
Votre OS IA Personnel
Ce n'est pas un chatbot que vous ouvrez. C'est une IA toujours active, toujours attentive. Nommez-la. Façonnez-la. Connectez-la à tout ce que vous utilisez. Atteignez-la comme vous travaillez. Open source, auto-hébergé, à vous pour toujours.

Voyez-le en action
Regardez CORE prendre une tâche en texte brut, rassembler le contexte depuis GitHub et la mémoire, planifier le travail, lancer une session Claude Code, et ouvrir une PR :
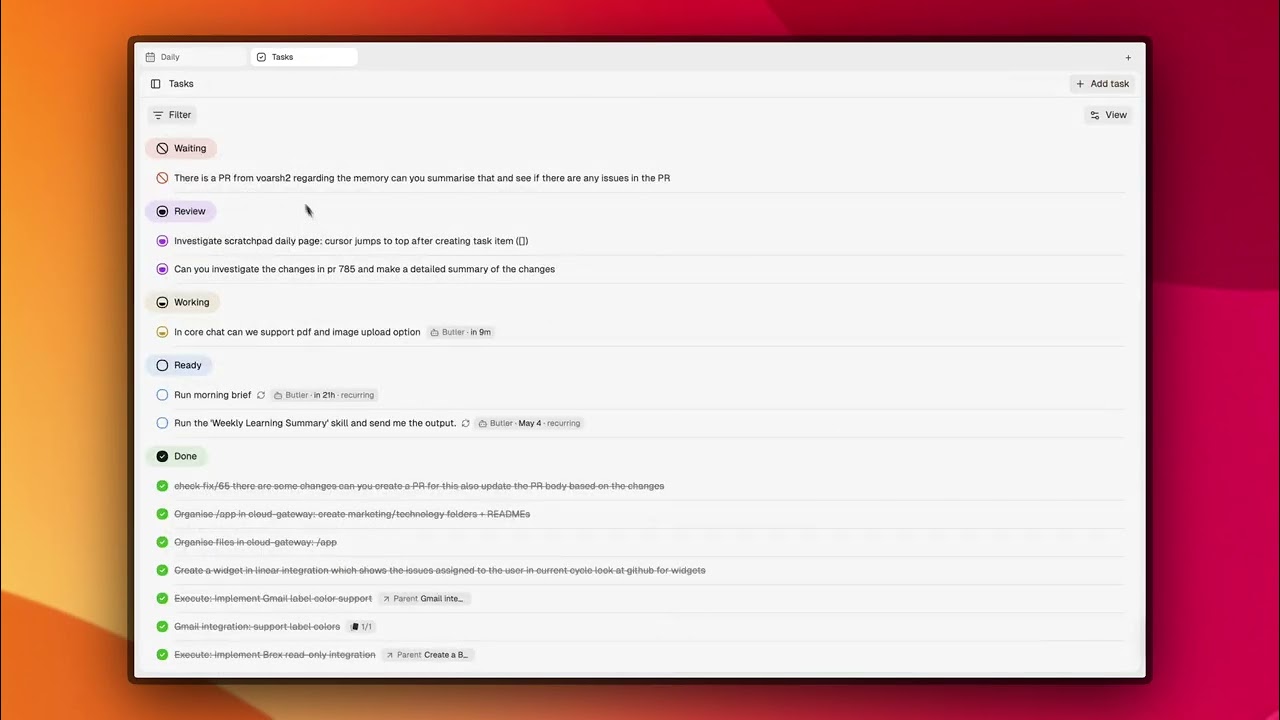
Toujours à l’affût. Toujours prêt.
La plupart des outils IA attendent qu’on les sollicite. CORE observe.
Connectez-le à vos applications et il surveille l’activité sur l’ensemble d’entre elles. Un email arrive d’un client, un ticket GitHub est assigné, une alerte Sentry se déclenche, une réunion se termine. CORE le voit, vérifie votre mémoire et les compétences que vous avez définies, puis gère la situation ou la soumet à votre jugement. Ce n’est pas vous qui le déclenchez. Il remarque de lui-même.
Installez le plugin CORE dans Claude Code, Codex ou Cursor et vos conversations d’agent seront aussi surveillées. Le contexte discuté, les décisions prises, le code écrit, tout alimente le graphe de connaissances mémoire. La prochaine tâche que CORE prendra en charge saura déjà ce qu’il s’est passé lors de votre dernière session.
Quand il agit, il agit directement. Il peut répondre aux emails, mettre à jour les tickets Linear, créer des PR GitHub, envoyer des messages Slack, exécuter des commandes terminal, piloter un navigateur, et lancer une session Claude Code ou Codex depuis n’importe quelle interface. Envoyez un message WhatsApp depuis l’aéroport et CORE peut lancer une session de code et ouvrir une PR avant que vous n’embarquiez.
