go-torch
go-torch es un framework de aprendizaje profundo de código abierto construido desde cero en puro Go. Proporciona una API modular, similar a PyTorch, para construir y entrenar redes neuronales con un motor de auto-diferenciación estable.
correo - abineshmathivanan31@gmail.com
blog - https://abinesh-mathivanan.vercel.app/en/posts/post-5/
características
- grafo de computación dinámico: los tensores rastrean su historial, permitiendo el cálculo automático de gradientes durante el paso hacia atrás.
- sistema de módulos extensible (nn.Layer, nn.Sequential): construye arquitecturas de modelos complejos con una API secuencial flexible, similar a Keras.
- biblioteca de capas y funciones: incluye Conv2D, Linear, MaxPooling2D, Flatten, ReLU, CrossEntropyLoss y SGD
- panel TUI en tiempo real: gráficos en vivo para la pérdida por lote y la precisión de validación por época, monitoreo del uso de memoria (Heap/Total Alloc), ciclos de GC y goroutines activas junto con resumen tipo keras.
- rendimiento optimizado: usando BLAS, go-routines y autograd topológico + acumulación de gradientes
Panel TUI
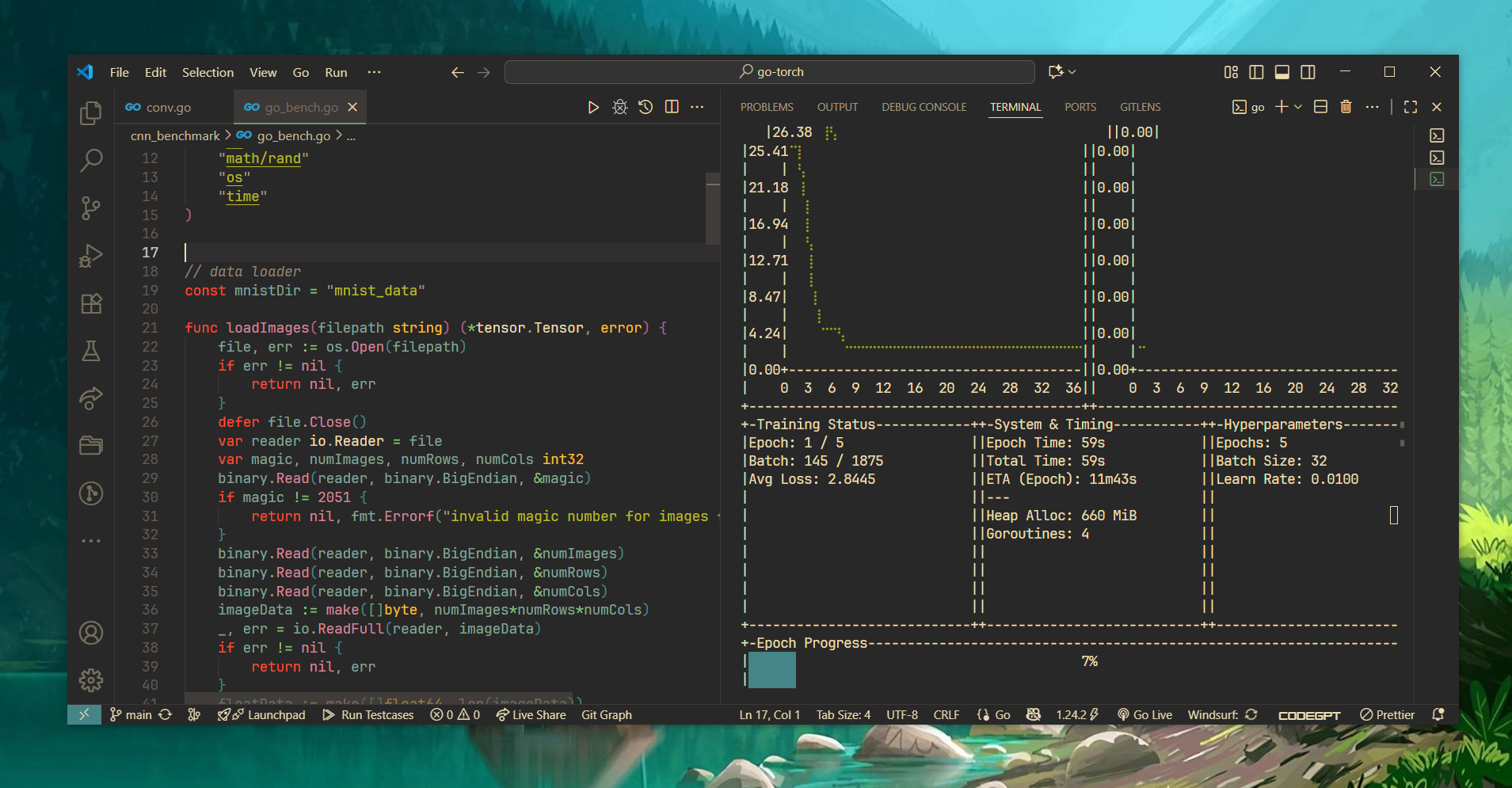
PENDIENTES
- [ ] añadir soporte para RNN, LSTM, Transformers
- [ ] implementar Adam con técnicas Ga-lore y LORA, RMSProp etc...
- [ ] model.load() y model.save() sin gob
- [ ] soporte para construir Transformers
requisitos previos
- Go 1.18 o superior.
- se recomienda una biblioteca BLAS instalada en el sistema para máximo rendimiento, pero no es obligatoria.
- algunos pendientes están escritos dentro de los archivos. usa la extensión 'better comments' para mejor experiencia.
uso
clonar el repositorio
git clone https://github.com/abinesh-mathivanan/go-torch.git
cd go-torchinstalar dependencias
`` bash
go mod tidy
ejecutar
ejecuta el archivo de entrenamiento mnist para probar las funciones.
bash
go run ./cnn_benchmark/go_bench.go
``Benchmark
| Detalle del Benchmark | 128x128 | 512x512 | 1024x1024 | |:----------------------------------------|:-------------|:------------|:-------------| | Multiplicación de Matrices | 510.33 µs | 13.54 ms | 130.50 ms | | Suma Elemento a Elemento | 71.72 µs | 1.29 ms | 4.13 ms | | Multiplicación Elemento a Elemento | 47.83 µs | 1.63 ms | 3.91 ms | | Activación ReLU | 121.18 µs | 1.75 ms | 6.45 ms | | Capa Lineal Adelante (B32,I128,O10) | 71.93 µs | | | | CrossEntropyLoss (B32,C10) | 11.16 µs | | | | Total Adelante-Atrás (Red:128-256-10, B32) | 4.02 ms | | |
--- Tranlated By Open Ai Tx | Last indexed: 2025-12-26 ---