FlashVID: トレーニング不要の木構造ベース時空間トークンマージによる効率的な動画大規模言語モデル
1 ハルビン工業大学(深セン) 2 香港中文大学(深セン)
3 深圳ループエリア研究所
*責任著者
🔖目次
🔥ニュース
- [2026.05.01] 🔍Qwen2.5-VLおよびQwen3-VLにおける手動[CLS]アテンション抽出の潜在的OOMバグを修正。
- [2026.02.10] 🚀論文をarXivに公開。
- [2026.02.06] 🍾論文がICLR 2026の口頭発表に選出されました。
- [2026.02.01] ✨FlashVIDのコードと推論デモをQwen2.5-VLおよびQwen3-VLで公開。
- [2026.01.31] 🚀本リポジトリを一般公開。
- [2026.01.30] ✨LLaVA-OneVision と LLaVA-Video 上での FlashVID コードおよび推論デモをリリースしました。
- [2026.01.30] 👏このGitHubリポジトリを初期化しました。
- [2026.01.26] 🎉トレーニング不要の推論高速化手法 FlashVID が ICLR 2026 に採択されました。
- [2025.12.06] 🌟DyTok のGitHubリポジトリを公開しました。
- [2025.09.18] 🎉トレーニング不要の推論高速化フレームワーク DyTok が NeurIPS 2025 に採択されました。
📋Todo リスト
- [ ] コード効率の最適化
- [x] LLaVA-OneVision と LLaVA-Video で FlashVID コードをリリースする。
- [x] FlashVID を用いた異なる Video LLM の推論デモをリリースする。
- [x] LMMs-Eval を用いた評価をサポートする。
- [x] Qwen2.5-VL と Qwen3-VL で FlashVID コードをリリースする。
- [x] 論文を arXiv に公開する。
