FlashVID: Modelos de Lenguaje Grandes para Video Eficientes mediante Fusión de Tokens Espaciotemporales Basada en Árbol sin Entrenamiento
1 Instituto de Tecnología de Harbin (Shenzhen) 2 Universidad China de Hong Kong (Shenzhen)
3 Instituto del Área Loop de Shenzhen
*Autor Correspondiente
🔖Tabla de Contenidos
- Noticias
- Lista de Tareas
- Aspectos Destacados
- Motivación
- Método
- Instalación
- Inicio Rápido
- Evaluación
- Agradecimientos
- Citación
🔥Noticias
- [2026.05.01] 🔍Corrección de un posible error OOM en la extracción manual de atención [CLS] en Qwen2.5-VL y Qwen3-VL.
- [2026.02.10] 🚀Publicación de nuestro artículo en arXiv.
- [2026.02.06] 🍾Nuestro artículo ha sido seleccionado como Presentación Oral en ICLR 2026.
- [2026.02.01] ✨Lanzamiento del código FlashVID y demos de inferencia en Qwen2.5-VL y Qwen3-VL.
- [2026.01.31] 🚀Liberación pública de este repositorio.
- [2026.01.30] ✨Lanzamiento del código FlashVID y demos de inferencia en LLaVA-OneVision y LLaVA-Video.
- [2026.01.30] 👏Inicialización de este repositorio de GitHub.
- [2026.01.26] 🎉Nuestro método de aceleración de inferencia sin entrenamiento FlashVID ha sido aceptado en ICLR 2026.
- [2025.12.06] 🌟Publicación del repositorio GitHub de DyTok.
- [2025.09.18] 🎉 Nuestro marco de aceleración de inferencia sin entrenamiento DyTok ha sido aceptado en NeurIPS 2025.
📋Lista de tareas
- [ ] Optimizar la eficiencia del código
- [x] Publicar código FlashVID en LLaVA-OneVision y LLaVA-Video.
- [x] Publicar demos de inferencia en diferentes Video LLMs con FlashVID.
- [x] Soportar evaluación usando LMMs-Eval.