Vous décidez où il agit de lui-même et où il attend votre appel. Gérez automatiquement les alertes Sentry mais demandez toujours avant de fusionner. Approuvez un plan avant qu'une session de codage ne commence. Exigez une confirmation avant que tout email ne soit envoyé. Le niveau d'autonomie est à définir, par tâche, par application, par action.
Quatre façons de l'atteindre
Un chatbot possède une interface. Un système d’exploitation en a plusieurs.
Voix. Appuyez sur Ctrl+Option sur Mac et dites ce qu’il faut faire. CORE l’exécute en arrière-plan sans interrompre votre flux.
Bloc-notes. Ouvrez votre page du jour et écrivez [ ] Corriger le bug d'authentification de l’issue #47. CORE le récupère en 3 minutes, charge le contexte depuis votre dépôt et sa mémoire, et rédige un plan.
Messagerie. WhatsApp, Slack, Telegram. Envoyez une tâche depuis l’aéroport, votre téléphone, ou votre lit. CORE dispose de tout votre contexte, peu importe d’où provient le message.
Chat. Ouvrez le tableau de bord et discutez directement, comme avec un assistant. Quand vous voulez un échange avant de déléguer.
Une IA, quatre surfaces, la même mémoire et le même contexte derrière chacune.
Personnalisez-le
Donnez-lui un nom. Choisissez son style de communication. Définissez les règles qu’il suit partout.
Choisissez parmi cinq personnalités intégrées — l’efficacité sèche de TARS, la loyauté formelle d’Alfred, la chaleur pragmatique de Hudson — ou écrivez la vôtre. La personnalité se retrouve dans chaque tâche, chaque plan, chaque message envoyé pour vous.
Sélectionnez sa voix pour les interactions vocales. Dès lors, il parle et se comporte comme l’IA que vous avez configurée, sur chaque interface.
CORE en action
Dites-le, revenez sur une PR.
Appuyez sur Ctrl+Option, parlez: "Corrige le problème de concurrence dans le flux de paiement de l’issue #312."
CORE charge l’issue, récupère les commits et fils Slack liés, rédige un plan et lance une session Claude Code. Vous revenez sur un diff. Vous n’étiez jamais à votre bureau.
Écrivez-le le soir, relisez-le le matin.
Bloc-notes : [ ] Traiter les tâches en attente de ce soir à partir de 23h
CORE s’intègre à Linear, GitHub et la mémoire, priorise et traite les tâches pendant votre sommeil. Les exécutions fluides attendent votre validation. Les sessions bloquées reviennent avec une question ciblée, pas un onglet figé.
Envoyez-lui des messages depuis n’importe où.
WhatsApp depuis l’aéroport : « Déploie la refonte de l’auth. »
CORE connaît déjà la branche, le contexte et vos préférences. Il s’exécute sur Railway. Il lance la session avant que vous embarquiez.
Analysez les alertes avant qu’elles ne deviennent des incidents.
Sentry déclenche une alerte à 2h du matin. CORE enquête, extrait les traces et incidents similaires de la mémoire, propose une correction et vous notifie sur Slack : « Problème #847, correction proposée, en attente de votre validation. » Vous validez depuis votre téléphone.
Recevez un résumé qui connaît déjà votre semaine.
Tâche récurrente, chaque matin à 8h. CORE récupère emails, GitHub, Linear et Slack, fait ressortir ce qui demande vraiment de l’attention, écarte le reste, et transforme les suivis en tâches automatiquement.