✨ハイライト
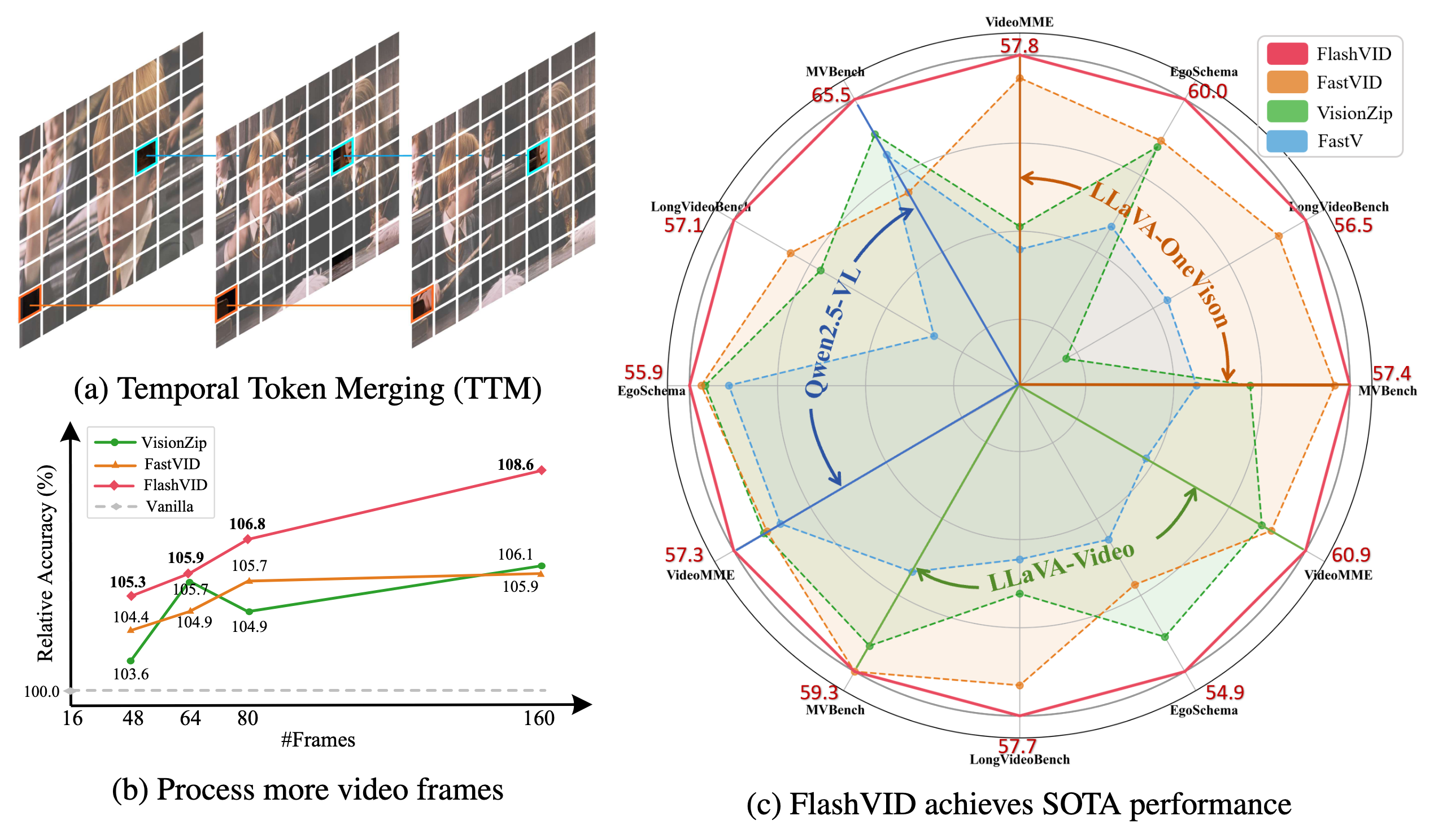
- FlashVID は、三つの代表的な VLLMs(LLaVA-OneVision、LLaVA-Video、Qwen2.5-VL)において、五つの広く使われる動画理解ベンチマーク(VideoMME、EgoSchema、LongVideoBench、MVBench、MLVU)上で、従来の最先端高速化フレームワーク(例:VisionZip、FastVID)を大幅に上回ります。
- FlashVID はトレーニング不要のプラグアンドプレイモジュールとして機能し、長尺動画フレームの拡張を可能にします。これにより Qwen2.5-VL への動画フレーム入力を 10倍 に増やし、同じ計算コスト内で 8.6% の性能向上を実現します。
- 既存の効率的な Video LLM 手法は、空間的および時間的冗長性を独立に圧縮することが多く、動画の本質的な時空間関係を見落としています。これに対処するために、我々は シンプルかつ効果的な 解決策として、細粒度の時空間冗長圧縮を実現するツリーベースの時空間トークンマージ(TSTM)を提案します。
💡動機
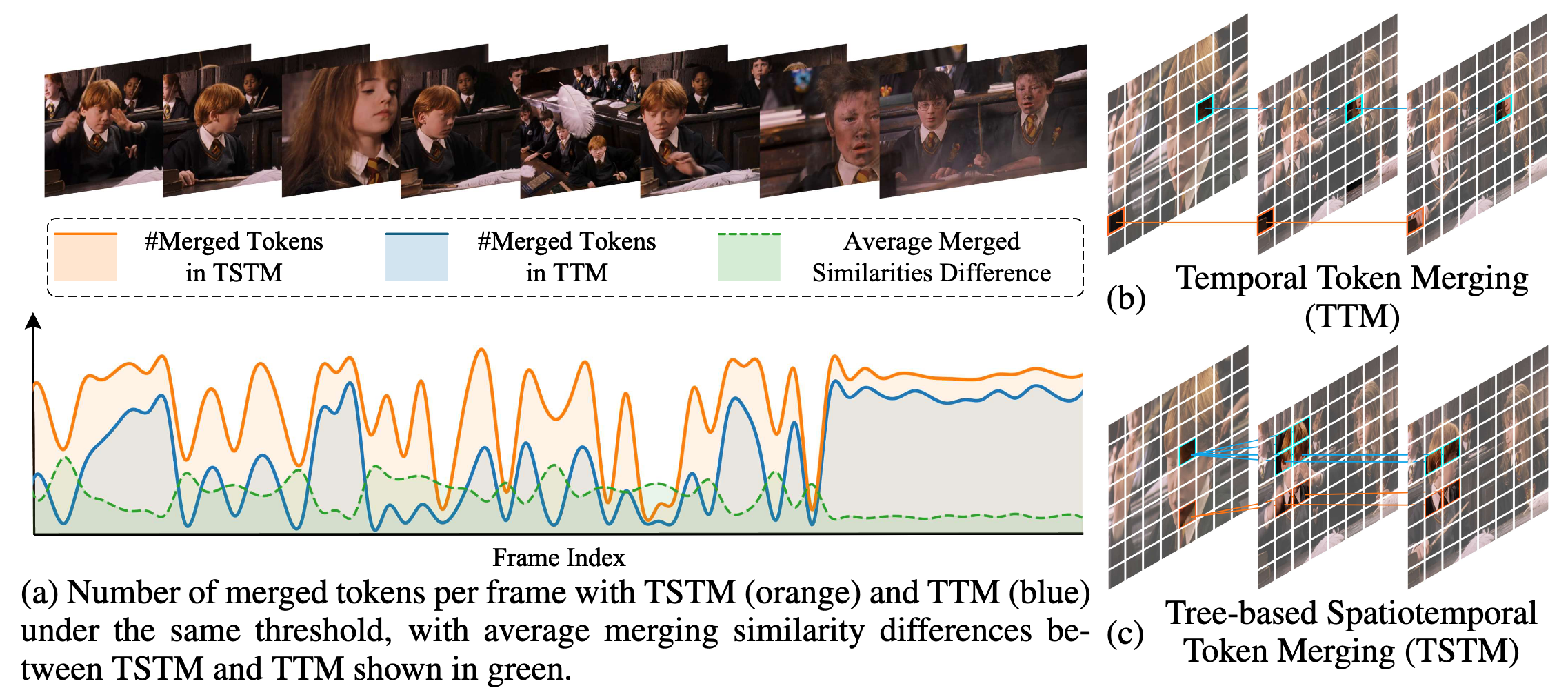
本研究では、動画の時空間冗長性に関して二つの重要な観察を行いました:
- 時間的冗長性は固定された空間位置に縛られない。 動画内の意味的に一貫した要素は、動きやシーンの変化により空間的位置、スケール、外観が変化することが多く、フレーム間で厳密な空間対応は信頼できません。
- 空間的冗長性と時間的冗長性は本質的に結びついている。 一つのフレーム内の冗長な領域は複数のフレームにわたって持続することが多いです。時空間の冗長圧縮を切り離して行うと、本質的な時空間関係を見落とし、最適でない圧縮につながります。
🌈手法
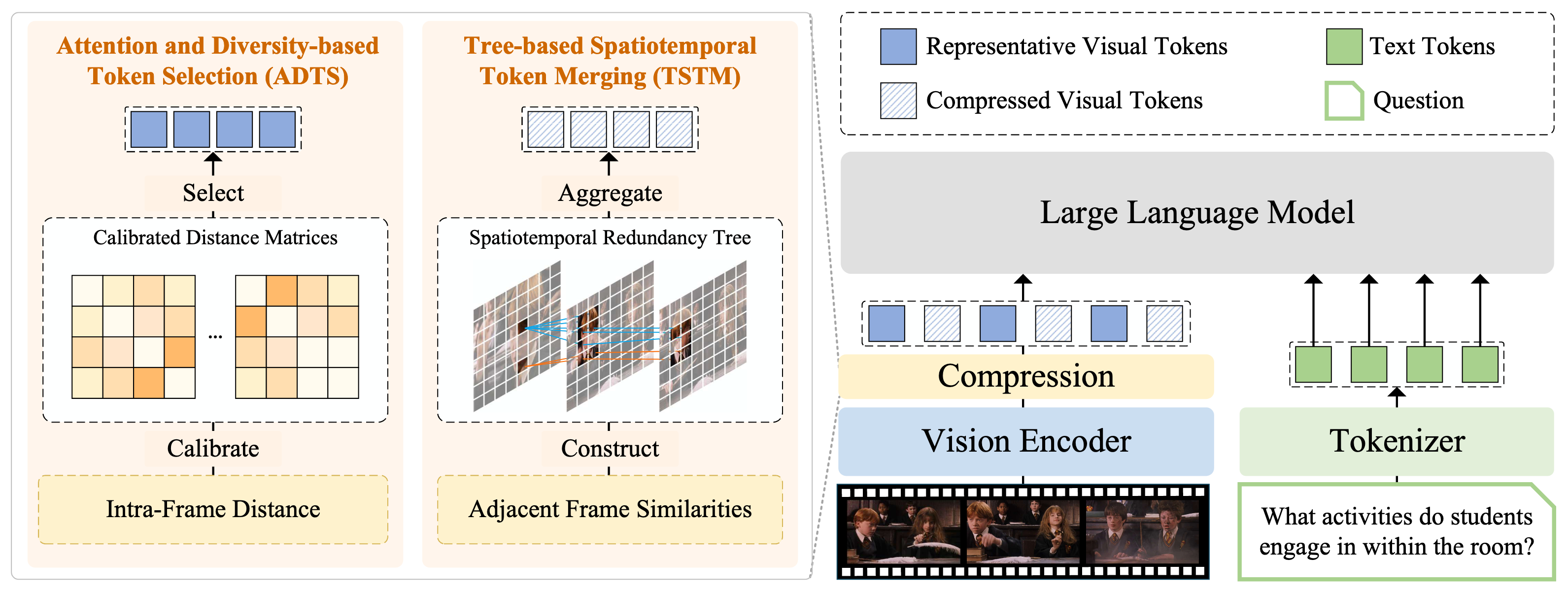
