
あなた専用のAI OS
チャットボットではありません。常に稼働し、常に見守るAIです。 名前を付けて。形を作って。あなたが使うすべてにつなげて。あなたの働き方に合わせてアクセスできます。 オープンソース、自分でホスト、永遠にあなたのもの。

動作デモを見る
COREがプレーンテキストのタスクを受け取り、GitHubやメモリからコンテキストを集め、作業を計画し、Claude Codeセッションを実行し、PRを作成する様子を見てください:
常に監視。常に準備。
ほとんどのAIツールは指示を待ちます。COREは監視しています。
あなたのアプリに接続すれば、すべての活動を監視します。クライアントからメールが届く、GitHubのイシューが割り当てられる、Sentryのアラートが発火する、ミーティングが終了する。COREはそれを検知し、あなたのメモリと設定したスキルを確認して、対応するか判断を委ねます。あなたが起動しなくても、COREは自動で気付きます。
Claude Code、Codex、CursorにCOREプラグインをインストールすると、エージェントとの会話も監視されます。議論されたコンテキスト、決定、記述されたコード、すべてがメモリナレッジグラフに反映されます。次のタスクを拾うときには、前回セッションの内容を既に把握しています。
COREがアクションを起こすときは、直接実行します。メールへの返信、Linearイシューの更新、GitHub PRの作成、Slackメッセージの送信、ターミナルコマンドの実行、ブラウザの操作、あらゆるインターフェースからClaude CodeやCodexセッションの起動が可能です。空港からWhatsAppメッセージを送れば、搭乗前にコーディングセッションが開始され、PRが作成されます。 どこで自律的に動作し、どこで指示を待つかをあなたが決めます。Sentryのアラートは自動で処理しますが、マージ前には必ず確認を求めます。コーディングセッション開始前には計画を承認してください。メール送信前には確認を必須に。自律性のレベルは、タスクごと、アプリごと、アクションごとに設定可能です。
4つのアクセス方法
チャットボットはインターフェースが一つ。OSは複数持っています。
音声。 MacでCtrl+Optionを押して、やるべきことを話してください。COREはバックグラウンドで実行し、作業の流れを中断しません。
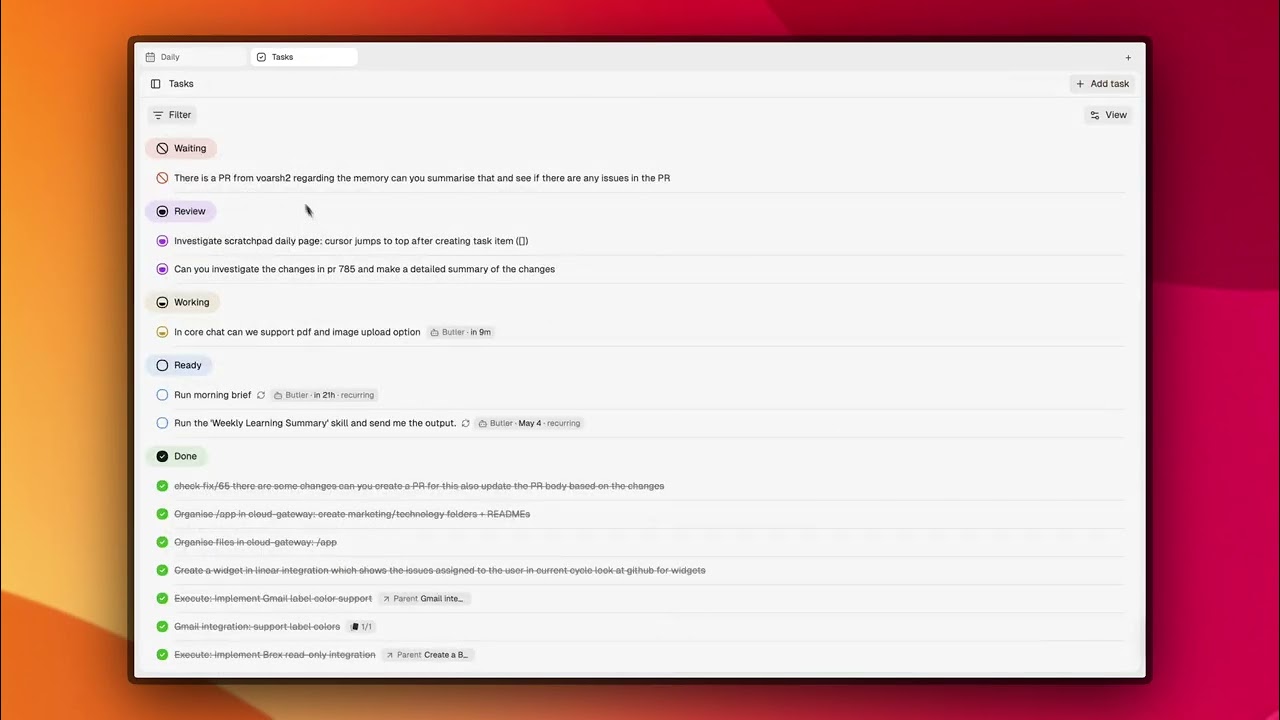
スクラッチパッド。 毎日のページを開いて「[ ] issue #47の認証バグを修正」と書いてください。COREは3分以内にタスクを拾い、リポジトリとメモリから文脈を読み込み、計画を下書きします。
メッセージング。 WhatsApp、Slack、Telegram。空港やベッド、スマホからタスクを送信。COREはどこから来たメッセージでも完全な文脈を持っています。
チャット。 ダッシュボードを開いて直接会話。委任前にやり取りしたい時に。
1つのAI、4つのインターフェース、その全ての裏に同じ記憶と文脈。
あなた専用にカスタマイズ
名前を付けて、話し方を選び、どこでも守るべきルールを設定しましょう。
5つの内蔵パーソナリティから選択 — TARSの乾いた効率性、Alfredの忠実なフォーマルさ、Hudsonの温かい実用性 — あるいは自作も可能。そのパーソナリティは全タスク、全計画、全メッセージに反映されます。
音声対話用のボイスも選べます。それ以降、全インターフェースであなたが設定したAIの声と挙動になります。
COREの実践例
話して、戻ればPR。
Ctrl+Optionを押して話す: 「issue #312のチェックアウトフローの競合状態を修正して。」
COREがissueを読み込み、関連コミットやSlackスレッドを取得し、計画を下書きし、Claude Codeセッションを実行。戻るとdiffができています。席にいなくても大丈夫。
