FlashVID : Modèles vidéo à grande échelle efficaces via fusion de tokens spatiotemporels arborescente sans entraînement
1 Institut de Technologie de Harbin (Shenzhen) 2 Université chinoise de Hong Kong (Shenzhen)
3 Institut de la zone de boucle de Shenzhen
*Auteur correspondant
🔖Table des matières
- Actualités
- Liste des tâches
- Points forts
- Motivation
- Méthode
- Installation
- Démarrage rapide
- Évaluation
- Remerciements
- Citation
🔥Actualités
- [2026.05.01] 🔍Correction d’un bug potentiel de manque de mémoire (OOM) lors de l’extraction manuelle de l’attention [CLS] dans Qwen2.5-VL et Qwen3-VL.
- [2026.02.10] 🚀Publication de notre article sur arXiv.
- [2026.02.06] 🍾Notre article a été sélectionné pour une présentation orale à ICLR 2026.
- [2026.02.01] ✨Publication du code FlashVID et des démonstrations d’inférence sur Qwen2.5-VL et Qwen3-VL.
- [2026.01.31] 🚀Ouverture au public de ce dépôt.
- [2026.01.30] ✨Publication du code FlashVID et des démonstrations d’inférence sur LLaVA-OneVision et LLaVA-Video.
- [2026.01.30] 👏Initialisation de ce dépôt GitHub.
- [2026.01.26] 🎉Notre méthode d’accélération d’inférence sans entraînement FlashVID a été acceptée à ICLR 2026.
- [2025.12.06] 🌟Publication du dépôt GitHub de DyTok.
- [2025.09.18] 🎉 Notre cadre d’accélération d’inférence sans entraînement DyTok a été accepté à NeurIPS 2025.
📋Liste des tâches
- [ ] Optimiser l’efficacité du code
- [x] Publier le code FlashVID sur LLaVA-OneVision et LLaVA-Video.
- [x] Publier les démonstrations d’inférence sur différents Video LLMs avec FlashVID.
- [x] Supporter l’évaluation avec LMMs-Eval.