FlashVID の概要図。我々は二つの相乗効果を持つモジュールによって視覚トークンを圧縮します。
- 注意力と多様性に基づくトークン選択(ADTS) は、調整された最大最小多様性問題(MMDP)を解くことで、時空間的に情報量の多いトークンを優先しつつ特徴の多様性を確保します。
- ツリー型時空間トークンマージ(TSTM) は、時空間的冗長性ツリーによって冗長性をモデル化し、細粒度の動画ダイナミクスを効果的に捉えます。各冗長性ツリーは単一のトークン表現に集約されます。
📦インストール
このプロジェクトでは、パッケージ管理にuvを使用します。
- このリポジトリをクローンし、FlashVIDフォルダに移動します:
git clone https://github.com/Fanziyang-v/FlashVID.git
cd FlashVID- 推論パッケージをインストールします:
uv sync🚀クイックスタート
FlashVIDのコードは使いやすく、そのまま動作します。モデルをflashvid()関数でラップするだけです。現在、FlashVIDはLLaVA-OneVision、LLaVA-Video、Qwen2.5-VL、Qwen3-VLをサポートしています。
from flashvid import flashvidmodel = flashvid(
model,
retention_ratio=0.1,
alpha=0.7,
temporal_threshold=0.8,
)
📝注意: flashvid() ラッパー関数内でデフォルトパラメータ(例:保持率)を上書きできます。
推論デモは playground/ に用意されています。以下は実行例です:
python playground/llava_ov_infer.py \
--video-path assets/Qgr4dcsY-60.mp4 \
--question "Describe the video in detail." \
