go-torch
go-torch is an open-source deep learning framework built from the ground up in pure Go. It provides a modular, PyTorch-like API for building and training neural networks with a stable auto-differentiation engine.
mail - abineshmathivanan31@gmail.com
blog - https://abinesh-mathivanan.vercel.app/en/posts/post-5/
features
- dynamic computation graph: tensors track their history, allowing for automatic gradient calculation during the backward pass.
- extensible module system (nn.Layer, nn.Sequential): build complex model architectures with a flexible, Keras-like sequential API.
- layer and function library: includes Conv2D, Linear, MaxPooling2D, Flatten, ReLU, CrossEntropyLoss, and SGD
- real-time TUI dashboard: live graphs for batch-wise loss and epoch-wise validation accuracy, monitoring of memory usage (Heap/Total Alloc), GC cycles, and active goroutines along with keras-like summary.
- optimized performance: using BLAS, go-routines and topological autograd + grad accumulation
TUI Dashboard
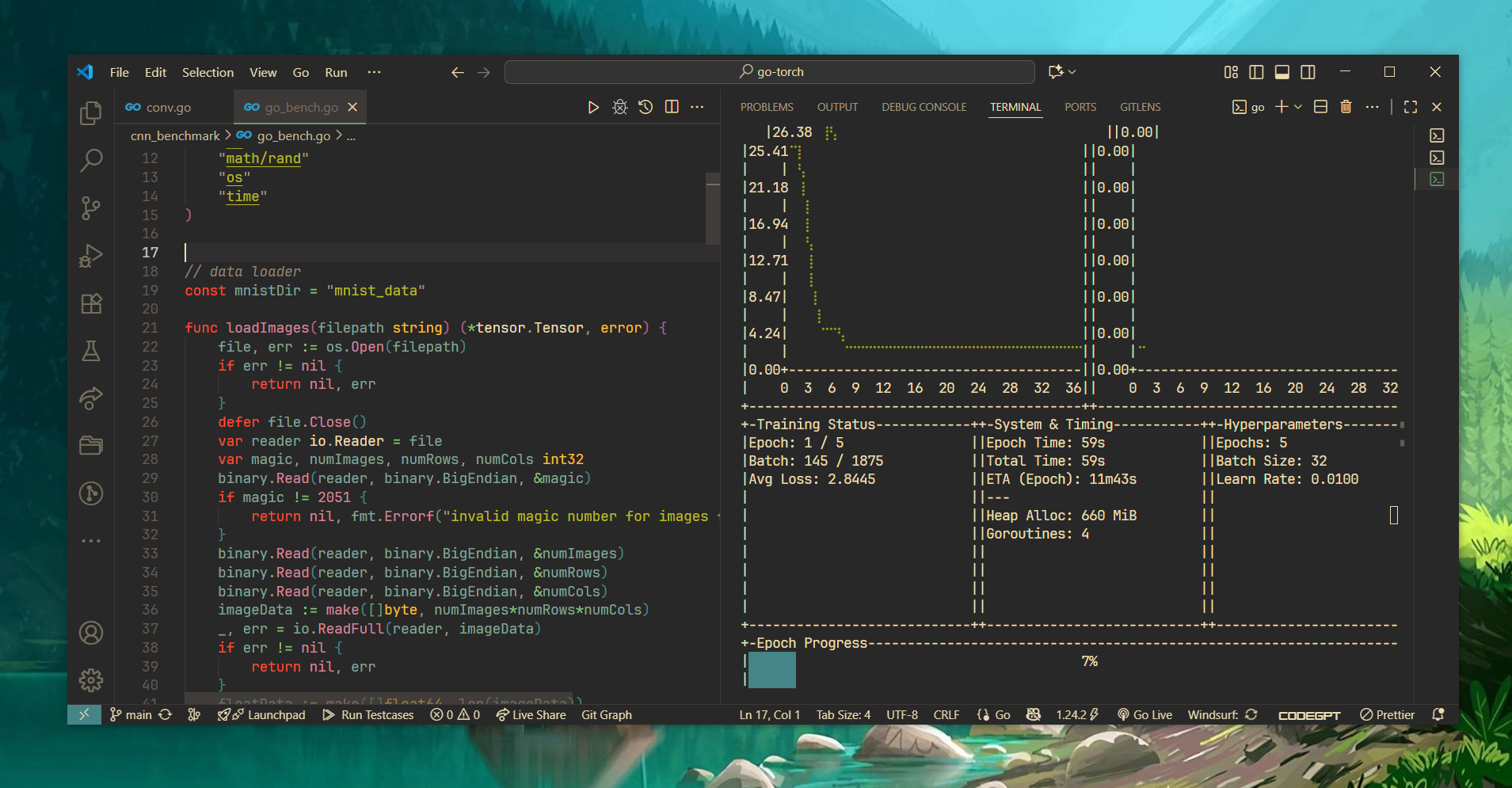
TODO
- [ ] add support for RNN, LSTM, Transformers
- [ ] implement Adam with Ga-lore and LORA techniques, RMSProp etc...
- [ ] model.load() and model.save() without gob
- [ ] support building Transformers
pre-requisites
- Go 1.18 or later.
- system-installed BLAS library is recommended for maximum performance but not required.
- some todo's are written inside the files. use 'better comments' extension for best experience.
usage
clone the repository
git clone https://github.com/abinesh-mathivanan/go-torch.git
cd go-torchinstall dependencies
`` bash
go mod tidy
execute
run the mnist training file to test out the features.
bash
go run ./cnn_benchmark/go_bench.go
``Benchmark
| Benchmark Detail | 128x128 | 512x512 | 1024x1024 | |:------------------------------------------|:-------------|:------------|:-------------| | Matrix Multiply | 510.33 µs | 13.54 ms | 130.50 ms | | Element-wise Add | 71.72 µs | 1.29 ms | 4.13 ms | | Element-wise Mul | 47.83 µs | 1.63 ms | 3.91 ms | | ReLU Activation | 121.18 µs | 1.75 ms | 6.45 ms | | Linear Layer Forward (B32,I128,O10) | 71.93 µs | | | | CrossEntropyLoss (B32,C10) | 11.16 µs | | | | Full Fwd-Bwd (Net:128-256-10, B32) | 4.02 ms | | |
--- Tranlated By Open Ai Tx | Last indexed: 2025-12-26 ---