MoE-Adapters4CL
Code pour l'article "Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters" CVPR2024.Table des matières
- Résumé
- Approche
- Installation
- Préparation des données
- Prise en main
- Checkpoint du modèle
- MTCL
- Test
- Entraînement
- CIL
- Entraînement
- Citation
- Remerciements
Résumé
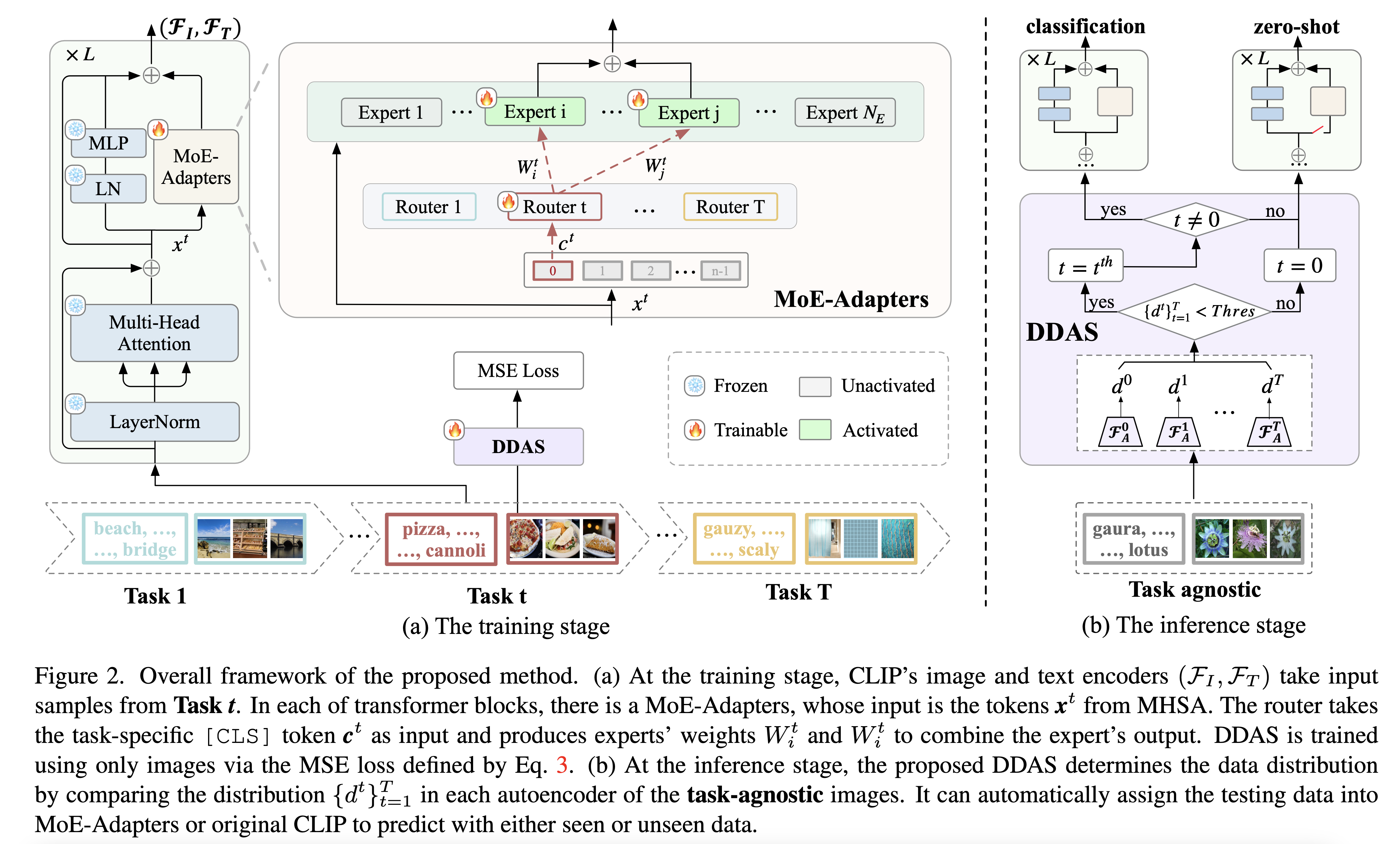
Continual learning can empower vision-language models to continuously acquire new knowledge, without the need for access to the entire historical dataset. However, mitigating the performance degradation in large-scale models is non-trivial due to (i) parameter shifts throughout lifelong learning and (ii) significant computational burdens associated with full-model tuning. In this work, we present a parameter-efficient continual learning framework to alleviate long-term forgetting in incremental learning with vision-language models. Our approach involves the dynamic expansion of a pre-trained CLIP model, through the integration of Mixture-of-Experts (MoE) adapters in response to new tasks. To preserve the zero-shot recognition capability of vision-language models, we further introduce a Distribution Discriminative Auto-Selector (DDAS) that automatically routes in-distribution and out-of-distribution inputs to the MoE Adapter and the original CLIP, respectively. Through extensive experiments across various settings, our proposed method consistently outperforms previous state-of-the-art approaches while concurrently reducing parameter training burdens by 60%.Approche
___
Installation
conda create -n MoE_Adapters4CL python=3.9
conda activate MoE_Adapters4CL
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
cd cil
pip install -r requirements.txtPréparation des données
Jeux de données cibles : Aircraft, Caltech101, CIFAR10, CIFAR100, DTD, EuroSAT, Flowers, Food, MNIST, OxfordPet, StanfordCars, SUN397, TinyImagenet.Si vous rencontrez des problèmes avec Caltech101, vous pouvez vous référer à issue#6.
Plus de détails peuvent être consultés dans datasets.md de ZSCL. Un grand merci à eux pour leur travail remarquable !
Modèle ckpt
| | Modèle | Lien | |------------------|----------------------------------------------------------------------|---------------------------------------------------------------------- | | full_shot_order1 | full_shot_order1_1000iters.pth | Baidu Disk / Google Drive | | few_shot_order1 | few_shot_order1_1000iters.pth | Baidu Disk / Google Drive |MTCL
Phase de test
Exemple :- Déplacez les checkpoints dans MoE-Adapters4CL/ckpt
- ``
cd MoE-Adapters4CL/mtil` - Exécutez le script `
bash srcipts/test/Full_Shot_order1.sh`
Phase d’entraînement
Exemple :- Déplacez les checkpoints dans MoE-Adapters4CL/ckpt
- `
cd MoE-Adapters4CL/mtil` - Exécutez le script `
bash srcipts/train/train_full_shot_router11_experts22_1000iters.sh`
Apprentissage incrémental par classe
Phase d’entraînement
Exemple :- `
cd cil` - `
bash run_cifar100-2-2.sh``
Citation
@inproceedings{yu2024boosting,
title={Boosting continual learning of vision-language models via mixture-of-experts adapters},
author={Yu, Jiazuo and Zhuge, Yunzhi and Zhang, Lu and Hu, Ping and Wang, Dong and Lu, Huchuan and He, You},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={23219--23230},
year={2024}
}Remerciements
Notre dépôt est construit sur wise-ft, Continual-CLIP et ZSCL. Nous remercions les auteurs pour le partage de leurs codes.--- Tranlated By Open Ai Tx | Last indexed: 2025-12-04 ---