- [x] Publicar código FlashVID en Qwen2.5-VL y Qwen3-VL.
- [x] Publicar nuestro artículo en arXiv.
✨Aspectos destacados
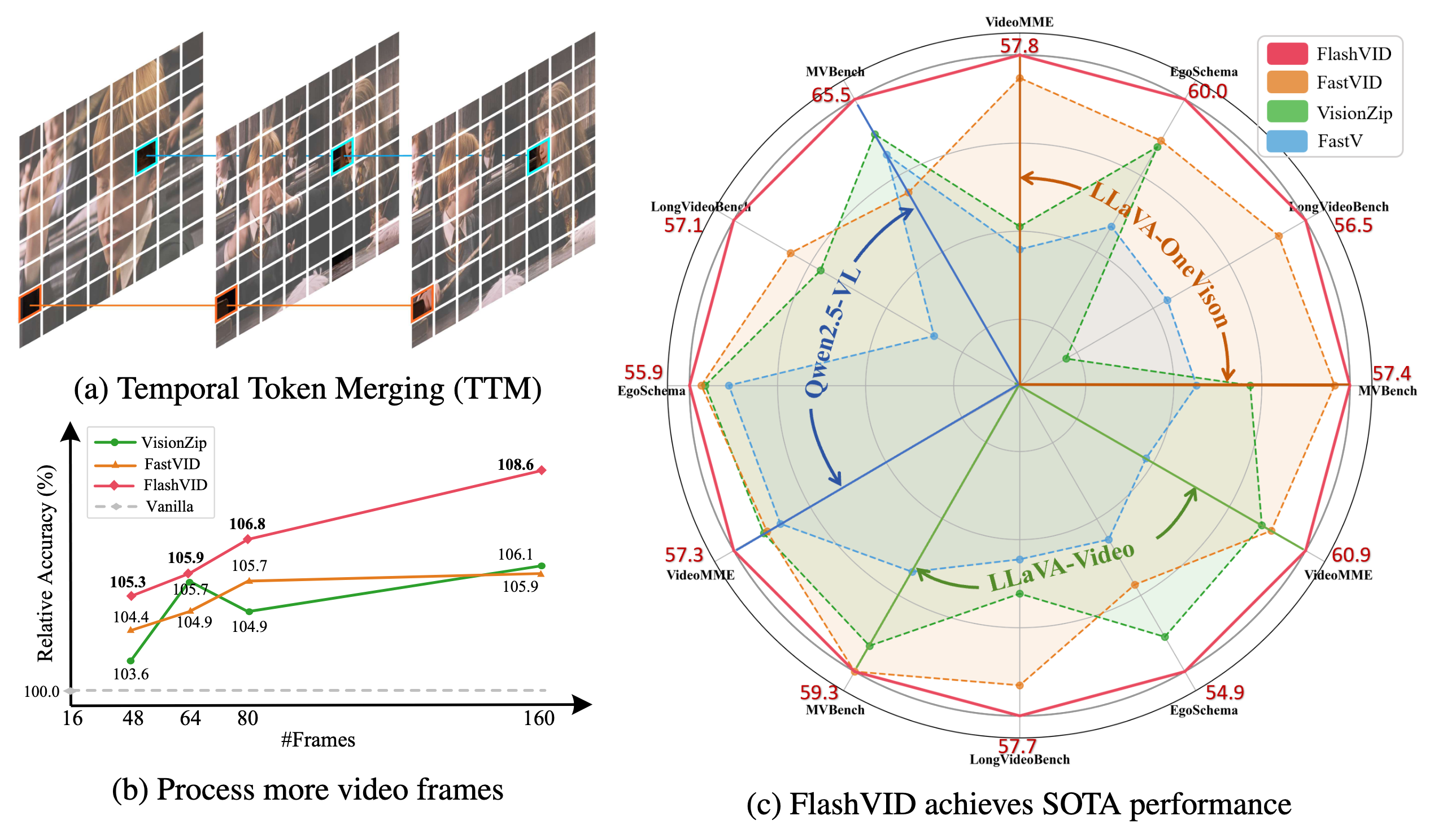
- Nuestro FlashVID supera significativamente a los anteriores marcos de aceleración de última generación (por ejemplo, VisionZip, FastVID) en tres VLLMs representativos (es decir, LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL) en cinco benchmarks ampliamente usados para comprensión de video (es decir, VideoMME, EgoSchema, LongVideoBench, MVBench, MLVU).
- FlashVID puede servir como un módulo plug-and-play y sin necesidad de entrenamiento para extender cuadros de video largos, permitiendo un aumento de 10x en la entrada de cuadros de video a Qwen2.5-VL, resultando en un 8.6% dentro del mismo presupuesto computacional.
- Los métodos existentes eficientes para Video LLM a menudo comprimen de forma independiente la redundancia espacial y temporal, ignorando las relaciones intrínsecas espaciotemporales en videos. Para abordar esto, presentamos una solución simple pero efectiva: Fusión de Tokens Espaciotemporales basada en Árbol (TSTM) para compresión detallada de redundancia espaciotemporal.
💡Motivación
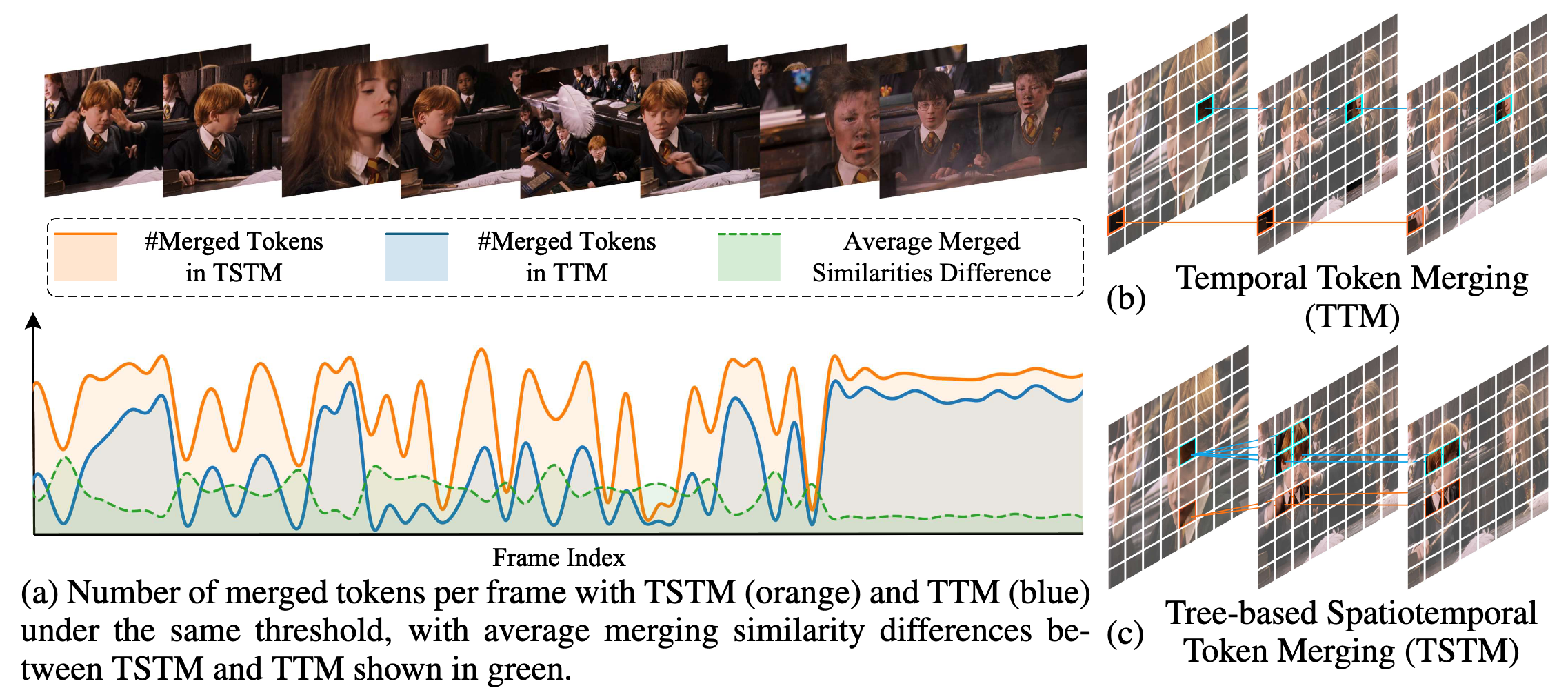
En este trabajo, identificamos dos observaciones clave sobre la redundancia espaciotemporal en videos:
- La redundancia temporal no está ligada a ubicaciones espaciales fijas. Elementos semánticamente consistentes en videos a menudo se desplazan en posición espacial, escala o apariencia debido al movimiento y la dinámica de la escena, haciendo que la correspondencia espacial rígida entre cuadros no sea confiable.