- [x] Publier le code FlashVID sur Qwen2.5-VL et Qwen3-VL.
- [x] Publier notre article sur arXiv.
✨Points forts
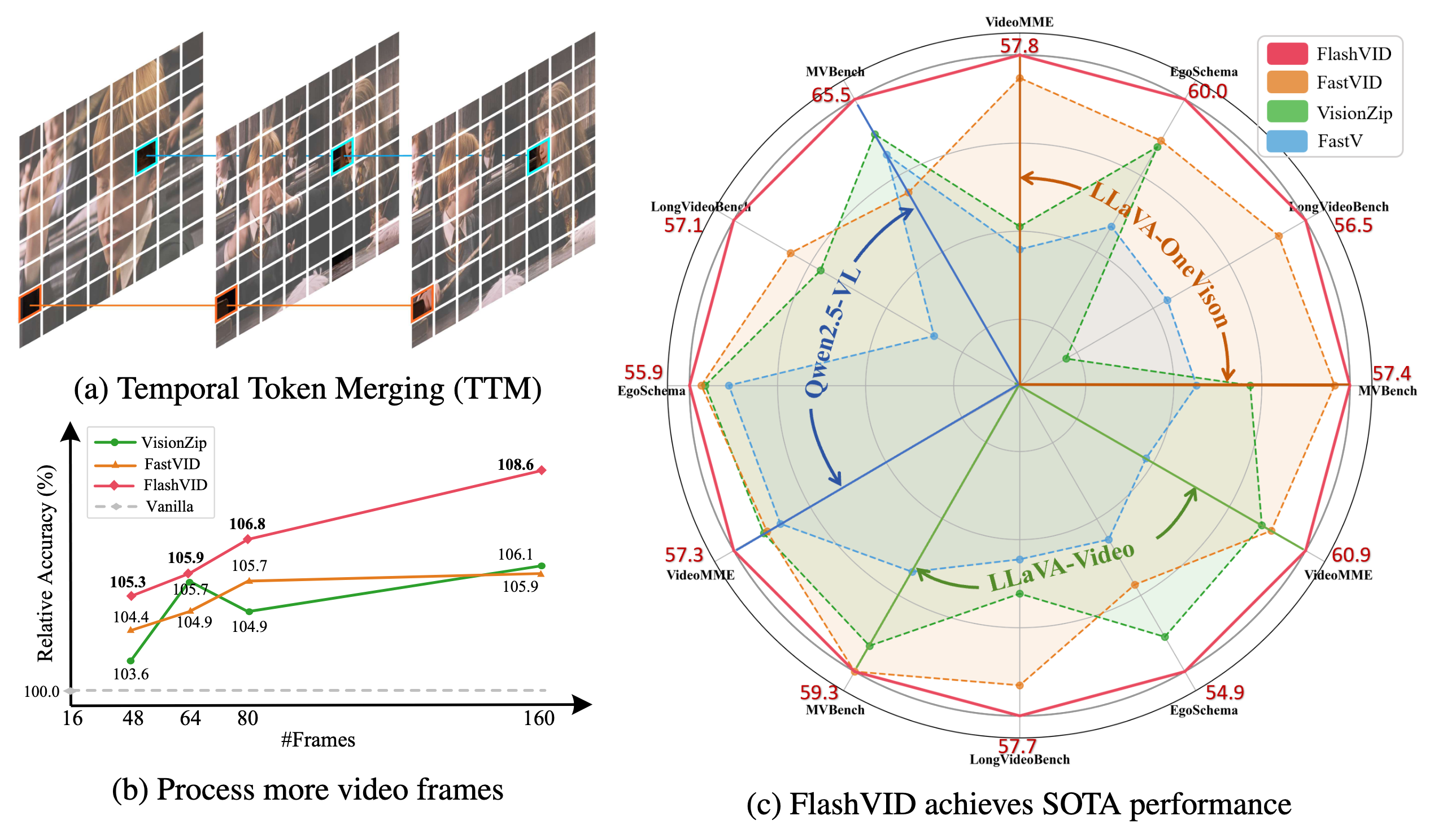
- Notre FlashVID surpasse significativement les cadres d’accélération à la pointe précédents (par ex., VisionZip, FastVID) sur trois VLLMs représentatifs (c.-à-d. LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL) sur cinq benchmarks largement utilisés pour la compréhension vidéo (c.-à-d. VideoMME, EgoSchema, LongVideoBench, MVBench, MLVU).
- FlashVID peut servir de module plug-and-play sans entraînement pour étendre les frames vidéo longues, permettant une augmentation par un facteur 10x de l’entrée de frames vidéo à Qwen2.5-VL, avec un gain de 8,6% dans le même budget computationnel.
- Les méthodes existantes efficaces pour Video LLM compressent souvent indépendamment la redondance spatiale et temporelle, négligeant les relations spatiotemporelles intrinsèques dans les vidéos. Pour y remédier, nous présentons une solution simple mais efficace : la fusion de tokens spatiotemporels basée sur un arbre (TSTM) pour une compression fine de la redondance spatiotemporelle.
💡Motivation
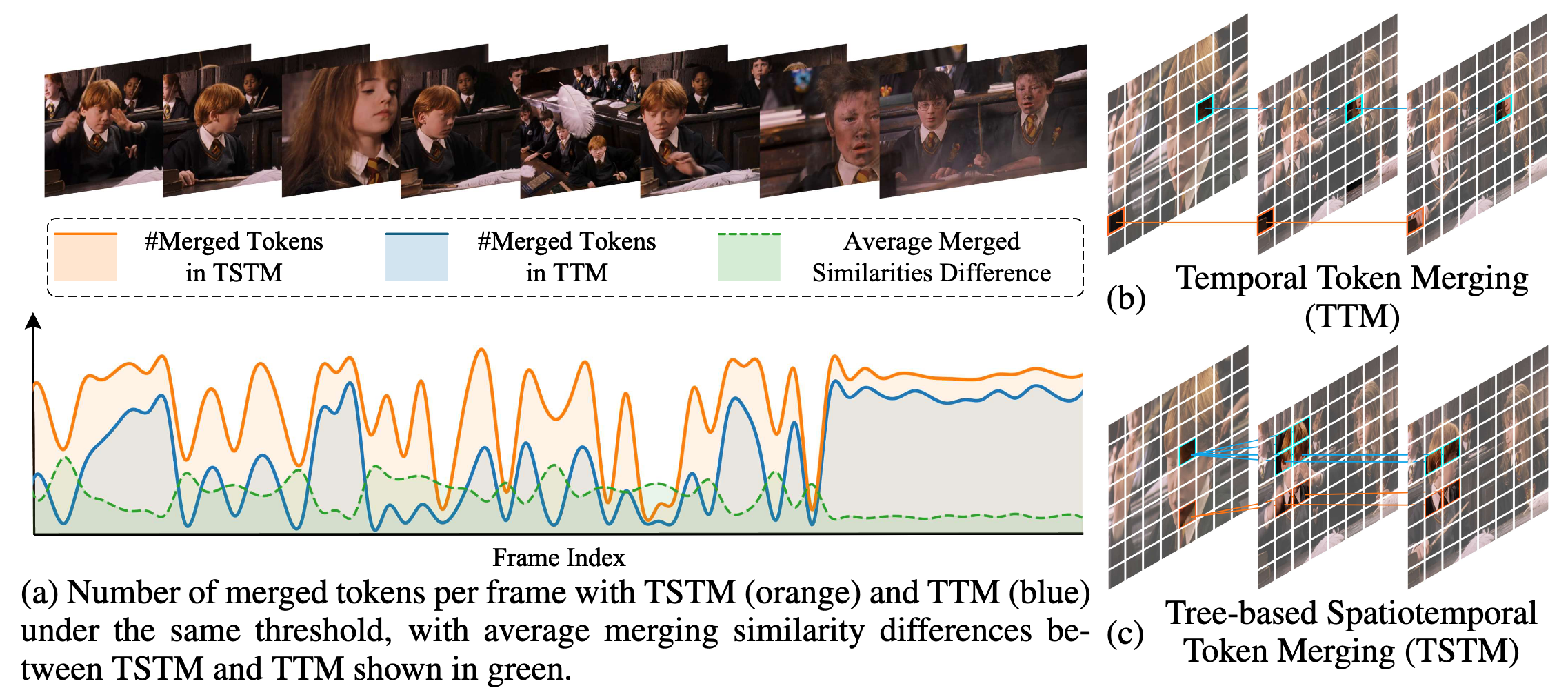
Dans ce travail, nous identifions deux observations clés sur la redondance spatiotemporelle dans les vidéos :
- La redondance temporelle n’est pas liée à des emplacements spatiaux fixes. Les éléments sémantiquement cohérents dans les vidéos se déplacent souvent en position spatiale, échelle ou apparence à cause du mouvement et de la dynamique de la scène, rendant la correspondance spatiale rigide entre les frames peu fiable.
