний, классификация фактов, извлечение по намерению
- Scratchpad - ежедневная поверхность для начала задач и идей
- Задачи - планы, состояние, регулярная работа и контекст задачи
- Инструментарий - более 1000 действий в 50+ приложениях через MCP
- CORE Agent - триггеры, память, инструменты и выполнение
- Шлюз - доступ через WhatsApp, Slack, Telegram, email, web и API
- Навыки - повторяемые инструкции для автоматизации рабочих процессов
- Самостоятельное размещение - полное руководство по развертыванию
- Изменения - что было выпущено
Бенчмарк
CORE достигает 88.24% средней точности по LoCoMo benchmark на задачах с одним шагом, несколькими шагами, открытой областью и временным анализом. Полные результаты и сравнения с базовыми системами смотрите в репозитории бенчмарка.
Безопасность
- Сертификация CASA Tier 2
- TLS 1.3 при передаче данных
- AES-256 при хранении данных
- Ваши данные никогда не используются для обучения моделей
- Самостоятельный хостинг для полной изоляции
- Политика безопасности
- Уязвимости: harshith@poozle.dev
Сообщество
Мы создаём CORE публично.
Мы открыто делимся дорожной картой и архитектурными решениями, потому что самые сложные задачи в создании персональной ОС лучше всего решаются вместе с пользователями. Добавьте звезду репозиторию, разверните его самостоятельно, делитесь своими проектами и сообщайте о сломанных или отсутствующих функциях.
- Discord — вопросы, идеи, демонстрация
- Документация по участию — как внести вклад в CORE
good-first-issue— начните здесь
Разверните свою персональную AI ОС самостоятельно.
Добавьте звезду репозиторию · Читайте документацию · Присоединяйтесь к Discord
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-07 ---