FlashVID: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging
1 Harbin Institute of Technology (Shenzhen) 2 The Chinese University of Hong Kong (Shenzhen)
3 Shenzhen Loop Area Institute
*Corresponding Author
🔖Table of Contents
- News
- Todo List
- Highlights
- Motivation
- Method
- Installation
- Quickstart
- Evaluation
- Acknowledgement
- Citation
🔥News
- [2026.05.01] 🔍Fix a potential OOM bug in manual [CLS] attention extraction in Qwen2.5-VL and Qwen3-VL.
- [2026.02.10] 🚀Release our paper on arXiv.
- [2026.02.06] 🍾Our paper has been selected as an Oral Presentation at ICLR 2026.
- [2026.02.01] ✨Release FlashVID code and inference demos on Qwen2.5-VL and Qwen3-VL.
- [2026.01.31] 🚀Release this repository to the public.
- [2026.01.30] ✨Release FlashVID code and inference demos on LLaVA-OneVision and LLaVA-Video.
- [2026.01.30] 👏Initialize this GitHub repository.
- [2026.01.26] 🎉Our training-free inference acceleration method FlashVID has been accepted at ICLR 2026.
- [2025.12.06] 🌟Release the GitHub repository of DyTok.
- [2025.09.18] 🎉 Our training-free inference acceleration framework DyTok has been accepted at NeurIPS 2025.
📋Todo List
- [ ] Optimize code efficiency
- [x] Release FlashVID code on LLaVA-OneVision and LLaVA-Video.
- [x] Release inference demos on different Video LLMs with FlashVID.
- [x] Support evaluation using LMMs-Eval.
- [x] Release FlashVID code on Qwen2.5-VL and Qwen3-VL.