- La redundancia espacial y temporal están intrínsecamente acopladas. Las regiones redundantes dentro de un solo cuadro frecuentemente persisten a través de múltiples cuadros. La compresión desacoplada de la redundancia espaciotemporal ignora las relaciones espaciotemporales intrínsecas, llevando a una compresión subóptima.
🌈Método
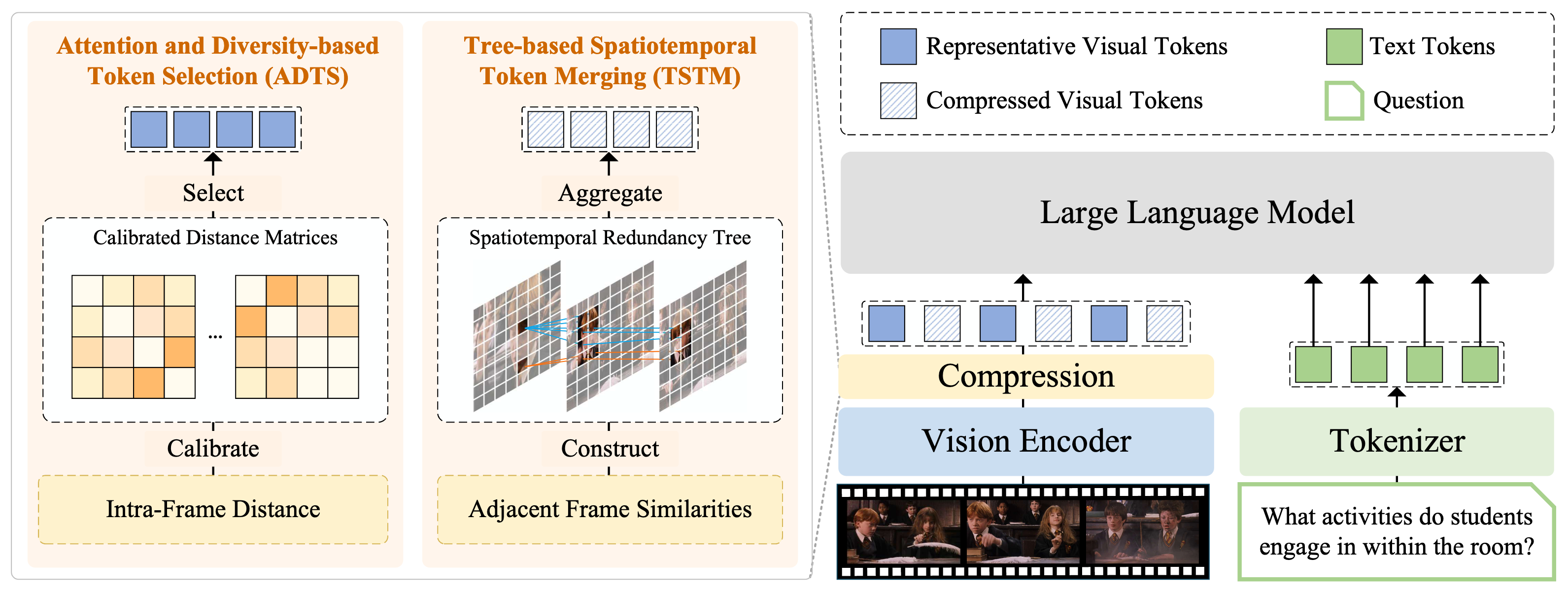
Ilustración de FlashVID. Comprimimos tokens visuales mediante dos módulos sinérgicos.
- Selección de Tokens basada en Atención y Diversidad (ADTS) prioriza tokens informativos espaciotemporales mientras asegura diversidad de características resolviendo un Problema Calibrado de Diversidad Máximo-Mínimo (MMDP);
- Fusión de Tokens Espaciotemporales basada en Árboles (TSTM) modela la redundancia mediante árboles de redundancia espaciotemporal, que capturan efectivamente la dinámica fina del video. Cada árbol de redundancia se agregará en una sola representación de token.
📦Instalación
En este proyecto, usamos uv para la gestión de paquetes.
- Clona este repositorio y navega a la carpeta FlashVID:
git clone https://github.com/Fanziyang-v/FlashVID.git
cd FlashVID- Instale el paquete de inferencia:
uv sync🚀Inicio rápido
El código de FlashVID es fácil de usar y funciona desde el primer momento. Simplemente envuelve el modelo con la función flashvid(). Actualmente, FlashVID soporta LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL y Qwen3-VL.
from flashvid import flashvidmodel = flashvid(
model,
retention_ratio=0.1,
alpha=0.7,
