FlashVID: 훈련 불필요한 트리 기반 시공간 토큰 병합을 통한 효율적인 비디오 대형 언어 모델
1 하얼빈 공과대학교 (선전) 2 홍콩중문대학교 (선전)
3 선전 루프 에어리어 연구소
*교신저자
🔖목차
🔥뉴스
- [2026.05.01] 🔍Qwen2.5-VL 및 Qwen3-VL에서 수동 [CLS] 어텐션 추출 시 발생할 수 있는 OOM 버그 수정.
- [2026.02.10] 🚀우리 논문을 arXiv에 공개.
- [2026.02.06] 🍾우리 논문이 ICLR 2026에서 구두 발표로 선정됨.
- [2026.02.01] ✨Qwen2.5-VL과 Qwen3-VL에 대한 FlashVID 코드 및 추론 데모 공개.
- [2026.01.31] 🚀이 저장소를 공개함.
- [2026.01.30] ✨LLaVA-OneVision 및 LLaVA-Video에서 FlashVID 코드와 추론 데모를 공개했습니다.
- [2026.01.30] 👏이 GitHub 저장소를 초기화했습니다.
- [2026.01.26] 🎉훈련이 필요 없는 추론 가속화 방법 FlashVID가 ICLR 2026에 채택되었습니다.
- [2025.12.06] 🌟DyTok GitHub 저장소를 공개했습니다.
- [2025.09.18] 🎉훈련이 필요 없는 추론 가속화 프레임워크 DyTok가 NeurIPS 2025에 채택되었습니다.
📋해야 할 일 목록
- [ ] 코드 효율성 최적화
- [x] LLaVA-OneVision 및 LLaVA-Video에서 FlashVID 코드 공개.
- [x] FlashVID를 이용한 다양한 비디오 LLM 추론 데모 공개.
- [x] LMMs-Eval을 사용한 평가 지원.
- [x] Qwen2.5-VL 및 Qwen3-VL에서 FlashVID 코드 공개.
- [x] 논문을 arXiv에 공개.
✨주요 내용
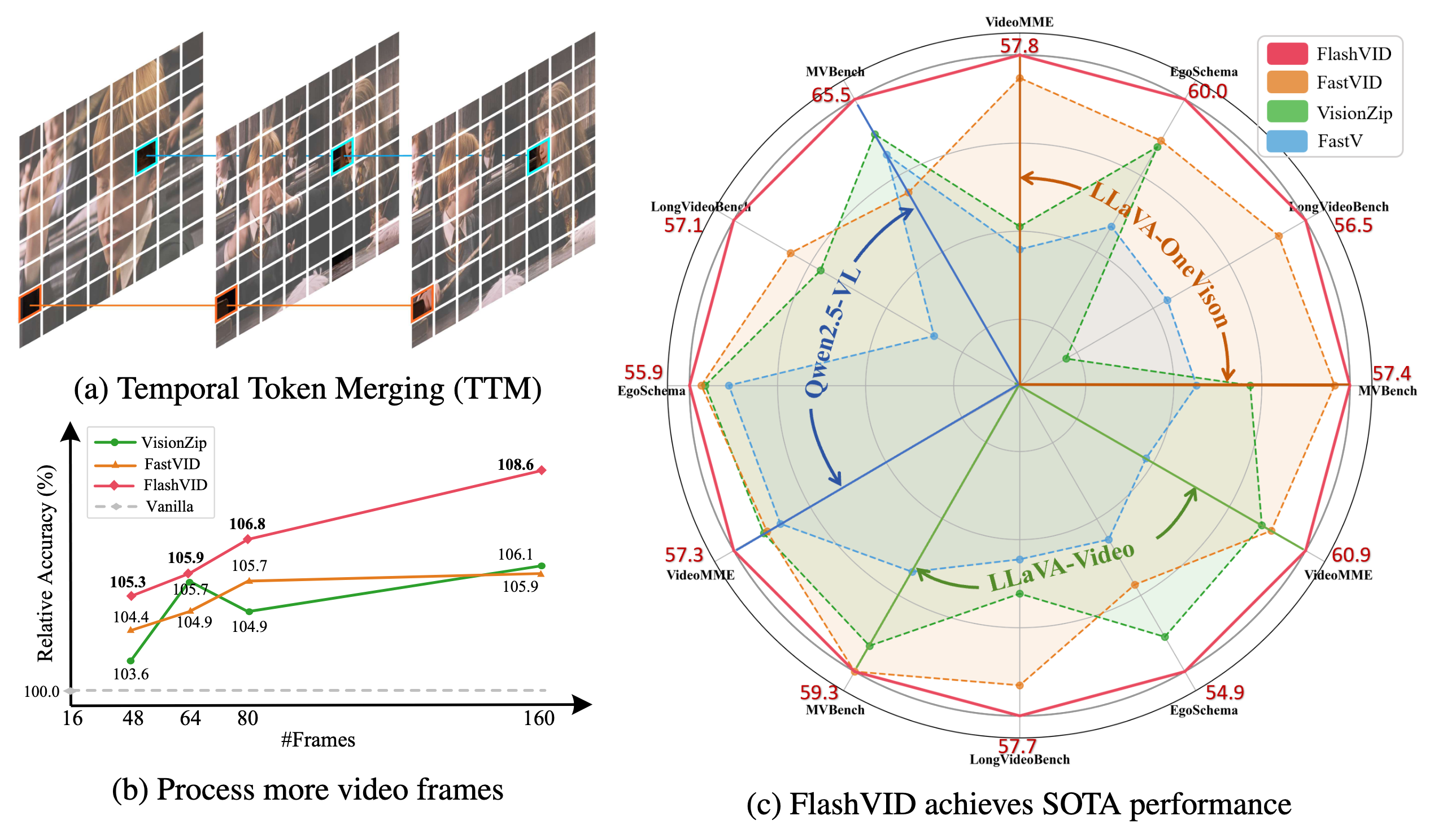