- [x] Release our paper on arXiv.
✨Highlights
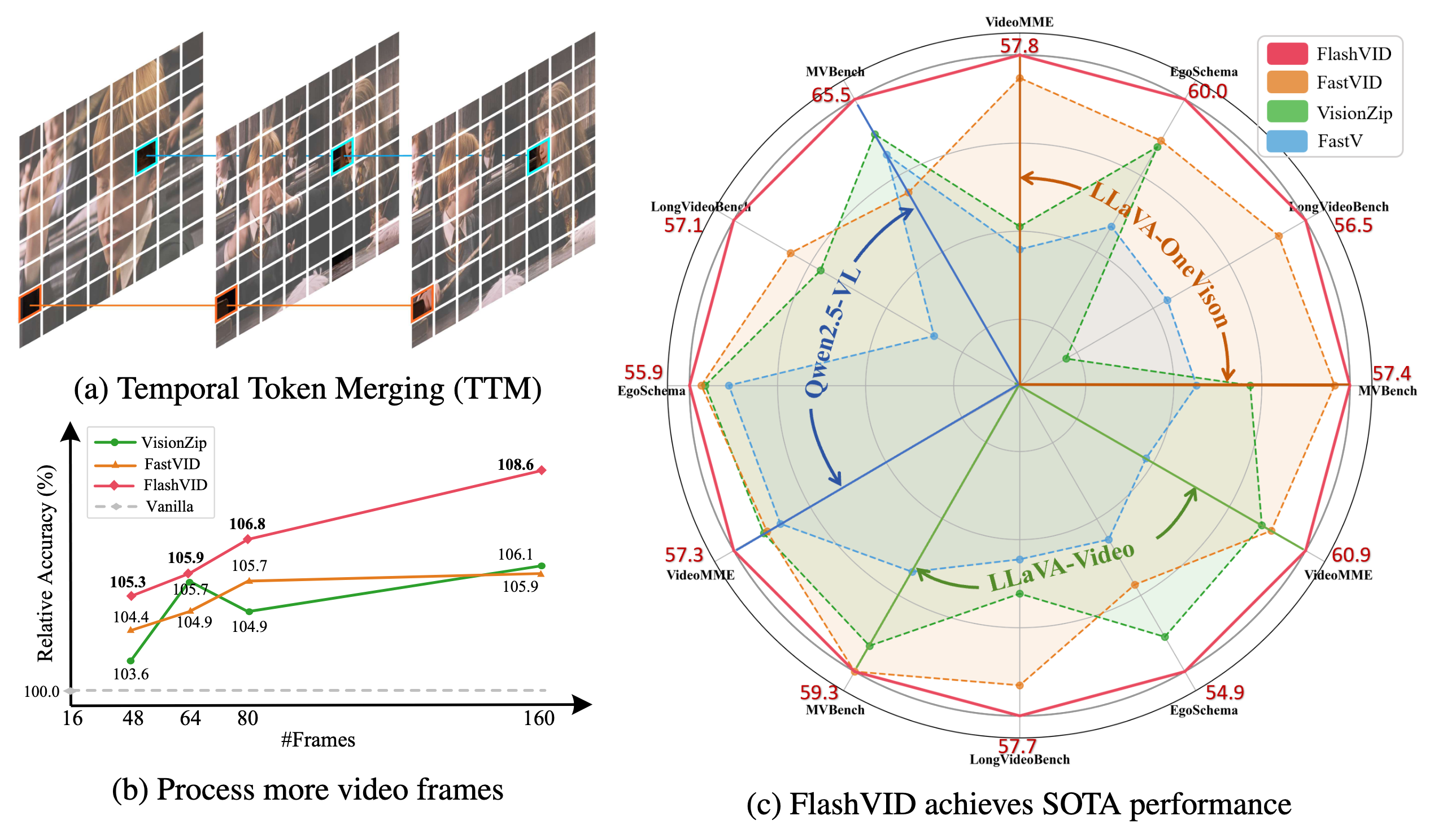
- Our FlashVID significantly outperforms previous state-of-the-art acceleration frameworks (e.g., VisionZip, FastVID) across three representative VLLMs (i.e., LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL) on five widely used video understanding benchmarks (i.e., VideoMME, EgoSchema, LongVideoBench, MVBench, MLVU).
- FlashVID can serve as a training-free and plug-and-play module for extending long video frames, enabling a 10x increase in video frame input to Qwen2.5-VL, resulting in 8.6% within the same computational budget.
- Existing efficient Video LLM methods often independently compress spatial and temporal redundancy, overlooking the intrinsic spatiotemporal relationships in videos. To address this, we present a simple yet effective solution: Tree-based Spatiotemporal Token Merging (TSTM) for fine-grained spatiotemporal redundancy compression.
💡Motivation
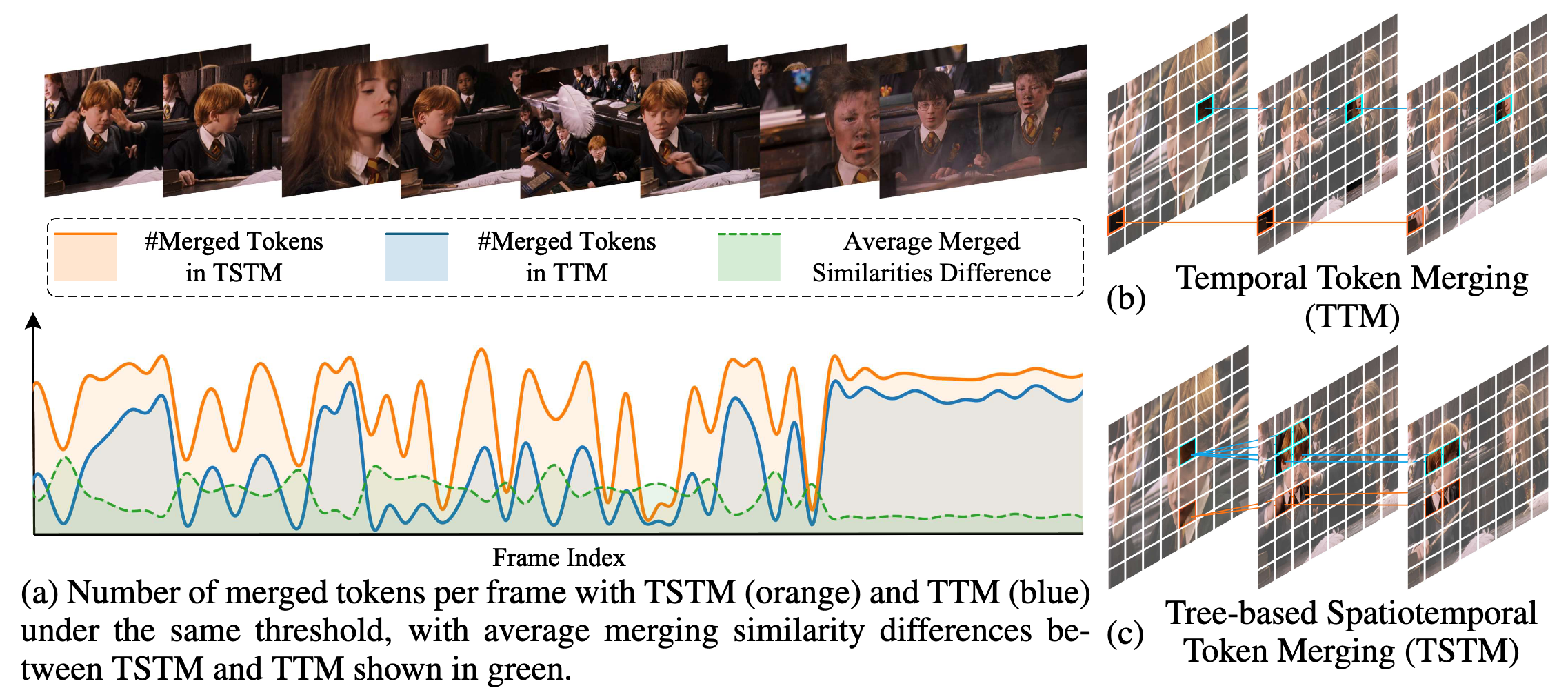
In this work, we identify two key observations about spatiotemporal redundancy in videos:
- Temporal redundancy is not bound to fixed spatial locations. Semantically consistent elements in videos often shift in spatial position, scale, or appearance due to motion and scene dynamics, making rigid spatial correspondence across frames unreliable