Ce que contient CORE
| | | |---|---| | Mémoire | Graphe de connaissances temporelles couvrant chaque outil et conversation. Préférences, décisions, objectifs et directives, chaque tâche commence avec tout le contexte chargé. | | Tâches | Unités de travail ponctuelles ou récurrentes avec votre cahier des charges, le plan de CORE, l’état en temps réel et un fil de discussion dédié. Chaque tâche peut ouvrir une session de code, navigateur ou terminal. | | Connecteurs | Plus de 50 applications via un seul endpoint MCP, plus des déclencheurs webhook pour l’automatisation proactive. GitHub, Linear, Jira, Slack, Gmail, Calendar, Sentry, Notion, Todoist et bien d’autres. | | Compétences | Instructions réutilisables qui s’activent automatiquement selon le contexte. Par exemple : « toujours extraire les tickets Linear liés avant de planifier une correction », « lancer les tests avant d’ouvrir une PR », ou « publier un résumé sur Slack à la fin d’une tâche ». Plus de 100 intégrées, ou créez les vôtres. | | Passerelle | Exécute Claude Code, Codex, des agents navigateur et des commandes terminal sur votre machine ou dans Docker et Railway, pour que CORE continue à travailler même si votre ordinateur est fermé. | | Indépendant du modèle | Utilisez votre propre fournisseur : Anthropic, OpenAI ou des modèles open-weight. Hébergez toute la stack vous-même pour une isolation totale. |
Comparatif de CORE
| | CORE | OpenClaw | Hermes Agent | Devin / Copilot | |---|:---:|:---:|:---:|:---:| | Interfaces multiples (voix, bloc-notes, chat, messagerie) | ✅ | Partiel | ❌ | ❌ | | Mémoire persistante entre les tâches | ✅ | ❌ | ✅ | ❌ | | Délègue aux agents de codage (Claude Code, Codex) | ✅ | ❌ | ❌ | ✅ | | Planification structurée des tâches avec approbation humaine | ✅ | ❌ | ❌ | Partiel | | Nom, personnalité et voix personnalisés | ✅ | ❌ | ❌ | ❌ | | Plus de 50 connecteurs d’applications | ✅ | Partiel | Partiel | ❌ | | Accès au terminal et au navigateur via une passerelle | ✅ | ✅ | ✅ | ✅ | | Boucle humaine activée par défaut | ✅ | ❌ | ❌ | ❌ | | Open source et auto-hébergé | ✅ | ✅ | ✅ | ❌ |
Démarrage rapide
Open source et auto-hébergé. Vos données restent dans votre infrastructure.
Choisissez votre voie :
| Je veux... | Comment | |---|---| | L’essayer sur ma machine | Lancez l’installation en une étape ci-dessous (Docker requis) | | Déployer sur un serveur ou un VPS | Déploiement Railway en un clic | | Utiliser l’application Mac | Inscrivez-vous sur la liste d’attente |
Installez et démarrez CORE :
npm install -g @redplanethq/corebrain && corebrain setupL'assistant d'installation demande un répertoire d'installation, un fournisseur d'IA, une clé API et un modèle de chat. Il génère des secrets, démarre la pile et ouvre http://localhost:3033.
La plupart des installations locales prennent quelques minutes une fois Docker lancé.
Ou déployez sur Railway :

Connectez une passerelle pour que CORE puisse exécuter des agents de codage, contrôler votre navigateur et accéder aux dossiers locaux :
corebrain login
corebrain gateway setupPrérequis : Docker 20.10+, Docker Compose 2.20+, 4 vCPU / 8 Go de RAM
Guide complet d’auto-hébergement
Votre première tâche (2 minutes après l’installation) :
- Ouvrez le Scratchpad (votre page quotidienne à
http://localhost:3033) - Tapez
[ ] Résumer mes tickets GitHub ouvertsou toute tâche que vous feriez normalement vous-même - CORE la prend en charge sous 3 minutes, collecte le contexte depuis les applis connectées et rédige un plan
- Approuvez le plan, CORE l’exécute et ramène le résultat
Docs
- Mémoire - Graphe de connaissances temporelles, classification des faits, récupération basée sur l’intention
- Scratchpad - L’interface quotidienne où commencent tâches et idées
- Tâches - Plans, états, travail récurrent, et contexte lié aux tâches
- Boîte à outils - Plus de 1000 actions sur plus de 50 applis via MCP
- Agent CORE - Déclencheurs, mémoire, outils, et exécution
- Passerelle - Accès WhatsApp, Slack, Telegram, email, web et API
- Compétences - Instructions réutilisables pour des workflows répétitifs
- Auto-hébergement - Guide de déploiement complet
- Changelog - Nouveautés livrées
Benchmark
CORE atteint une précision moyenne de 88,24% sur le benchmark LoCoMo couvrant raisonnement simple, complexe, domaine ouvert et temporel. Voir le dépôt du benchmark pour les résultats complets et comparaisons de base.
Sécurité
- Certifié CASA Tier 2
- TLS 1.3 en transit
- AES-256 au repos
- Vos données ne sont jamais utilisées pour l'entraînement du modèle
- Auto-hébergement pour une isolation totale
- Politique de sécurité
- Vulnérabilités : harshith@poozle.dev
Communauté
Nous construisons CORE en public.
Nous partageons la feuille de route et les choix d’architecture ouvertement, car les problèmes les plus complexes dans la création d’un OS personnel se résolvent le mieux avec les utilisateurs. Ajoutez une étoile au dépôt, auto-hébergez-le, partagez vos réalisations et ouvrez des tickets pour les bugs ou fonctionnalités manquantes.
- Discord - questions, idées, démonstrations
- Docs de contribution - comment contribuer à CORE
good-first-issue- commencez ici
Auto-hébergez votre OS IA personnel.
Ajoutez une étoile à ce dépôt · Lire la documentation · Rejoindre Discord
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-07 ---