- 우리 FlashVID는 세 개의 대표적인 VLLM(즉, LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL)에서 다섯 개의 널리 사용되는 비디오 이해 벤치마크(즉, VideoMME, EgoSchema, LongVideoBench, MVBench, MLVU)에 대해 이전 최첨단 가속 프레임워크(예: VisionZip, FastVID)를 크게 능가합니다.
- FlashVID는 훈련이 필요 없고 플러그 앤 플레이 모듈로서 긴 비디오 프레임 확장이 가능하여 Qwen2.5-VL에 대해 비디오 프레임 입력을 10배 증가시키면서 동일한 계산 예산 내에서 8.6% 향상을 달성합니다.
- 기존 효율적인 비디오 LLM 방법은 공간적 및 시간적 중복을 독립적으로 압축하는 경우가 많아 비디오 내 고유한 시공간적 관계를 간과합니다. 이를 해결하기 위해, 우리는 미세한 시공간 중복 압축을 위한 간단하지만 효과적인 방법인 트리 기반 시공간 토큰 병합(Tree-based Spatiotemporal Token Merging, TSTM)을 제안합니다.
💡동기
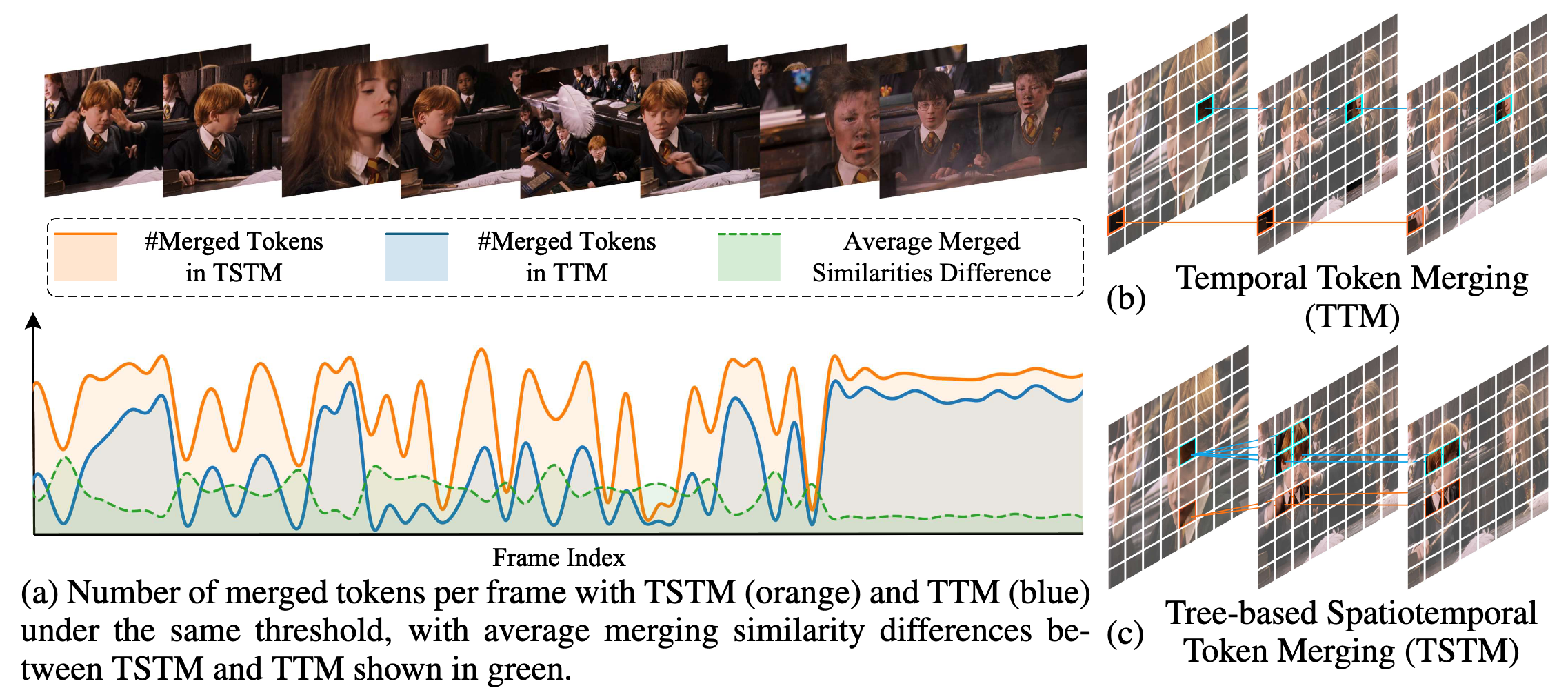
본 연구에서는 비디오 내 시공간 중복에 대해 두 가지 주요 관찰을 했습니다:
- 시간적 중복은 고정된 공간 위치에 국한되지 않습니다. 비디오 내 의미상 일관된 요소들은 움직임과 장면 변화로 인해 공간 위치, 크기, 외관이 변할 수 있어 프레임 간 엄격한 공간 대응이 신뢰할 수 없습니다.
- 공간적 및 시간적 중복은 본질적으로 결합되어 있습니다. 단일 프레임 내 중복 영역은 여러 프레임에 걸쳐 지속되는 경우가 많습니다. 시공간 중복 압축을 분리하면 고유한 시공간 관계를 무시하여 비효율적인 압축이 됩니다.
🌈방법
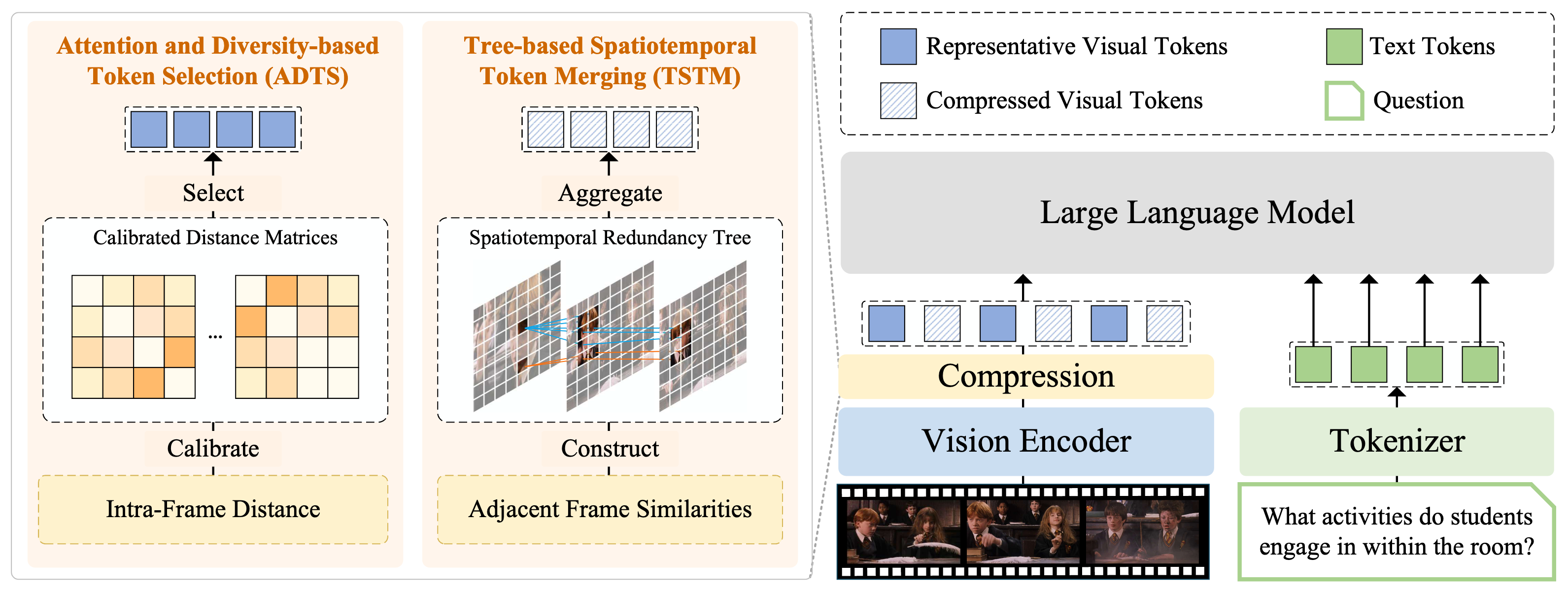