- La redondance spatiale et temporelle est intrinsèquement couplée. Les régions redondantes dans une seule frame persistent fréquemment à travers plusieurs frames. Une compression spatiotemporelle découplée néglige les relations spatiotemporelles intrinsèques, conduisant à une compression sous-optimale.
🌈Méthode
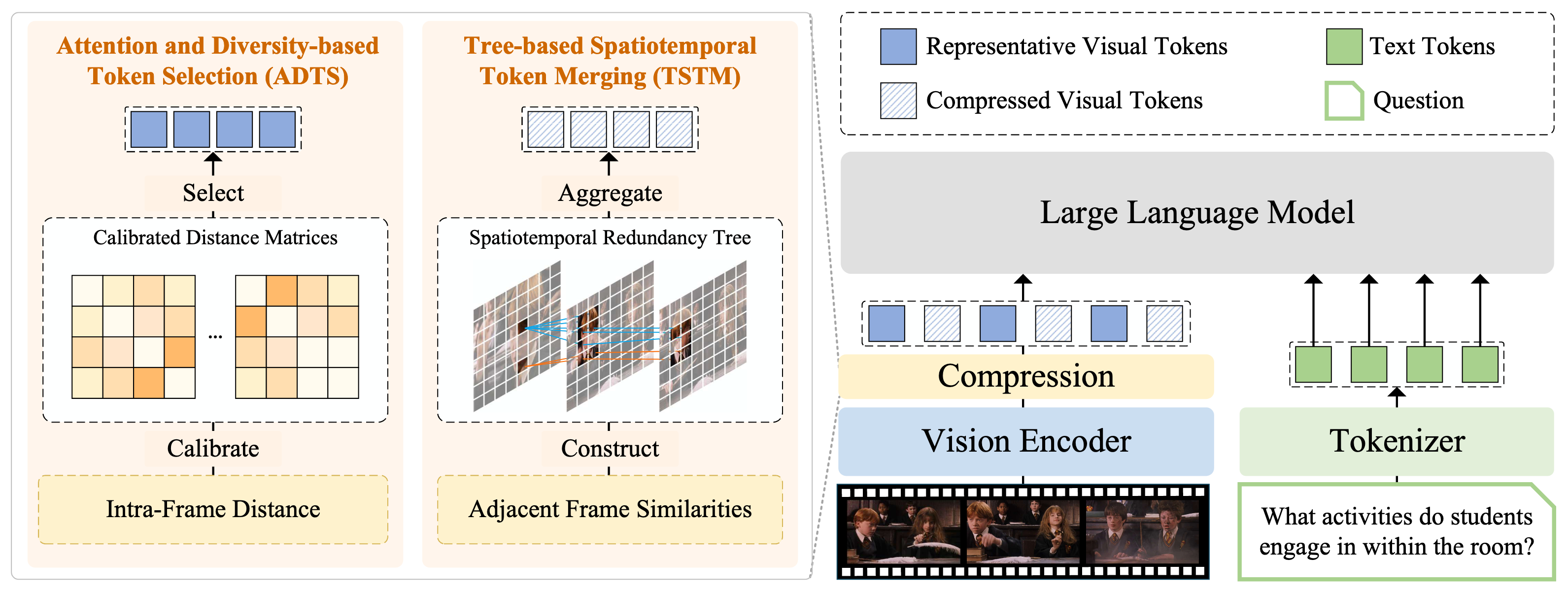
Illustration de FlashVID. Nous compressons les tokens visuels via deux modules synergiques.
- Sélection de jetons basée sur l'attention et la diversité (ADTS) priorise les jetons spatiotemporellement informatifs tout en garantissant la diversité des caractéristiques en résolvant un Problème de Diversité Max-Min calibré (MMDP);
- Fusion de jetons spatiotemporels basée sur un arbre (TSTM) modélise la redondance par des arbres de redondance spatiotemporelle, qui capturent efficacement la dynamique fine des vidéos. Chaque arbre de redondance sera agrégé en une seule représentation de jeton.
📦Installation
Dans ce projet, nous utilisons uv pour la gestion des paquets.
- Clonez ce dépôt et naviguez jusqu'au dossier FlashVID :
git clone https://github.com/Fanziyang-v/FlashVID.git
cd FlashVID- Installer le package d'inférence :
uv sync🚀Démarrage rapide
Le code de FlashVID est facile à utiliser et fonctionne immédiatement. Il suffit d'encapsuler le modèle avec la fonction flashvid(). Actuellement, FlashVID prend en charge LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL et Qwen3-VL.
from flashvid import flashvidmodel = flashvid(
model,
retention_ratio=0.1,
alpha=0.7,
temporal_threshold=0.8,
)