夜に書いて、朝にレビュー。
Scratchpad: [ ] 今夜のバックログを23時から処理開始
COREはLinear、GitHub、メモリから情報を取得し、優先順位付けし、あなたが眠っている間に作業を進めます。スムーズな実行結果はレビュー待ち。詰まったセッションは、停滞したタブではなく、的確な1つの質問で戻ってきます。
どこからでもメッセージで指示。
空港からWhatsApp:「認証リファクタを出荷して。」
COREはすでにブランチ、状況、あなたの好みを把握しています。Railway上で稼働中。搭乗前にセッションを起動します。
アラートをインシデント化する前に調査。
Sentryが午前2時に発火。 COREは調査し、関連トレースや過去のインシデントを記憶から取り出し、修正案を提案、Slackで通知します:「Issue #847、修正案提出、レビュー待ち。」あなたは携帯から承認。
1週間の流れを知っているブリーフを受け取る。
毎朝8時の定期タスク。 COREはメール、GitHub、Linear、Slackから情報を引き出し、本当に注意が必要なものを浮き彫りにし、不要なものはスキップし、フォローアップを自動的にタスク化します。
COREの内部構成
| | | |---|---| | メモリ | あらゆるツールと会話を横断する時系列ナレッジグラフ。好み、意思決定、目標、指示も保持し、すべてのタスクはコンテキストがロードされた状態で開始。 | | タスク | 単発・定期の作業単位。仕様、COREの計画、ライブ状態、専用チャットスレッド付き。各タスクからコーディング、ブラウザ、ターミナルセッションを生成可能。 | | コネクタ | 50以上のアプリを1つのMCPエンドポイントで接続。自動化用Webhookトリガーも。GitHub、Linear、Jira、Slack、Gmail、カレンダー、Sentry、Notion、Todoistなど多数対応。 | | スキル | コンテキストに応じて自動で発火する再利用可能な指示。例:「修正計画前に関連するLinear課題を必ず取得」「PR作成前にテスト実行」「タスク完了時にSlackサマリ投稿」など。100以上内蔵、カスタムも可能。 | | ゲートウェイ | Claude Code、Codex、ブラウザエージェント、ターミナルコマンドをローカルまたはDocker・Railway上で実行。ノートPCを閉じてもCOREは稼働継続。 | | モデル非依存 | 任意のプロバイダーを利用可能:Anthropic、OpenAI、オープンウェイトモデルなど。フルスタックのセルフホストで完全な隔離も実現。 |
COREの比較
| | CORE | OpenClaw | Hermes Agent | Devin / Copilot | |---|:---:|:---:|:---:|:---:| | 複数インターフェース(音声、スクラッチパッド、チャット、メッセージ) | ✅ | 一部 | ❌ | ❌ | | タスク間の永続的な記憶 | ✅ | ❌ | ✅ | ❌ | | コーディングエージェント(Claude Code, Codex)への委任 | ✅ | ❌ | ❌ | ✅ | | 人間による承認を伴う構造化タスク計画 | ✅ | ❌ | ❌ | 部分的 | | カスタム名、個性、音声 | ✅ | ❌ | ❌ | ❌ | | 50以上のアプリコネクタ | ✅ | 部分的 | 部分的 | ❌ | | ゲートウェイ経由のターミナルおよびブラウザーアクセス | ✅ | ✅ | ✅ | ✅ | | デフォルトで人間参加(Human-in-loop) | ✅ | ❌ | ❌ | ❌ | | オープンソースおよびセルフホスト可能 | ✅ | ✅ | ✅ | ❌ |
クイックスタート