temporal_threshold=0.8,
)
📝Nota: Puedes sobrescribir los parámetros predeterminados (por ejemplo, la tasa de retención) en la función envoltorio flashvid().
Las demostraciones de inferencia se proporcionan en playground/. Aquí hay un ejemplo en ejecución:
python playground/llava_ov_infer.py \
--video-path assets/Qgr4dcsY-60.mp4 \
--question "Describe the video in detail." \
--num-frames 32 \
--enable-flashvid📊Evaluación
En este proyecto, todos los experimentos se realizan utilizando LMMs-Eval. Proporcionamos scripts de evaluación FlashVID en scripts/, incluyendo LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL y Qwen3-VL. Puedes ejecutar los scripts para reproducir nuestros resultados experimentales:
bash scripts/llava_ov.sh📝Nota: Es extremadamente fácil integrar FlashVID en LMMs-Eval añadiendo parámetros específicos en __init__() y envolviendo el modelo cargado con la función flashvid(). (Ver lmms_eval/models/simple/llava_onevision.py)
👏Agradecimientos
Este proyecto se basa en trabajos recientes de código abierto: FastV, VisionZip, PruneVID, FastVID, LLaVA-NeXT, Qwen2.5-VL/Qwen3-VL, LMMs-Eval. ¡Gracias por su excelente trabajo!
📜Citación
Si encuentra este proyecto útil en su investigación, por favor considere citar:
@inproceedings{
fan2026flashvid,
title={Flash{VID}: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging},
author={Ziyang Fan and Keyu Chen and Ruilong Xing and Yulin Li and Li Jiang and Zhuotao Tian},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=H6rDX4w6Al}
}⭐️Star History
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-03 ---