--num-frames 32 \
--enable-flashvid📊評価
このプロジェクトでは、すべての実験をLMMs-Evalを使用して実施しています。scripts/にFlashVID評価スクリプトを提供しており、LLaVA-OneVision、LLaVA-Video、Qwen2.5-VL、Qwen3-VLが含まれています。スクリプトを実行することで、私たちの実験結果を再現できます。
bash scripts/llava_ov.sh📝注意: FlashVIDをLMMs-Evalに統合するのは非常に簡単で、__init__()に特定のパラメータを追加し、読み込んだモデルをflashvid()関数でラップするだけです。(詳細はlmms_eval/models/simple/llava_onevision.pyを参照)
👏謝辞
本プロジェクトは以下の最近のオープンソース作品に基づいています:FastV、VisionZip、PruneVID、FastVID、LLaVA-NeXT、Qwen2.5-VL/Qwen3-VL、LMMs-Eval。優れた成果に感謝します!
📜引用
本プロジェクトが研究に役立った場合は、ぜひ以下を引用してください:
@inproceedings{
fan2026flashvid,
title={Flash{VID}: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging},
author={Ziyang Fan and Keyu Chen and Ruilong Xing and Yulin Li and Li Jiang and Zhuotao Tian},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=H6rDX4w6Al}
}⭐️Star History
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-03 ---