- Spatial and temporal redundancy are inherently coupled. Redundant regions within a single frame frequently persist across multiple frames. Decoupled spatiotemporal redundancy compression overlooks the intrinsic spatiotemporal relationships, leading to suboptimal compression.
🌈Method
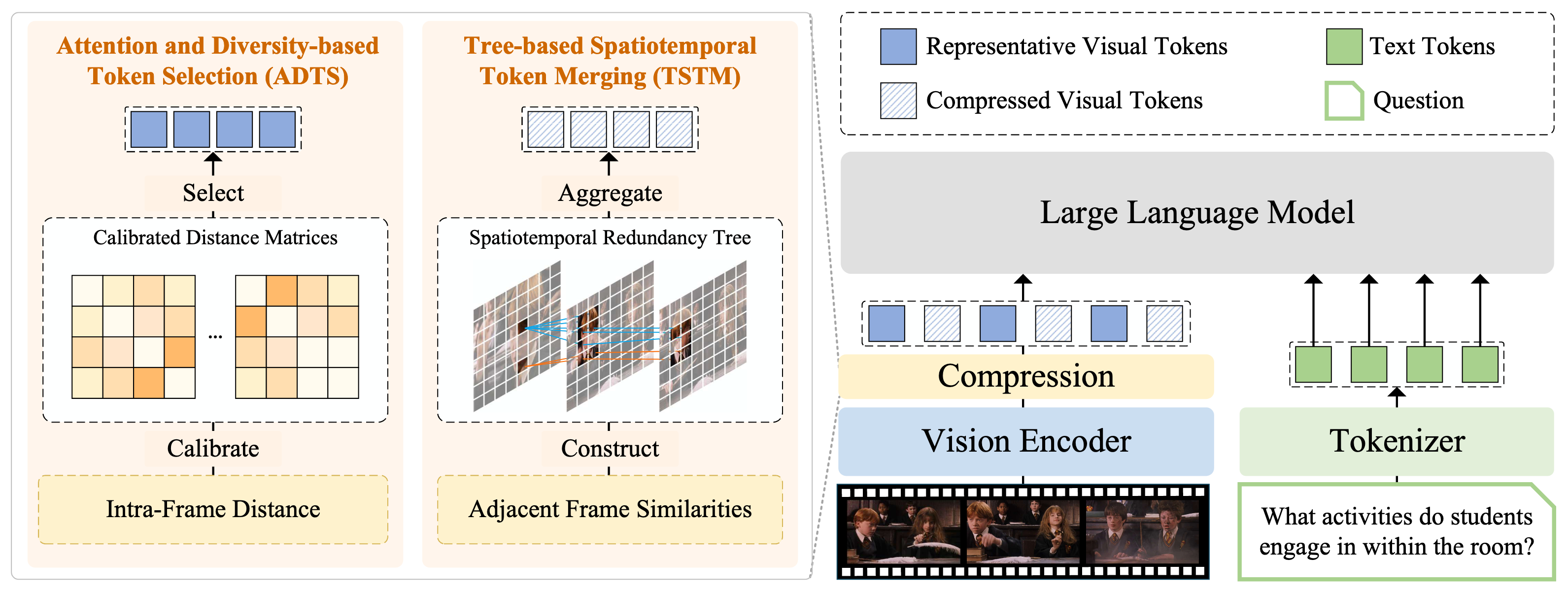
Illustration of FlashVID. We compress visual tokens by two synergistic modules.
- Attention and Diversity-based Token Selection (ADTS) prioritizes spatiotemporally informative tokens while ensuring feature diversity by solving a calibrated Max-Min Diversity Problem (MMDP);
- Tree-based Spatiotemporal Token Merging (TSTM) models redundancy by spatiotemporal redundancy trees, which effectively capture fine-grained video dynamics. Each redundancy tree will be aggregated into a single token representation.
📦Installation
In this project, we use uv for package management.
- Clone this repository and navigate to the FlashVID folder:
git clone https://github.com/Fanziyang-v/FlashVID.git
cd FlashVID- Install the inference package:
uv sync🚀Quickstart
FlashVID's code is easy to use and works out of the box. Just wrap the model with the flashvid() function. Currently, FlashVID supports LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL, and Qwen3-VL.
from flashvid import flashvidmodel = flashvid(
model,
retention_ratio=0.1,
alpha=0.7,
temporal_threshold=0.8,
)
📝Note: You can override the default parameters (e.g., retention ratio) in the flashvid() wrapper function.
