FlashVID:通过无训练树状时空令牌合并实现高效视频大语言模型
🔖目录
🔥新闻
- [2026.05.01] 🔍修复Qwen2.5-VL和Qwen3-VL中手动提取[CLS]注意力时的潜在OOM错误。
- [2026.02.10] 🚀在arXiv发布我们的论文。
- [2026.02.06] 🍾我们的论文被选为ICLR 2026的口头报告。
- [2026.02.01] ✨发布基于Qwen2.5-VL和Qwen3-VL的FlashVID代码及推理演示。
- [2026.01.31] 🚀公开发布此代码库。
- [2026.01.30] ✨发布 LLaVA-OneVision 和 LLaVA-Video 上的 FlashVID 代码和推理演示。
- [2026.01.30] 👏初始化本 GitHub 仓库。
- [2026.01.26] 🎉我们的无训练推理加速方法 FlashVID 已被 ICLR 2026 接收。
- [2025.12.06] 🌟发布 DyTok 的 GitHub 仓库。
- [2025.09.18] 🎉 我们的无训练推理加速框架 DyTok 已被 NeurIPS 2025 接收。
📋待办事项
- [ ] 优化代码效率
- [x] 发布 LLaVA-OneVision 和 LLaVA-Video 上的 FlashVID 代码。
- [x] 发布基于 FlashVID 的不同视频大语言模型推理演示。
- [x] 支持使用 LMMs-Eval 进行评估。
- [x] 发布 Qwen2.5-VL 和 Qwen3-VL 上的 FlashVID 代码。
- [x] 在 arXiv 上发布我们的论文。
✨亮点