オープンソースでセルフホスト。あなたのデータはあなたのインフラ内に保たれます。
利用方法を選択してください:
| やりたいこと | 方法 | |---|---| | 自分のマシンで試す | 下記のワンステップインストールを実行(Dockerが必要) | | サーバーやVPSにデプロイ | ワンクリックRailwayデプロイ | | Macアプリを使う | ウェイトリストに参加 |
COREをインストールして起動する:
npm install -g @redplanethq/corebrain && corebrain setupセットアップウィザードは、インストールディレクトリ、AIプロバイダー、APIキー、およびチャットモデルを尋ねます。秘密情報を生成し、スタックを起動し、http://localhost:3033 を開きます。
Dockerが起動している場合、ほとんどのローカルインストールは数分で完了します。
または Railway でデプロイ:

ゲートウェイを接続して、COREがコーディングエージェントを実行し、ブラウザを操作し、ローカルフォルダーにアクセスできるようにします。
corebrain login
corebrain gateway setup要件: Docker 20.10以上、Docker Compose 2.20以上、4 vCPU / 8GB RAM
最初のタスク(セットアップ後2分):
- Scratchpad(日次ページ、
http://localhost:3033)を開く [ ] Summarize my open GitHub issuesまたは普段自分で行うタスクを入力する- COREが3分以内にタスクを取得し、接続アプリからコンテキストを収集し、計画案を作成
- 計画案を承認すると、COREが実行して結果を返す
ドキュメント
- Memory - 時間的知識グラフ、事実分類、意図駆動型検索
- Scratchpad - タスクやアイデアが始まる日次ページ
- Tasks - 計画、状態、定期作業、タスク固有のコンテキスト
- Toolkit - MCP経由で50以上のアプリで1000以上のアクション
- CORE Agent - トリガー、メモリ、ツール、実行
- Gateway - WhatsApp、Slack、Telegram、メール、Web、APIアクセス
- Skills - 繰り返し可能なワークフローのための再利用可能な指示
- セルフホスティング - 全展開ガイド
- Changelog - 出荷済み機能
ベンチマーク
COREはLoCoMoベンチマークで単一ホップ、マルチホップ、オープンドメイン、時間的推論全体で88.24%の平均精度を達成しています。詳細結果とベースライン比較はベンチマークリポジトリを参照してください。
セキュリティ
- CASA Tier 2 認証済み
- TLS 1.3 による通信
- AES-256による保存時の暗号化
- あなたのデータはモデル学習には一切使用されません
- 完全な隔離のためのセルフホスト
- セキュリティポリシー
- 脆弱性: harshith@poozle.dev
コミュニティ
私たちはCOREをオープンに開発しています。
ロードマップやアーキテクチャの決定を公開して共有するのは、パーソナルOSを作る上で最も難しい問題が、実際に使っている人々と一緒に解決できるからです。リポジトリにスターを付け、セルフホストし、作ったものを共有し、不具合や不足点はIssueで報告してください。
- Discord - 質問・アイデア・成果発表
- 貢献ドキュメント - COREへの貢献方法
good-first-issue- ここから始めましょう
あなたのパーソナルAI OSをセルフホストしましょう。
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-07 ---