FlashVID 개요. 우리는 두 가지 시너지 모듈로 시각 토큰을 압축합니다.
- 주의집중 및 다양성 기반 토큰 선택(ADTS)은 보정된 최대-최소 다양성 문제(MMDP)를 해결하여 시공간적으로 정보가 풍부한 토큰을 우선 선택하면서 특징 다양성을 보장합니다;
- 트리 기반 시공간 토큰 병합(TSTM)은 시공간 중복성 트리를 통해 중복성을 모델링하며, 이는 미세한 비디오 동적 변화를 효과적으로 포착합니다. 각 중복성 트리는 단일 토큰 표현으로 집계됩니다.
📦설치
이 프로젝트에서는 패키지 관리를 위해 uv를 사용합니다.
- 이 저장소를 클론하고 FlashVID 폴더로 이동하세요:
git clone https://github.com/Fanziyang-v/FlashVID.git
cd FlashVID- 추론 패키지 설치:
uv sync🚀빠른 시작
FlashVID의 코드는 사용하기 쉽고 바로 작동합니다. 모델을 flashvid() 함수로 감싸기만 하면 됩니다. 현재 FlashVID는 LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL, Qwen3-VL을 지원합니다.
from flashvid import flashvidmodel = flashvid(
model,
retention_ratio=0.1,
alpha=0.7,
temporal_threshold=0.8,
)
📝참고: 기본 매개변수(예: 유지 비율)는 flashvid() 래퍼 함수에서 재정의할 수 있습니다.
추론 데모는 playground/에 제공됩니다. 실행 예시는 다음과 같습니다:
python playground/llava_ov_infer.py \
--video-path assets/Qgr4dcsY-60.mp4 \
--question "Describe the video in detail." \