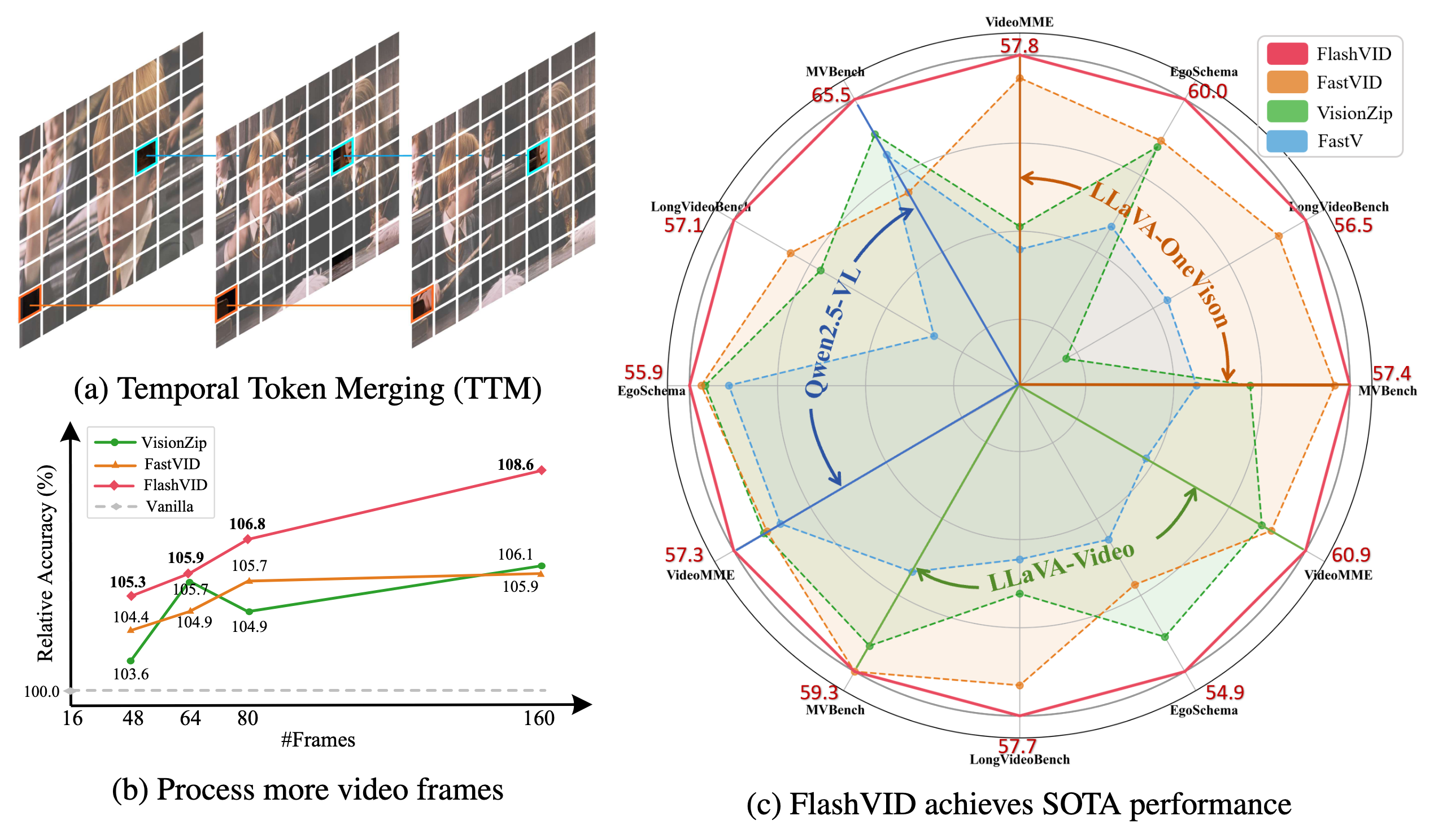
- 我们的 FlashVID 在 三个 代表性的视频大语言模型(即 LLaVA-OneVision、LLaVA-Video、Qwen2.5-VL)和 五个 广泛使用的视频理解基准(即 VideoMME、EgoSchema、LongVideoBench、MVBench、MLVU)上,显著优于之前的最先进加速框架(如 VisionZip、FastVID)。
- FlashVID 可以作为一个无训练且即插即用的模块,用于扩展长视频帧输入,使 Qwen2.5-VL 的视频帧输入量提升 10 倍,在相同计算预算下实现 8.6% 的性能提升。
- 现有高效视频大语言模型方法通常独立压缩空间和时间冗余,忽视了视频内在的时空关系。为此,我们提出了一个 简单而有效 的解决方案:基于树的时空令牌合并(TSTM),用于细粒度的时空冗余压缩。
💡动机
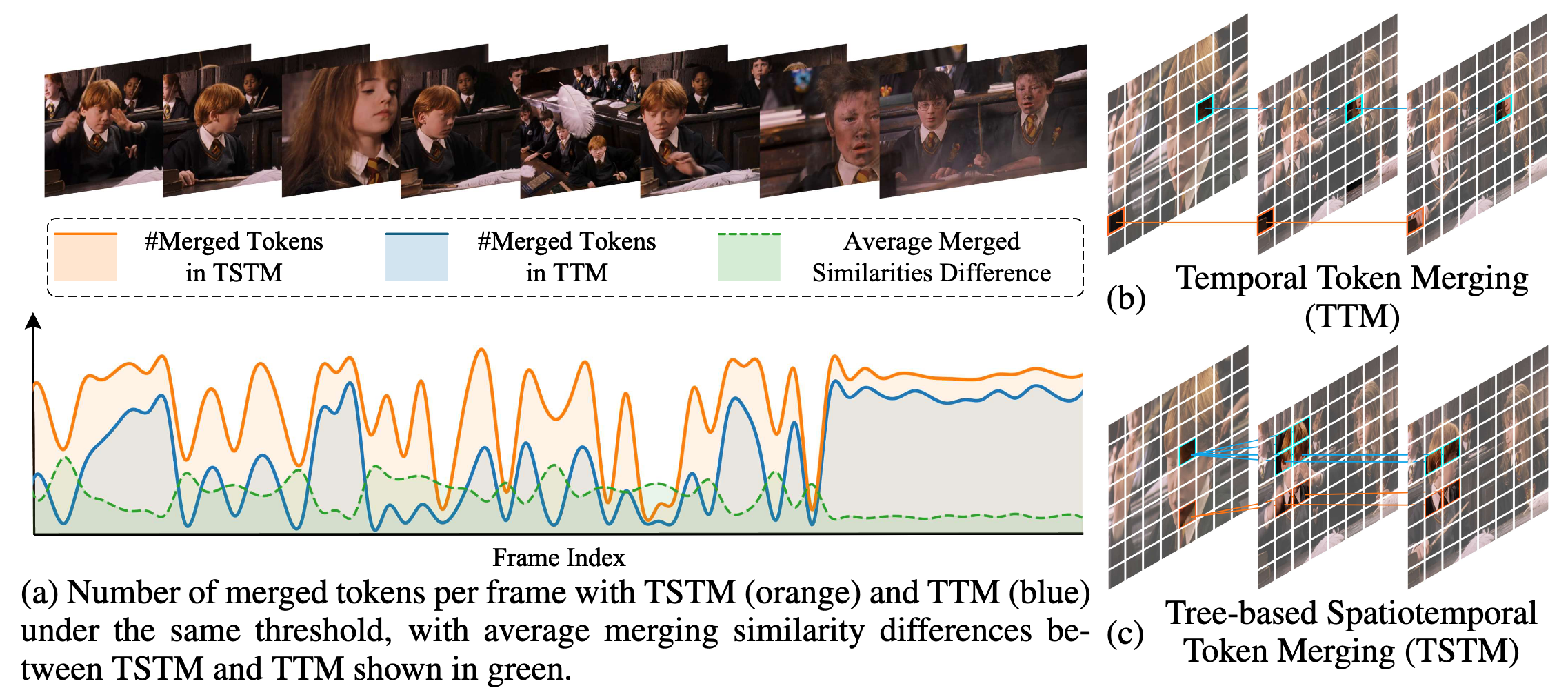
在本工作中,我们发现视频时空冗余有两个关键观察:
- 时间冗余不局限于固定的空间位置。 视频中语义一致的元素由于运动和场景动态,常在空间位置、尺度或外观上发生变化,使得跨帧的刚性空间对应不可靠。
- 空间和时间冗余本质上是耦合的。 单帧内的冗余区域常在多帧中持续存在。分离的时空冗余压缩忽视了内在的时空关系,导致压缩效果不佳。
🌈方法
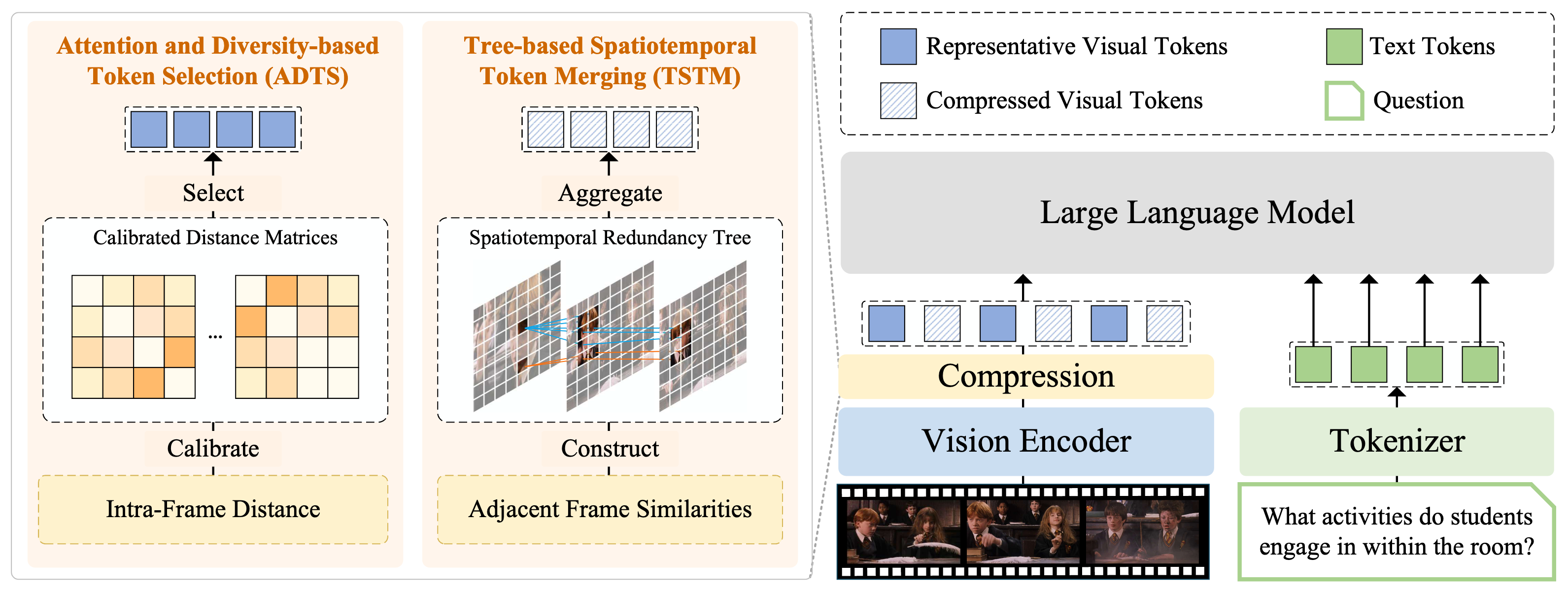
FlashVID 说明。我们通过两个协同模块压缩视觉令牌。