📝Remarque : Vous pouvez remplacer les paramètres par défaut (par exemple, le taux de rétention) dans la fonction wrapper flashvid().
Des démonstrations d'inférence sont fournies dans playground/. Voici un exemple en cours d'exécution :
python playground/llava_ov_infer.py \
--video-path assets/Qgr4dcsY-60.mp4 \
--question "Describe the video in detail." \
--num-frames 32 \
--enable-flashvid📊Évaluation
Dans ce projet, toutes les expériences sont réalisées en utilisant LMMs-Eval. Nous fournissons des scripts d'évaluation FlashVID dans scripts/, incluant LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL, et Qwen3-VL. Vous pouvez exécuter les scripts pour reproduire nos résultats expérimentaux :
bash scripts/llava_ov.sh📝Note : Il est extrêmement facile d’intégrer FlashVID dans LMMs-Eval en ajoutant des paramètres spécifiques dans __init__() et en enveloppant le modèle chargé avec la fonction flashvid(). (Voir lmms_eval/models/simple/llava_onevision.py)
👏Remerciements
Ce projet est construit sur des travaux open-source récents : FastV, VisionZip, PruneVID, FastVID, LLaVA-NeXT, Qwen2.5-VL/Qwen3-VL, LMMs-Eval. Merci pour leur excellent travail !
📜Citation
Si vous trouvez ce projet utile dans vos recherches, veuillez envisager de le citer :
@inproceedings{
fan2026flashvid,
title={Flash{VID}: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging},
author={Ziyang Fan and Keyu Chen and Ruilong Xing and Yulin Li and Li Jiang and Zhuotao Tian},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=H6rDX4w6Al}
}⭐️Star History
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-03 ---