--num-frames 32 \
--enable-flashvid📊평가
이 프로젝트에서는 모든 실험이 LMMs-Eval을 사용하여 수행됩니다. scripts/에는 LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL, Qwen3-VL을 포함한 FlashVID 평가 스크립트가 제공됩니다. 스크립트를 실행하여 우리의 실험 결과를 재현할 수 있습니다:
bash scripts/llava_ov.sh📝참고: __init__()에 특정 매개변수를 추가하고 로드된 모델을 flashvid() 함수로 감싸기만 하면 FlashVID를 LMMs-Eval에 매우 쉽게 통합할 수 있습니다. (lmms_eval/models/simple/llava_onevision.py 참고)
👏감사의 글
이 프로젝트는 최근 오픈소스 작업들을 기반으로 구축되었습니다: FastV, VisionZip, PruneVID, FastVID, LLaVA-NeXT, Qwen2.5-VL/Qwen3-VL, LMMs-Eval. 이들의 훌륭한 작업에 감사드립니다!
📜인용
이 프로젝트가 연구에 유용하다면, 인용을 고려해 주시기 바랍니다:
@inproceedings{
fan2026flashvid,
title={Flash{VID}: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging},
author={Ziyang Fan and Keyu Chen and Ruilong Xing and Yulin Li and Li Jiang and Zhuotao Tian},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=H6rDX4w6Al}
}⭐️Star History
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-03 ---