- 基于注意力和多样性的令牌选择(ADTS) 优先选择时空信息丰富的令牌,同时通过求解校准的最大最小多样性问题(MMDP)确保特征多样性;
- 基于树的时空令牌合并(TSTM) 通过时空冗余树建模冗余,有效捕捉细粒度视频动态。每个冗余树将被聚合为单个令牌表示。
📦安装
在本项目中,我们使用 uv 进行包管理。
- 克隆此仓库并进入 FlashVID 文件夹:
git clone https://github.com/Fanziyang-v/FlashVID.git
cd FlashVID- 安装推理包:
uv sync🚀快速开始
FlashVID 的代码易于使用,开箱即用。只需用 flashvid() 函数包装模型即可。目前,FlashVID 支持 LLaVA-OneVision、LLaVA-Video、Qwen2.5-VL 和 Qwen3-VL。
from flashvid import flashvidmodel = flashvid(
model,
retention_ratio=0.1,
alpha=0.7,
temporal_threshold=0.8,
)
📝注意:您可以在 flashvid() 包装函数中覆盖默认参数(例如,保留比例)。
推理演示在 playground/ 中提供。以下是一个运行示例:
python playground/llava_ov_infer.py \
--video-path assets/Qgr4dcsY-60.mp4 \
--question "Describe the video in detail." \
--num-frames 32 \
--enable-flashvid📊评估
在本项目中,所有实验均使用LMMs-Eval进行。我们在scripts/中提供了FlashVID评估脚本,包括LLaVA-OneVision、LLaVA-Video、Qwen2.5-VL和Qwen3-VL。您可以运行这些脚本来复现我们的实验结果:
bash scripts/llava_ov.sh📝注意:通过在__init__()中添加特定参数并用flashvid()函数包装加载的模型,将FlashVID集成到LMMs-Eval中非常简单。(参见lmms_eval/models/simple/llava_onevision.py)
👏致谢
本项目基于以下近期开源工作构建:FastV、VisionZip、PruneVID、FastVID、LLaVA-NeXT、Qwen2.5-VL/Qwen3-VL、LMMs-Eval。感谢他们的卓越工作!
📜引用
如果您在研究中发现本项目有用,请考虑引用:
@inproceedings{
fan2026flashvid,
title={Flash{VID}: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging},
author={Ziyang Fan and Keyu Chen and Ruilong Xing and Yulin Li and Li Jiang and Zhuotao Tian},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=H6rDX4w6Al}
}⭐️Star History
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-03 ---