Inference demos are provided in playground/. Here is a running example:
python playground/llava_ov_infer.py \
--video-path assets/Qgr4dcsY-60.mp4 \
--question "Describe the video in detail." \
--num-frames 32 \
--enable-flashvid📊Evaluation
In this project, all the experiments are conducted using LMMs-Eval. We provide FlashVID evaluation scripts in scripts/, including LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL, and Qwen3-VL. You can run the scripts to reproduce our experimental results:
bash scripts/llava_ov.sh📝Note: It is extremely easy to integrate FlashVID into LMMs-Eval by adding specific parameters in __init__() and wrapping the loaded model with the flashvid() function. (See lmms_eval/models/simple/llava_onevision.py)
👏Acknowledgement
This project is built upon recent open-source works: FastV, VisionZip, PruneVID, FastVID, LLaVA-NeXT, Qwen2.5-VL/Qwen3-VL, LMMs-Eval. Thanks for their excellent work!
📜Citation
If you find this project useful in your research, please consider citing:
@inproceedings{
fan2026flashvid,
title={Flash{VID}: Efficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merging},
author={Ziyang Fan and Keyu Chen and Ruilong Xing and Yulin Li and Li Jiang and Zhuotao Tian},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=H6rDX4w6Al}
}⭐️Star History
--- Tranlated By Open Ai Tx | Last indexed: 2026-07-03 ---